การเปิดตัวครั้งใหญ่ของ Meta Company! โอเพ่นซอร์สของรุ่นภาษาขนาดใหญ่ล่าสุด Llama 3.1 405B ด้วยปริมาณพารามิเตอร์สูงถึง 128 พันล้าน และประสิทธิภาพเทียบได้กับ GPT-4 ในหลาย ๆ งาน หลังจากหนึ่งปีของการเตรียมการอย่างรอบคอบ ตั้งแต่การวางแผนโครงการไปจนถึงการตรวจสอบขั้นสุดท้าย ในที่สุดรุ่นซีรีส์ Llama 3 ก็ออกสู่สาธารณะในที่สุด โอเพ่นซอร์สนี้ไม่เพียงแต่รวมตัวโมเดลเท่านั้น แต่ยังรวมถึงการประมวลผลข้อมูลก่อนการฝึกอบรมที่ได้รับการปรับปรุง การประกันคุณภาพข้อมูลหลังการฝึกอบรม และเทคโนโลยีการวัดปริมาณที่มีประสิทธิภาพ เพื่อลดความต้องการในการประมวลผล และทำให้นักพัฒนาใช้งานได้ง่ายขึ้น บรรณาธิการของ Downcodes จะอธิบายรายละเอียดการปรับปรุงและไฮไลท์ของ Llama 3.1 405B
เมื่อคืน Meta ได้ประกาศโอเพ่นซอร์สของรุ่นภาษาขนาดใหญ่ล่าสุด Llama3.1 405B ข่าวใหญ่นี้ระบุว่าหลังจากหนึ่งปีของการเตรียมการอย่างรอบคอบ ตั้งแต่การวางแผนโครงการไปจนถึงการตรวจสอบขั้นสุดท้าย ในที่สุดโมเดลซีรีส์ Llama3 ก็ได้เปิดตัวสู่สาธารณะแล้ว
Llama3.1405B คือโมเดลการใช้งานเครื่องมือหลายภาษาพร้อมพารามิเตอร์ 128 พันล้านพารามิเตอร์ หลังจากการฝึกล่วงหน้าด้วยความยาวบริบท 8K โมเดลจะได้รับการฝึกเพิ่มเติมด้วยความยาวบริบท 128K จากข้อมูลของ Meta ประสิทธิภาพของโมเดลนี้ในงานหลายอย่างเทียบได้กับ GPT-4 ชั้นนำของอุตสาหกรรม
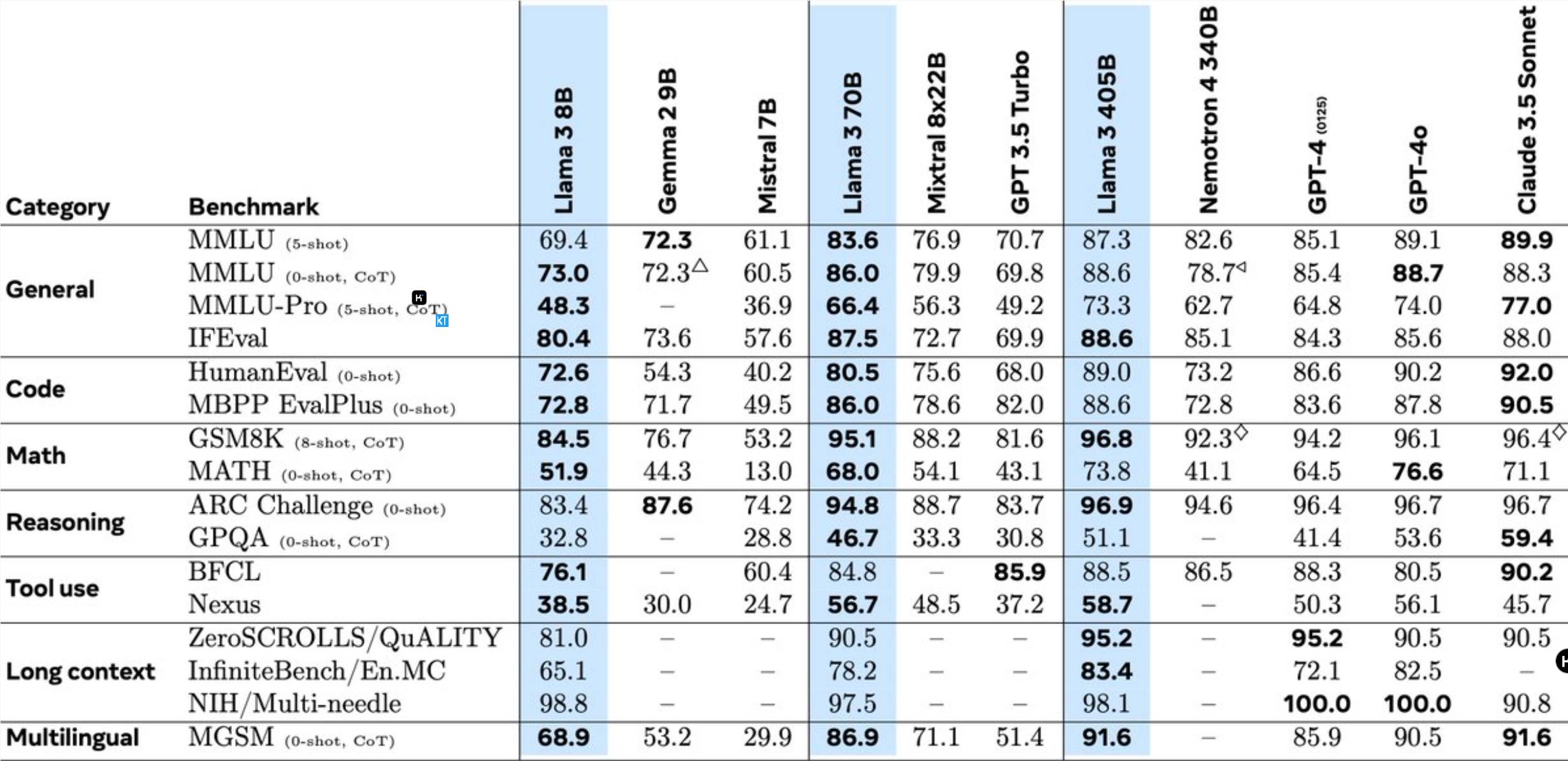
เมื่อเปรียบเทียบกับรุ่น Llama รุ่นก่อนหน้า Meta ได้รับการปรับให้เหมาะสมในหลายด้าน:
การฝึกอบรมล่วงหน้าของโมเดล 405B ถือเป็นความท้าทายครั้งใหญ่ โดยเกี่ยวข้องกับโทเค็น 15.6 ล้านล้านโทเค็น และการดำเนินการจุดลอยตัว 3.8x10^25 จุด ด้วยเหตุนี้ Meta จึงปรับสถาปัตยกรรมการฝึกอบรมทั้งหมดให้เหมาะสมและใช้ GPU H100 มากกว่า 16,000 ตัว
เพื่อรองรับการอนุมานการผลิตจำนวนมากของโมเดล 405B ทาง Meta ได้ปรับขนาดจาก 16 บิต (BF16) เป็น 8 บิต (FP8) ซึ่งช่วยลดความต้องการในการประมวลผลลงอย่างมาก และช่วยให้โหนดเซิร์ฟเวอร์เดียวสามารถรันโมเดลได้
นอกจากนี้ Meta ยังใช้โมเดล 405B เพื่อปรับปรุงคุณภาพหลังการฝึกของรุ่น 70B และ 8B ในระยะหลังการฝึกอบรม ทีมงานได้ปรับปรุงโมเดลการแชทผ่านกระบวนการจัดตำแหน่งหลายรอบ รวมถึงการปรับแต่งแบบละเอียดภายใต้การดูแล (SFT) การสุ่มตัวอย่างการปฏิเสธ และการเพิ่มประสิทธิภาพการกำหนดลักษณะโดยตรง เป็นที่น่าสังเกตว่าตัวอย่าง SFT ส่วนใหญ่สร้างขึ้นโดยใช้ข้อมูลสังเคราะห์
Llama3 ยังผสานรวมฟังก์ชันรูปภาพ วิดีโอ และเสียง โดยใช้แนวทางผสมผสานเพื่อให้โมเดลสามารถจดจำรูปภาพและวิดีโอ และสนับสนุนการโต้ตอบด้วยเสียง อย่างไรก็ตาม คุณสมบัติเหล่านี้ยังอยู่ระหว่างการพัฒนาและยังไม่ได้เปิดตัวอย่างเป็นทางการ
Meta ยังได้อัปเดตข้อตกลงใบอนุญาตเพื่อให้นักพัฒนาสามารถใช้ผลลัพธ์ของโมเดล Llama เพื่อปรับปรุงโมเดลอื่นๆ
นักวิจัยที่ Meta กล่าวว่า เป็นเรื่องน่าตื่นเต้นอย่างยิ่งที่ได้ทำงานแถวหน้าของ AI ที่มีความสามารถระดับแนวหน้าในอุตสาหกรรม และเผยแพร่ผลการวิจัยอย่างเปิดเผยและโปร่งใส เราหวังว่าจะได้เห็นนวัตกรรมที่โมเดลโอเพ่นซอร์สนำมา และศักยภาพของโมเดลซีรีส์ Llama ในอนาคต!
ความคิดริเริ่มโอเพ่นซอร์สนี้จะนำโอกาสและความท้าทายใหม่ ๆ มาสู่สาขา AI อย่างไม่ต้องสงสัย และส่งเสริมการพัฒนาเทคโนโลยีแบบจำลองภาษาขนาดใหญ่ต่อไป
โอเพ่นซอร์สของ Llama 3.1 405B จะส่งเสริมความก้าวหน้าของเทคโนโลยีแบบจำลองภาษาขนาดใหญ่อย่างมาก และนำความเป็นไปได้มาสู่สาขา AI มากขึ้น เราหวังเป็นอย่างยิ่งว่านักพัฒนาจะสร้างแอปพลิเคชันที่น่าทึ่งมากขึ้นจากโมเดลนี้!