เมื่อเร็วๆ นี้ Kunlun Technology ได้ประกาศว่าโมเดลรางวัลสองรุ่นที่บริษัทพัฒนาขึ้น ได้แก่ Skywork-Reward-Gemma-2-27B และ Skywork-Reward-Llama-3.1-8B ได้รับผลลัพธ์ที่ยอดเยี่ยมบน RewardBench โดยมีโมเดล 27B อยู่ในอันดับต้นๆ นับเป็นการแสดงให้เห็นว่า Kunlun Wanwei ได้สร้างความก้าวหน้าครั้งสำคัญในด้านปัญญาประดิษฐ์ โดยเฉพาะอย่างยิ่งในการวิจัยและพัฒนาโมเดลการให้รางวัล และให้การสนับสนุนด้านเทคนิคใหม่สำหรับการฝึกโมเดลภาษาขนาดใหญ่ โมเดลการให้รางวัลมีความสำคัญอย่างยิ่งในการเรียนรู้แบบเสริมกำลัง เนื่องจากสามารถชี้แนะการเรียนรู้โมเดลและสร้างเนื้อหาที่สอดคล้องกับความชอบของมนุษย์มากกว่า แบบจำลองของ Kunlun Wanwei มีข้อได้เปรียบที่ไม่เหมือนใครในการเลือกข้อมูลและการฝึกแบบจำลอง ซึ่งทำให้ทำงานได้ดีในด้านต่างๆ เช่น บทสนทนาและความปลอดภัย และโดยเฉพาะอย่างยิ่งแสดงให้เห็นถึงความสามารถที่แข็งแกร่งเมื่อประมวลผลตัวอย่างที่ยากลำบาก
เมื่อเร็วๆ นี้ Kunlun Wanwei Technology Co., Ltd. ได้ประกาศเปิดตัวโมเดลรางวัลใหม่ 2 โมเดลที่พัฒนาโดยบริษัท Skywork-Reward-Gemma-2-27B และ Skywork-Reward-Llama-3.1-8B ซึ่งทำงานได้ดีบน RewardBench ซึ่งเป็นโมเดลรางวัลที่เชื่อถือได้ในระดับสากล เกณฑ์มาตรฐานการประเมินผล หนึ่งในนั้น โมเดล Skywork-Reward-Gamma-2-27B ได้รับรางวัลสูงสุดและได้รับการยอมรับอย่างสูงจากเจ้าหน้าที่ของ RewardBench
โมเดลการให้รางวัลครองตำแหน่งหลักในการเรียนรู้แบบเสริมกำลัง ประเมินประสิทธิภาพของตัวแทนในสถานะต่างๆ และให้สัญญาณรางวัลเพื่อเป็นแนวทางในกระบวนการเรียนรู้ของตัวแทน เพื่อให้สามารถเลือกได้อย่างเหมาะสมที่สุดในสภาพแวดล้อมเฉพาะ ในการฝึกอบรมโมเดลภาษาขนาดใหญ่ โมเดลการให้รางวัลมีบทบาทสำคัญเป็นพิเศษ ช่วยให้โมเดลเข้าใจและสร้างเนื้อหาที่สอดคล้องกับความต้องการของมนุษย์ได้แม่นยำยิ่งขึ้น
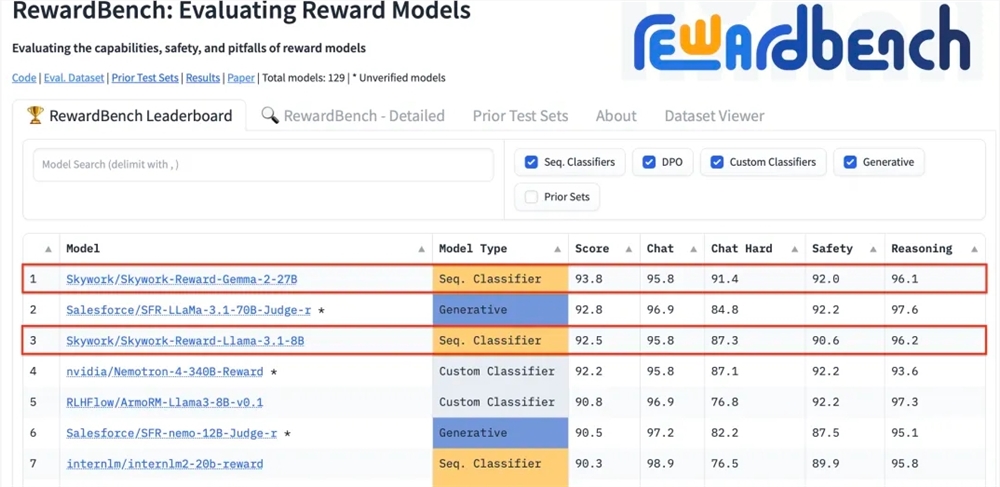
RewardBench เป็นรายการเกณฑ์มาตรฐานที่ประเมินประสิทธิภาพของโมเดลรางวัลในโมเดลภาษาขนาดใหญ่โดยเฉพาะ โดยจะประเมินโมเดลอย่างครอบคลุมผ่านงานต่างๆ รวมถึงบทสนทนา การใช้เหตุผล และความปลอดภัย ชุดข้อมูลทดสอบของรายการนี้ประกอบด้วยสามคำที่ประกอบด้วยคำพร้อมท์ การตอบกลับที่เลือก และการตอบกลับที่ถูกปฏิเสธ ซึ่งใช้เพื่อทดสอบว่าแบบจำลองรางวัลสามารถจัดอันดับคำตอบที่เลือกได้อย่างถูกต้องท่ามกลางคำตอบที่ถูกปฏิเสธที่ได้รับจากคำพร้อมท์หรือไม่ .
โมเดล Skywork-Reward ของ Kunlun Wanwei ได้รับการพัฒนาผ่านชุดข้อมูลที่เรียงลำดับบางส่วนอย่างระมัดระวังและโมเดลพื้นฐานที่ค่อนข้างเล็ก เมื่อเปรียบเทียบกับโมเดลรางวัลที่มีอยู่ ข้อมูลที่เรียงลำดับบางส่วนจะมาจากข้อมูลสาธารณะบนอินเทอร์เน็ตเท่านั้น และจะถูกกรองผ่านตัวกรองเฉพาะเพื่อให้ได้ข้อมูลที่สูง - ชุดข้อมูลการตั้งค่าคุณภาพ ข้อมูลครอบคลุมหัวข้อต่างๆ มากมาย รวมถึงความปลอดภัย คณิตศาสตร์ และโค้ด และได้รับการตรวจสอบด้วยตนเองเพื่อให้แน่ใจว่าข้อมูลมีความเที่ยงธรรมและความสำคัญของช่องว่างของรางวัล
หลังจากการทดสอบ โมเดลการให้รางวัลของ Kunlun Wanwei แสดงให้เห็นประสิทธิภาพที่ยอดเยี่ยมในด้านต่างๆ เช่น บทสนทนาและการรักษาความปลอดภัย โดยเฉพาะอย่างยิ่งเมื่อเผชิญกับตัวอย่างที่ยากลำบาก มีเพียงโมเดล Skywork-Reward-Gamma-2-27B เท่านั้นที่ให้การคาดการณ์ที่ถูกต้อง ความสำเร็จนี้ถือเป็นจุดแข็งทางเทคนิคและความสามารถด้านนวัตกรรมของ Kunlun Wanwei ในด้าน AI ระดับโลก และยังมอบความเป็นไปได้ใหม่ๆ ในการพัฒนาและการประยุกต์ใช้เทคโนโลยี AI
ที่อยู่รุ่น 27B:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
ที่อยู่รุ่น 8B:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
ประสิทธิภาพอันยอดเยี่ยมของ Kunlun Wanwei บน RewardBench แสดงให้เห็นถึงความสามารถชั้นนำด้านเทคโนโลยีและนวัตกรรมในด้านปัญญาประดิษฐ์ นอกจากนี้ ยังมอบทิศทางและความเป็นไปได้ใหม่ๆ สำหรับการพัฒนาโมเดลภาษาขนาดใหญ่ในอนาคตอีกด้วย