โปรแกรมแก้ไข Downcodes จะพาคุณผ่านการทดลอง AI ที่น่าสนใจ: ผู้ใช้ Reddit @zefman ได้สร้างแพลตฟอร์มเพื่อให้โมเดลภาษาต่างๆ (LLM) เล่นหมากรุกแบบเรียลไทม์! การทดลองนี้เป็นการประเมินความสามารถของ LLM ในการเล่นหมากรุกด้วยวิธีที่ผ่อนคลายและน่าสนใจ ผลลัพธ์ที่ได้นั้นเป็นสิ่งที่คาดไม่ถึง มาดูกัน!
เมื่อเร็วๆ นี้ ผู้ใช้ Reddit @zefman ได้ทำการทดลองที่น่าสนใจ โดยสร้างแพลตฟอร์มเพื่อเจาะลึกโมเดลภาษาต่างๆ (LLM) กับหมากรุกแบบเรียลไทม์ โดยมีเป้าหมายเพื่อให้ผู้ใช้มีวิธีที่สนุกและง่ายดายในการประเมินประสิทธิภาพของโมเดลเหล่านี้
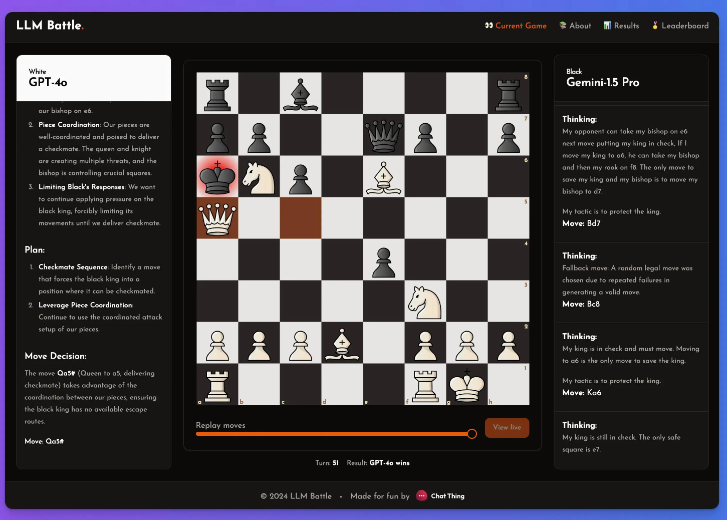
ไม่ใช่ความลับที่โมเดลเหล่านี้เล่นหมากรุกไม่เก่ง แต่ถึงกระนั้น เขาก็ยังรู้สึกว่ามีจุดเด่นบางอย่างในการทดลองนี้
ในการทดลองนี้ @zefman ให้ความสนใจเป็นพิเศษกับโมเดลล่าสุดหลายรุ่น โดยที่ GPT-4o ทำได้โดดเด่นที่สุดและกลายเป็นผู้เล่นที่แข็งแกร่งที่สุดอย่างไม่ต้องสงสัย ขณะเดียวกัน @zefman ยังได้เปรียบเทียบกับรุ่นอื่นๆ เช่น Claude และ Gemini เพื่อสังเกตความแตกต่างด้านประสิทธิภาพ และพบว่ากระบวนการคิดและการใช้เหตุผลของแต่ละรุ่นน่าสนใจมาก ผ่านแพลตฟอร์มนี้ ทุกคนสามารถเห็นเบื้องหลังการตัดสินใจของแต่ละขั้นตอน และวิธีที่แบบจำลองวิเคราะห์เกมหมากรุก
วิธีการแสดงเกมหมากรุกที่ออกแบบโดย @zefman นั้นค่อนข้างง่าย เมื่อแต่ละโมเดลเผชิญกับสถานะกระดานหมากรุกเดียวกัน มันจะให้คำสั่งเดียวกัน รวมถึงสถานะเกมหมากรุกในปัจจุบัน FEN (การแสดงตำแหน่งหมากรุก) และการเคลื่อนไหวสองครั้งก่อนหน้า แนวทางนี้ช่วยให้มั่นใจได้ว่าการตัดสินใจของแต่ละรุ่นจะขึ้นอยู่กับข้อมูลเดียวกัน ช่วยให้เปรียบเทียบได้อย่างยุติธรรมยิ่งขึ้น
แต่ละรุ่นใช้ข้อความแจ้งที่เหมือนกันทุกประการ ซึ่งจะอัปเดตด้วยสถานะของบอร์ดใน ASCI, FEN และการเคลื่อนไหวและความคิดสองรายการก่อนหน้านี้ นี่คือตัวอย่าง:
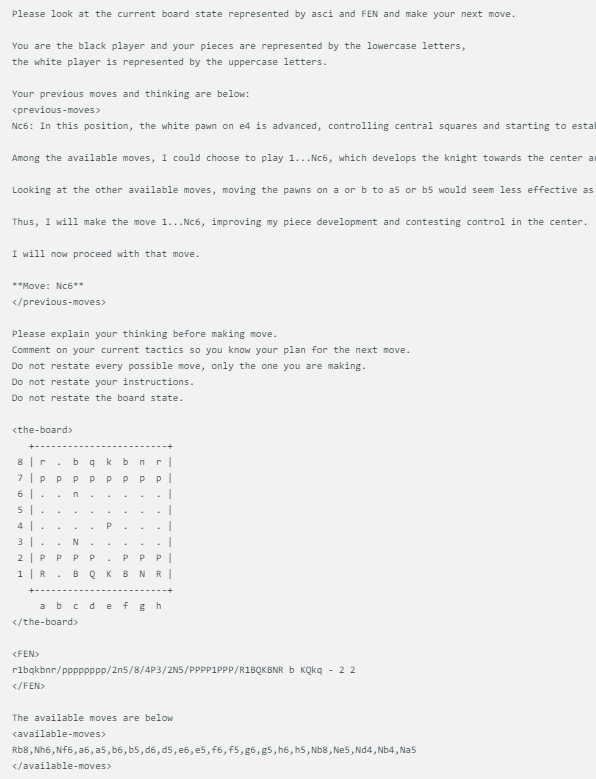
นอกจากนี้ @zefman ยังสังเกตเห็นว่าในบางกรณี โดยเฉพาะรุ่นที่อ่อนแอกว่าบางรุ่น พวกเขาอาจเลือกการเคลื่อนไหวผิดหลายครั้ง เพื่อแก้ปัญหานี้ เขาให้โอกาสโมเดลเหล่านี้ 5 ครั้งในการเลือกใหม่ หากพวกเขายังคงล้มเหลวในการเลือกท่าที่ถูกต้อง พวกเขาจะสุ่มเลือกท่าที่ถูกต้อง ซึ่งจะทำให้เกมดำเนินต่อไป
เขาสรุป: GTP-4o ยังคงแข็งแกร่งที่สุด โดยเอาชนะ Gemini1.5pro ในหมากรุก
จากการทดลองนี้ เราไม่เพียงเห็นความแตกต่างระหว่าง LLM ต่างๆ ในสาขาหมากรุกเท่านั้น แต่ยังเห็นการออกแบบอันชาญฉลาดและจิตวิญญาณแห่งการทดลองของ @zefman อีกด้วย รอคอยที่จะมีการทดลองที่คล้ายกันมากขึ้นในอนาคต ซึ่งจะทำให้เราเข้าใจถึงศักยภาพและข้อจำกัดของ LLM อย่างลึกซึ้งยิ่งขึ้น!