ในการฝึกอบรมโมเดลภาษาขนาดใหญ่ (LLM) กลไกจุดตรวจสอบมีความสำคัญ เนื่องจากสามารถหลีกเลี่ยงการสูญเสียครั้งใหญ่ที่เกิดจากการหยุดชะงักของการฝึกอบรมได้อย่างมีประสิทธิภาพ อย่างไรก็ตาม ระบบจุดตรวจสอบแบบเดิมมักประสบปัญหาคอขวดของ I/O และไม่มีประสิทธิภาพ ด้วยเหตุนี้ นักวิทยาศาสตร์จาก ByteDance และมหาวิทยาลัยฮ่องกงจึงได้เสนอระบบจุดตรวจใหม่ที่เรียกว่า ByteCheckpoint ซึ่งสามารถปรับปรุงประสิทธิภาพของการฝึกอบรม LLM ได้อย่างมาก
ในโลกดิจิทัลที่ถูกครอบงำด้วยข้อมูลและอัลกอริธึม ทุกขั้นตอนของการเติบโตของปัญญาประดิษฐ์นั้นแยกออกจากองค์ประกอบสำคัญไม่ได้ นั่นก็คือจุดตรวจสอบ ลองนึกภาพว่าเมื่อคุณฝึกอบรมโมเดลภาษาขนาดใหญ่ที่สามารถเข้าใจจิตใจของผู้คนและตอบคำถามได้อย่างคล่องแคล่ว โมเดลนี้ฉลาดอย่างยิ่ง แต่ก็กินปริมาณมากและต้องใช้ทรัพยากรคอมพิวเตอร์จำนวนมากเพื่อป้อนเข้า ในระหว่างกระบวนการฝึกอบรม หากเกิดไฟฟ้าดับกะทันหันหรือฮาร์ดแวร์ขัดข้อง การสูญเสียจะมีขนาดใหญ่ ณ เวลานี้ จุดตรวจเปรียบเสมือนไทม์แมชชีนที่ปล่อยให้ทุกอย่างกลับสู่สภาวะปลอดภัยเดิมและทำงานที่ยังทำไม่เสร็จต่อไป
อย่างไรก็ตาม ตัวไทม์แมชชีนเองก็จำเป็นต้องมีการออกแบบอย่างระมัดระวังเช่นกัน นักวิทยาศาสตร์จาก ByteDance และมหาวิทยาลัยฮ่องกงได้นำเสนอระบบจุดตรวจใหม่ - ByteCheckpoint ในรายงานเรื่อง "ByteCheckpoint: A Unified Checkpointing System for LLM Development" มันไม่ได้เป็นเพียงเครื่องมือสำรองข้อมูลธรรมดาเท่านั้น แต่ยังเป็นสิ่งประดิษฐ์ที่สามารถปรับปรุงประสิทธิภาพการฝึกอบรมของโมเดลภาษาขนาดใหญ่ได้อย่างมาก
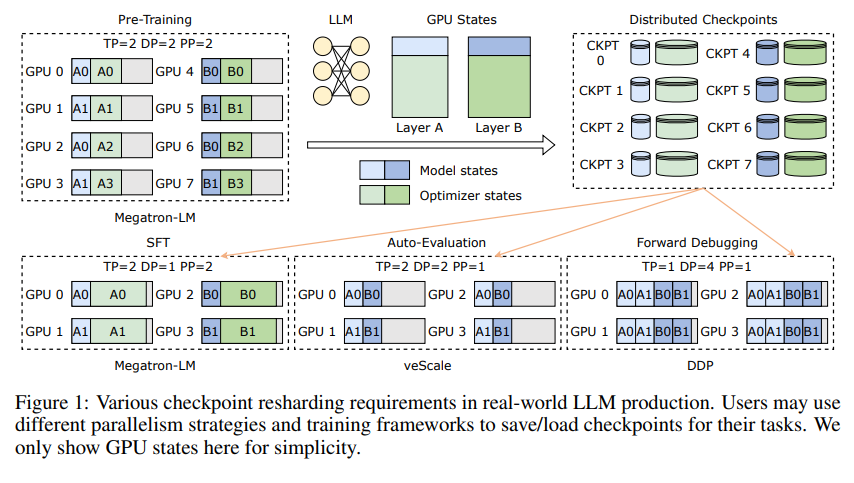
อันดับแรก เราต้องเข้าใจความท้าทายที่โมเดลภาษาขนาดใหญ่ (LLM) เผชิญ เหตุผลที่โมเดลเหล่านี้มีขนาดใหญ่ก็คือ จำเป็นต้องประมวลผลและจดจำข้อมูลจำนวนมหาศาล ซึ่งนำมาซึ่งปัญหาต่างๆ เช่น ค่าใช้จ่ายในการฝึกอบรมที่สูง การใช้ทรัพยากรจำนวนมาก และความทนทานต่อข้อผิดพลาดต่ำ เมื่อเกิดความผิดปกติขึ้น อาจทำให้การฝึกอบรมเป็นระยะเวลานานไม่เป็นที่น่าพอใจ
ระบบจุดตรวจเปรียบเสมือนภาพรวมของแบบจำลอง บันทึกสถานะอย่างสม่ำเสมอในระหว่างกระบวนการฝึกอบรม ดังนั้นแม้ว่าจะมีข้อผิดพลาดเกิดขึ้น ก็สามารถกู้คืนสู่สถานะล่าสุดได้อย่างรวดเร็วและลดการสูญเสีย อย่างไรก็ตาม ระบบจุดตรวจสอบที่มีอยู่มักจะประสบกับความไร้ประสิทธิภาพเนื่องจากปัญหาคอขวดของ I/O (อินพุต/เอาต์พุต) เมื่อประมวลผลโมเดลขนาดใหญ่
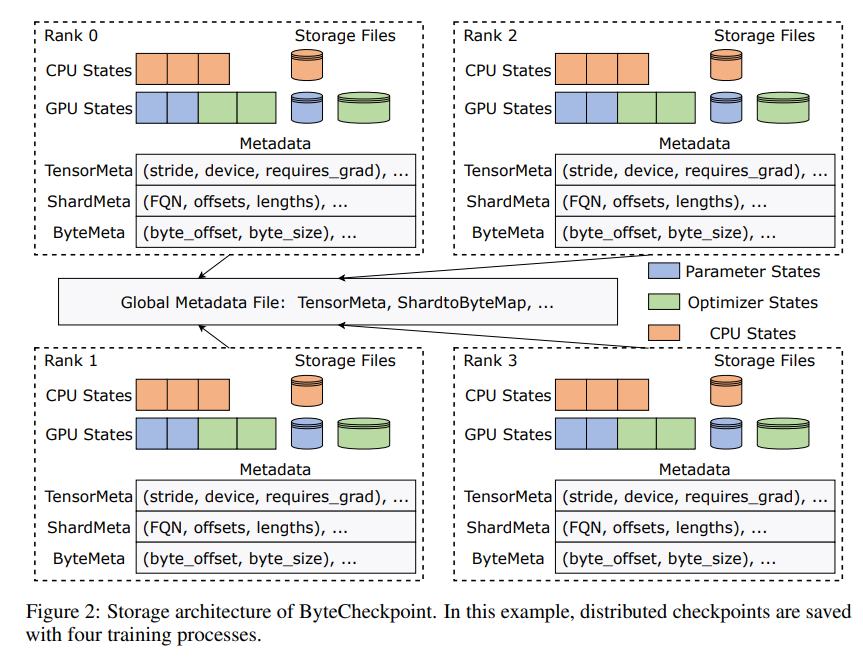
นวัตกรรมของ ByteCheckpoint อยู่ที่การใช้สถาปัตยกรรมการจัดเก็บข้อมูลแบบใหม่ที่แยกข้อมูลและข้อมูลเมตา และจัดการจุดตรวจสอบได้อย่างยืดหยุ่นมากขึ้นภายใต้การกำหนดค่าแบบขนานและเฟรมเวิร์กการฝึกอบรมที่แตกต่างกัน ยิ่งไปกว่านั้น ยังรองรับการแบ่งส่วนจุดตรวจสอบออนไลน์อัตโนมัติ ซึ่งสามารถปรับจุดตรวจสอบแบบไดนามิกเพื่อปรับให้เข้ากับสภาพแวดล้อมฮาร์ดแวร์ที่แตกต่างกันโดยไม่รบกวนการฝึกอบรม
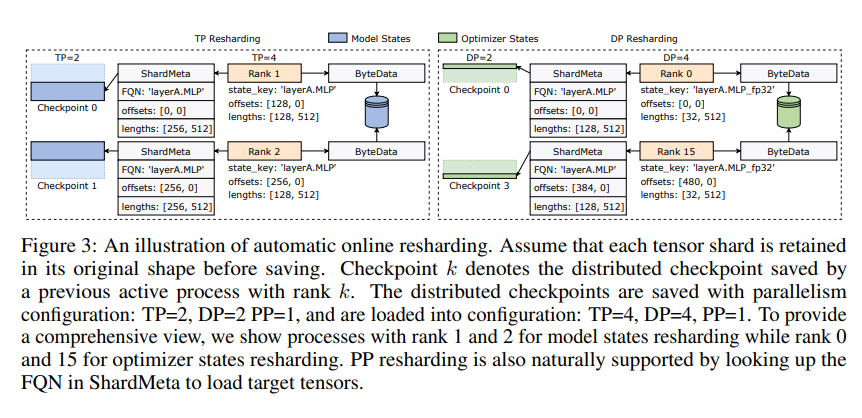
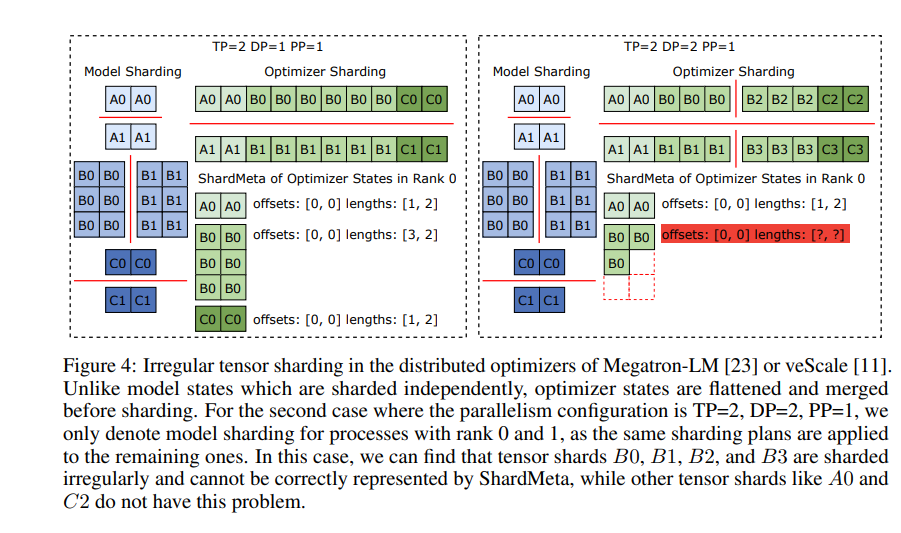
ByteCheckpoint ยังแนะนำเทคโนโลยีหลัก - การรวมเทนเซอร์แบบอะซิงโครนัส สิ่งนี้สามารถจัดการเทนเซอร์ที่กระจายอย่างไม่สม่ำเสมอบน GPU ที่แตกต่างกันได้อย่างมีประสิทธิภาพ ทำให้มั่นใจได้ว่าความสมบูรณ์และความสม่ำเสมอของโมเดลจะไม่ได้รับผลกระทบเมื่อมีการแบ่งจุดตรวจสอบใหม่
เพื่อที่จะปรับปรุงความเร็วของการบันทึกและการโหลดจุดตรวจสอบ ByteCheckpoint ยังรวมชุดมาตรการเพิ่มประสิทธิภาพ I/O ไว้ด้วย เช่น ไปป์ไลน์การบันทึก/โหลดที่ซับซ้อน พูลหน่วยความจำ Ping-Pong การบันทึกสมดุลเวิร์กโหลด และโหลดที่ซ้ำซ้อนเป็นศูนย์ ฯลฯ ซึ่งช่วยลดระยะเวลารอคอยในระหว่างกระบวนการฝึกอบรมได้อย่างมาก
ด้วยการตรวจสอบเชิงทดลอง เมื่อเปรียบเทียบกับวิธีการแบบเดิม ความเร็วในการบันทึกและโหลดจุดตรวจสอบของ ByteCheckpoint จะเพิ่มขึ้นหลายสิบหรือหลายร้อยเท่าตามลำดับ ซึ่งช่วยปรับปรุงประสิทธิภาพการฝึกอบรมโมเดลภาษาขนาดใหญ่ได้อย่างมาก
ByteCheckpoint ไม่เพียงแต่เป็นระบบจุดตรวจเท่านั้น แต่ยังเป็นผู้ช่วยเหลือที่ทรงพลังในกระบวนการฝึกอบรมโมเดลภาษาขนาดใหญ่อีกด้วย มันเป็นกุญแจสำคัญในการฝึกอบรม AI ที่มีประสิทธิภาพและมีเสถียรภาพมากขึ้น
ที่อยู่กระดาษ: https://arxiv.org/pdf/2407.20143
บรรณาธิการของ Downcodes สรุป: การเกิดขึ้นของ ByteCheckpoint ช่วยแก้ปัญหาประสิทธิภาพจุดตรวจสอบต่ำในการฝึกอบรม LLM และให้การสนับสนุนทางเทคนิคที่แข็งแกร่งสำหรับการพัฒนา AI คุ้มค่าที่จะให้ความสนใจ!