บรรณาธิการของ Downcodes ขอนำเสนอข่าวใหญ่ของ MiniCPM-V2.6! โมเดลปัญญาประดิษฐ์หลายรูปแบบด้านท้ายที่มีพารามิเตอร์เพียง 8B นี้ได้รับผลลัพธ์ SOTA ของโมเดลที่ต่ำกว่า 20B ในสามด้านของการทำความเข้าใจภาพเดียว หลายภาพ และวิดีโอ เรียกได้ว่าเป็นปาฏิหาริย์ของโมเดลขนาดเล็ก! ไม่เพียงแต่มีประสิทธิภาพที่แข็งแกร่งเท่านั้น แต่ยังได้รับประสิทธิภาพการทำงานที่สูงมากและความเป็นมิตรบนอุปกรณ์ปลายทาง ซึ่งนำความเป็นไปได้ใหม่ๆ มาสู่แอปพลิเคชัน AI ปลายทาง แม้จะเทียบได้กับ GPT-4V เรามาเจาะลึกฟังก์ชันและคุณลักษณะอันทรงพลังของ MiniCPM-V2.6 กันดีกว่า
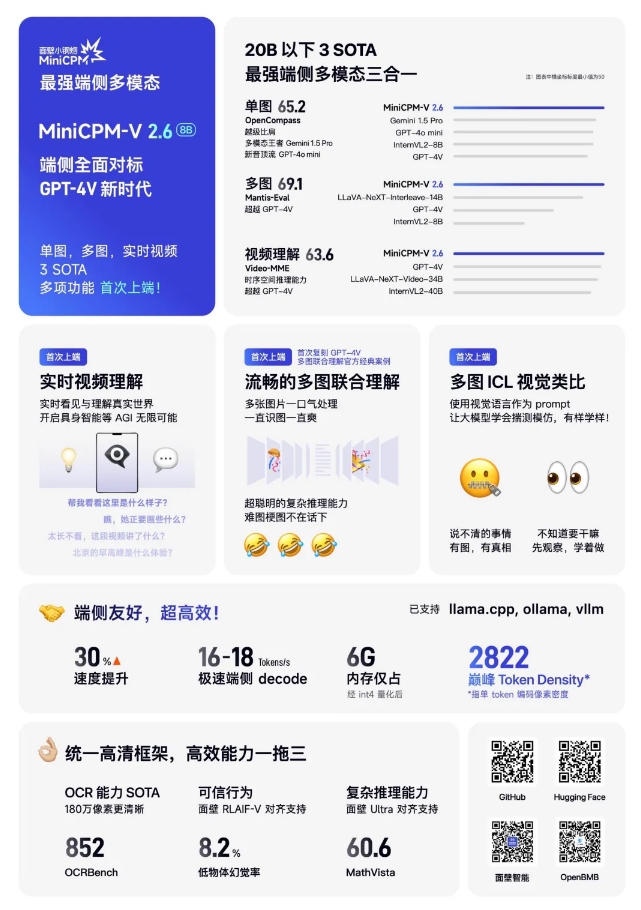
โมเดลปัญญาประดิษฐ์หลายรูปแบบปลายทางของ MiniCPM-V2.6 มีพารามิเตอร์เพียง 8B แต่ได้ผลลัพธ์ SOTA (State of the Art ซึ่งเป็นระดับที่ดีที่สุดในปัจจุบัน) สามรายการจากความเข้าใจภาพเดี่ยว หลายภาพ และวิดีโอที่ต่ำกว่า 20B - ความสามารถด้านกิริยาของ AI ฝั่งท้ายได้รับการปรับปรุงอย่างมีนัยสำคัญ และสอดคล้องกับระดับ GPT-4V อย่างสมบูรณ์
ต่อไปนี้เป็นสรุปคุณสมบัติ:
คุณสมบัติของโมเดล: MiniCPM-V2.6 บรรลุความสามารถหลักที่เหนือกว่าอย่างครอบคลุม เช่น การเข้าใจภาพเดียว หลายภาพ และวิดีโอในฝั่งไคลเอ็นต์ และนำการทำความเข้าใจวิดีโอแบบเรียลไทม์ การทำความเข้าใจร่วมกันหลายภาพ และฟังก์ชันอื่นๆ มาสู่ฝั่งไคลเอ็นต์ เป็นครั้งแรกที่นำมันเข้าใกล้สถานการณ์โลกแห่งความจริงที่ซับซ้อนมากขึ้น
ประสิทธิภาพและประสิทธิภาพ: รุ่นนี้มีขนาดเล็กและใหญ่ โดยมีความหนาแน่นของพิกเซลสูงมาก (ความหนาแน่นของโทเค็น) ซึ่งสูงเป็นสองเท่าของความหนาแน่นของพิกเซลการเข้ารหัสโทเค็นเดี่ยวของ GPT-4o และบรรลุประสิทธิภาพการทำงานที่สูงมากบนอุปกรณ์ปลายทาง
ความเป็นมิตรฝั่งไคลเอ็นต์: โมเดลต้องการหน่วยความจำเพียง 6GB หลังจากการหาปริมาณ และความเร็วในการอนุมานฝั่งไคลเอ็นต์สูงถึง 18 โทเค็นต่อวินาที ซึ่งเร็วกว่ารุ่นก่อนหน้าถึง 33% และรองรับหลายภาษา และกรอบการอนุมาน
การขยายฟังก์ชัน: MiniCPM-V2.6 ใช้ความสามารถ OCR เพื่อย้ายความสามารถในการวิเคราะห์ภาพความละเอียดสูงของฉากภาพเดียวไปยังฉากหลายภาพและวิดีโอ ช่วยลดจำนวนโทเค็นภาพและประหยัดทรัพยากร
ความสามารถในการให้เหตุผล: แสดงให้เห็นความสามารถที่ยอดเยี่ยมในการทำความเข้าใจหลายภาพและงานการให้เหตุผลที่ซับซ้อน เช่น คำแนะนำทีละขั้นตอนสำหรับการปรับเบาะจักรยาน และการระบุร่องด้านหลังมีม
ICL แบบหลายกราฟ: โมเดลนี้รองรับการเรียนรู้แบบไม่กี่ช็อตตามบริบท สามารถปรับให้เข้ากับงานในสาขาเฉพาะได้อย่างรวดเร็ว และปรับปรุงความเสถียรของเอาต์พุต
สถาปัตยกรรมภาพความละเอียดสูง: ด้วยสถาปัตยกรรมภาพแบบครบวงจร ความสามารถ OCR ของโมเดลจะดำเนินต่อไป ทำให้สามารถขยายจากภาพเดี่ยวไปเป็นหลายภาพและวิดีโอได้อย่างราบรื่น
อัตราการเกิดภาพหลอนต่ำมาก: MiniCPM-V2.6 ทำงานได้ดีในการประเมินภาพหลอน ซึ่งแสดงให้เห็นถึงความน่าเชื่อถือ
การเปิดตัวโมเดล MiniCPM-V2.6 มีความสำคัญอย่างยิ่งต่อการพัฒนา AI ฝั่งปลายทาง ซึ่งไม่เพียงแต่ปรับปรุงความสามารถในการประมวลผลแบบหลายรูปแบบเท่านั้น แต่ยังแสดงให้เห็นถึงความเป็นไปได้ในการสร้าง AI ประสิทธิภาพสูงบนอุปกรณ์ปลายทางด้วย ทรัพยากรที่จำกัด
ที่อยู่โอเพ่นซอร์ส MiniCPM-V2.6:
GitHub:
https://github.com/OpenBMB/MiniCPM-V
การกอดใบหน้า:
https://huggingface.co/openbmb/MiniCPM-V-2_6
ที่อยู่การสอนการใช้งาน llama.cpp, ollama, vllm:
https://modelbest.feishu.cn/docx/Duptdntfro2Clfx2DzuczHxAnhc
ที่อยู่โอเพ่นซอร์สซีรี่ส์ MiniCPM:
https://github.com/OpenBMB/MiniCPM
การเกิดขึ้นของ MiniCPM-V2.6 ได้กระตุ้นการพัฒนาเทคโนโลยี AI ฝั่งไคลเอ็นต์อย่างไม่ต้องสงสัย ประสิทธิภาพอันทรงประสิทธิภาพและวิธีการโอเพ่นซอร์สที่สะดวกจะมอบทรัพยากรอันมีค่าสำหรับนักพัฒนาและนักวิจัยจำนวนมากขึ้น และส่งเสริมนวัตกรรมเพิ่มเติมและการเผยแพร่แอปพลิเคชัน AI ฝั่งอุปกรณ์ให้เป็นที่นิยม เรารอคอยซีรี่ส์ MiniCPM ที่จะนำเสนอความประหลาดใจอีกมากมายในอนาคต!