การปรับปรุงประสิทธิภาพของโมเดลภาษาขนาดใหญ่เป็นจุดสนใจในการวิจัยในด้านปัญญาประดิษฐ์มาโดยตลอด เมื่อเร็วๆ นี้ ทีมวิจัยจาก Aleph Alpha, Technical University of Darmstadt และสถาบันอื่นๆ ได้พัฒนาวิธีการใหม่ที่เรียกว่า T-FREE ซึ่งช่วยปรับปรุงประสิทธิภาพการทำงานของโมเดลภาษาขนาดใหญ่ได้อย่างมาก วิธีนี้จะช่วยลดจำนวนพารามิเตอร์เลเยอร์การฝังโดยใช้อักขระสามตัวสำหรับการเปิดใช้งานแบบกระจาย และจำลองความคล้ายคลึงกันทางสัณฐานวิทยาระหว่างคำได้อย่างมีประสิทธิภาพ โดยจะช่วยลดการใช้ทรัพยากรการประมวลผลอย่างมาก ในขณะเดียวกันก็รับประกันประสิทธิภาพของโมเดล เทคโนโลยีที่ก้าวล้ำนี้นำมาซึ่งความเป็นไปได้ใหม่ๆ สำหรับการประยุกต์ใช้โมเดลภาษาขนาดใหญ่
ทีมวิจัยเพิ่งเปิดตัววิธีการใหม่ที่น่าตื่นเต้นที่เรียกว่า T-FREE ซึ่งช่วยให้ประสิทธิภาพการทำงานของโมเดลภาษาขนาดใหญ่พุ่งสูงขึ้น นักวิทยาศาสตร์จาก Aleph Alpha, TU Darmstadt, hessian.AI และศูนย์วิจัยปัญญาประดิษฐ์แห่งเยอรมนี (DFKI) ร่วมกันเปิดตัวเทคโนโลยีอันน่าทึ่งนี้ ซึ่งมีชื่อเต็มว่า "Sparse Representation โดยไม่ต้องแท็กเกอร์ การฝังหน่วยความจำที่มีประสิทธิภาพนั้นเป็นไปได้"
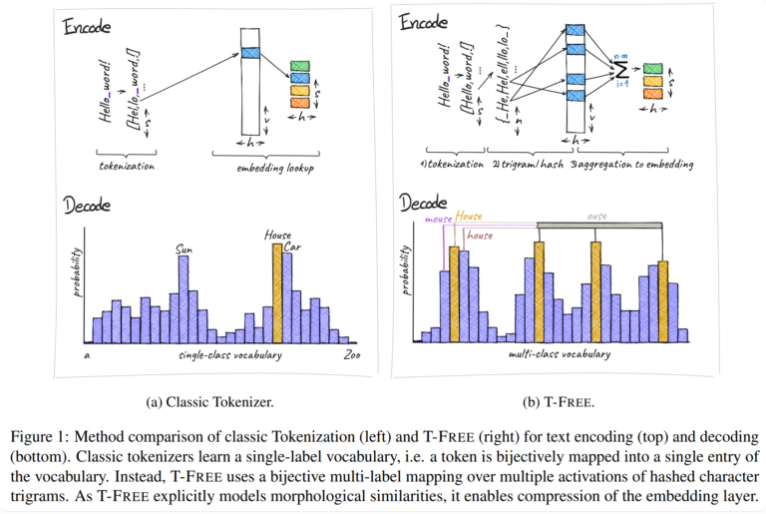
ตามเนื้อผ้า เราใช้โทเค็นไนเซอร์เพื่อแปลงข้อความให้เป็นรูปแบบตัวเลขที่คอมพิวเตอร์สามารถเข้าใจได้ แต่ T-FREE ได้เลือกเส้นทางอื่น ใช้อักขระสามตัวซึ่งเราเรียกว่า "สามเท่า" เพื่อฝังคำลงในโมเดลโดยตรงผ่านการเปิดใช้งานแบบกระจัดกระจาย ผลจากการย้ายที่เป็นนวัตกรรมนี้ ทำให้จำนวนพารามิเตอร์ในเลเยอร์การฝังลดลงอย่างน่าประหลาดใจถึง 85% หรือมากกว่านั้น ในขณะที่ประสิทธิภาพของแบบจำลองไม่ได้รับผลกระทบเลยเมื่อจัดการงานต่างๆ เช่น การจัดหมวดหมู่ข้อความและการตอบคำถาม
จุดเด่นอีกประการหนึ่งของ T-FREE ก็คือมันจำลองความคล้ายคลึงทางสัณฐานวิทยาระหว่างคำได้อย่างชาญฉลาด เช่นเดียวกับคำว่า "บ้าน" "บ้าน" และ "บ้าน" ที่เรามักพบในชีวิตประจำวัน T-FREE สามารถนำเสนอคำที่คล้ายกันเหล่านี้ในแบบจำลองได้อย่างมีประสิทธิภาพมากขึ้น นักวิจัยเชื่อว่าคำที่คล้ายกันควรฝังไว้ใกล้กันเพื่อให้ได้อัตราการบีบอัดที่สูงขึ้น ดังนั้น T-FREE จึงไม่เพียงแต่ลดขนาดของเลเยอร์การฝังเท่านั้น แต่ยังลดความยาวการเข้ารหัสโดยเฉลี่ยของข้อความลงถึง 56% อีกด้วย
สิ่งที่ควรค่าแก่การกล่าวถึงคือ T-FREE ทำงานได้ดีเป็นพิเศษในการถ่ายโอนการเรียนรู้ระหว่างภาษาต่างๆ ในการทดลองครั้งหนึ่ง นักวิจัยใช้แบบจำลองที่มีพารามิเตอร์ 3 พันล้านพารามิเตอร์ โดยฝึกเป็นภาษาอังกฤษก่อน จากนั้นจึงฝึกเป็นภาษาเยอรมัน และพบว่า T-FREE สามารถปรับเปลี่ยนได้ดีกว่าวิธีการที่ใช้แท็กเกอร์แบบดั้งเดิม
อย่างไรก็ตาม นักวิจัยยังคงถ่อมตัวเกี่ยวกับผลลัพธ์ในปัจจุบัน พวกเขายอมรับว่าจนถึงขณะนี้การทดลองยังจำกัดอยู่เพียงโมเดลที่มีพารามิเตอร์ไม่เกิน 3 พันล้านพารามิเตอร์ และจะมีการวางแผนการประเมินเพิ่มเติมสำหรับโมเดลขนาดใหญ่และชุดข้อมูลที่ใหญ่ขึ้นในอนาคต
การเกิดขึ้นของวิธี T-FREE ให้แนวคิดใหม่ในการปรับปรุงประสิทธิภาพของโมเดลภาษาขนาดใหญ่ ข้อดีของการลดต้นทุนการคำนวณและปรับปรุงประสิทธิภาพของโมเดลนั้นคุ้มค่าแก่ความสนใจ ทิศทางการวิจัยในอนาคตจะมุ่งเน้นไปที่การตรวจสอบแบบจำลองขนาดใหญ่และชุดข้อมูลเพื่อขยายขอบเขตการใช้งานของ T-FREE และส่งเสริมการพัฒนาเทคโนโลยีแบบจำลองภาษาขนาดใหญ่อย่างต่อเนื่อง เชื่อกันว่า T-FREE จะมีบทบาทสำคัญในสาขาอื่นๆ ในอนาคตอันใกล้นี้