การวิจัยของทีม Mamba ทำให้เกิดความก้าวหน้า พวกเขาประสบความสำเร็จในการ "กลั่น" Transformer รุ่น Llama ให้เป็นโมเดล Mamba ที่มีประสิทธิภาพมากขึ้น การวิจัยนี้ผสมผสานเทคโนโลยีอย่างชาญฉลาด เช่น การกลั่นแบบก้าวหน้า การปรับแต่งแบบละเอียดภายใต้การดูแล และการเพิ่มประสิทธิภาพการกำหนดทิศทาง และออกแบบอัลกอริธึมการถอดรหัสการอนุมานใหม่ตามโครงสร้างที่เป็นเอกลักษณ์ของแบบจำลอง Mamba ซึ่งปรับปรุงความเร็วการอนุมานของแบบจำลองได้อย่างมาก โดยไม่ต้องรับประกันประสิทธิภาพการทำงานที่สำคัญ ได้อย่างมีประสิทธิภาพโดยไม่สูญเสีย การวิจัยนี้ไม่เพียงแต่ช่วยลดต้นทุนของการฝึกอบรมโมเดลขนาดใหญ่เท่านั้น แต่ยังให้แนวคิดใหม่ๆ สำหรับการเพิ่มประสิทธิภาพโมเดลในอนาคต ซึ่งมีความสำคัญทางวิชาการที่สำคัญและคุณค่าของการประยุกต์
เมื่อเร็วๆ นี้ การวิจัยของทีม Mamba เป็นที่สะดุดตา: นักวิจัยจากมหาวิทยาลัย เช่น Cornell และ Princeton ประสบความสำเร็จในการ "กลั่น" ลามะ ซึ่งเป็นโมเดล Transformer ขนาดใหญ่ลงใน Mamba และได้ออกแบบอัลกอริธึมการถอดรหัสการอนุมานใหม่ที่ปรับปรุงความเร็วในการอนุมานโมเดลอย่างมีนัยสำคัญ
เป้าหมายของนักวิจัยคือเปลี่ยนลามะให้กลายเป็นแมมบา เหตุใดจึงทำเช่นนี้ เนื่องจากการฝึกฝนโมเดลขนาดใหญ่ตั้งแต่เริ่มต้นนั้นมีราคาแพง และ Mamba ก็ได้รับความสนใจอย่างกว้างขวางตั้งแต่เริ่มก่อตั้ง แต่มีเพียงไม่กี่ทีมเท่านั้นที่ฝึกฝนโมเดล Mamba ขนาดใหญ่ด้วยตัวเอง แม้ว่าจะมีรุ่นที่มีชื่อเสียงในตลาด เช่น Jamba ของ AI21 และ Hybrid Mamba2 ของ NVIDIA แต่ก็มีความรู้มากมายที่ฝังอยู่ใน Transformer รุ่นต่างๆ ที่ประสบความสำเร็จ หากเราสามารถล็อคความรู้นี้และปรับแต่ง Transformer ให้เป็น Mamba ได้ ปัญหาก็จะได้รับการแก้ไข
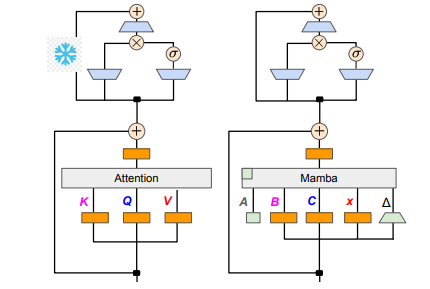
ทีมวิจัยประสบความสำเร็จในการบรรลุเป้าหมายนี้โดยการผสานรวมวิธีการต่างๆ เช่น การกลั่นแบบก้าวหน้า การปรับแต่งแบบละเอียดภายใต้การดูแล และการเพิ่มประสิทธิภาพการกำหนดทิศทาง เป็นที่น่าสังเกตว่าความเร็วก็มีความสำคัญเช่นกันโดยไม่กระทบต่อประสิทธิภาพ Mamba มีข้อได้เปรียบที่ชัดเจนในการให้เหตุผลแบบลำดับยาว และ Transformer ยังมีโซลูชันการเร่งความเร็วในการให้เหตุผล เช่น การถอดรหัสแบบเก็งกำไร เนื่องจากโครงสร้างที่เป็นเอกลักษณ์ของ Mamba ไม่สามารถใช้โซลูชันเหล่านี้ได้โดยตรง นักวิจัยได้ออกแบบอัลกอริธึมใหม่เป็นพิเศษและรวมเข้ากับคุณสมบัติฮาร์ดแวร์เพื่อใช้การถอดรหัสแบบเก็งกำไรที่ใช้ Mamba
ในที่สุด นักวิจัยก็ประสบความสำเร็จในการแปลง Zephyr-7B และ Llama-38B เป็นแบบจำลอง RNN เชิงเส้น และประสิทธิภาพสามารถเทียบได้กับแบบจำลองมาตรฐานก่อนการกลั่น กระบวนการฝึกอบรมทั้งหมดใช้โทเค็น 20B เท่านั้น และผลลัพธ์เทียบได้กับรุ่น Mamba7B ที่ฝึกตั้งแต่เริ่มต้นโดยใช้โทเค็น 1.2T และรุ่น NVIDIA Hybrid Mamba2 ที่ฝึกด้วยโทเค็น 3.5T
ในแง่ของรายละเอียดทางเทคนิค RNN เชิงเส้นและความสนใจเชิงเส้นนั้นเชื่อมโยงกัน ดังนั้นนักวิจัยจึงสามารถนำเมทริกซ์การฉายภาพกลับมาใช้ใหม่ได้ในกลไกความสนใจและสร้างแบบจำลองให้เสร็จสมบูรณ์ผ่านการกำหนดค่าเริ่มต้นของพารามิเตอร์ นอกจากนี้ ทีมวิจัยแช่แข็งพารามิเตอร์ของเลเยอร์ MLP ใน Transformer ค่อยๆ แทนที่ส่วนหัวความสนใจด้วยเลเยอร์ RNN เชิงเส้น (เช่น Mamba) และประมวลผลความสนใจในการสืบค้นแบบกลุ่มสำหรับคีย์และค่าที่ใช้ร่วมกันทั่วทั้งส่วนหัว
ในระหว่างกระบวนการกลั่น มีการใช้กลยุทธ์ในการค่อยๆ เปลี่ยนชั้นความสนใจ การปรับแต่งแบบละเอียดภายใต้การดูแลประกอบด้วยสองวิธีหลัก: วิธีหนึ่งอิงตามความแตกต่างของ KL ระดับคำ และอีกวิธีหนึ่งคือการกลั่นกรองความรู้ระดับลำดับ ในขั้นตอนการปรับแต่งการตั้งค่าของผู้ใช้ ทีมงานใช้วิธีการเพิ่มประสิทธิภาพการตั้งค่าโดยตรง (DPO) เพื่อให้แน่ใจว่าโมเดลสามารถตอบสนองความคาดหวังของผู้ใช้ได้ดีขึ้นเมื่อสร้างเนื้อหาโดยการเปรียบเทียบกับผลลัพธ์ของโมเดลผู้สอน
ต่อไป นักวิจัยเริ่มใช้การถอดรหัสแบบเก็งกำไรของ Transformer กับโมเดล Mamba การถอดรหัสแบบเก็งกำไรสามารถเข้าใจได้ง่ายๆ โดยใช้แบบจำลองขนาดเล็กเพื่อสร้างเอาต์พุตหลายรายการ จากนั้นใช้แบบจำลองขนาดใหญ่เพื่อตรวจสอบเอาต์พุตเหล่านี้ โมเดลขนาดเล็กทำงานได้อย่างรวดเร็วและสามารถสร้างเวกเตอร์เอาท์พุตได้หลายตัวอย่างรวดเร็ว ในขณะที่โมเดลขนาดใหญ่มีหน้าที่ประเมินความแม่นยำของเอาท์พุตเหล่านี้ ซึ่งจะเป็นการเพิ่มความเร็วการอนุมานโดยรวม
เพื่อที่จะใช้กระบวนการนี้ นักวิจัยได้ออกแบบชุดอัลกอริธึมที่ใช้แบบจำลองขนาดเล็กเพื่อสร้างเอาต์พุตแบบร่าง K ในแต่ละครั้ง จากนั้นแบบจำลองขนาดใหญ่จะส่งคืนเอาต์พุตสุดท้ายและแคชของสถานะระดับกลางผ่านการตรวจสอบ วิธีนี้ได้รับผลลัพธ์ที่ดีบน GPU Mamba2.8B ได้รับการเร่งความเร็วในการอนุมาน 1.5 เท่า และอัตราการยอมรับสูงถึง 60% แม้ว่าเอฟเฟกต์จะแตกต่างกันไปใน GPU ของสถาปัตยกรรมที่แตกต่างกัน ทีมวิจัยได้รับการปรับปรุงเพิ่มเติมโดยการบูรณาการเคอร์เนลและการปรับวิธีการใช้งาน และในที่สุดก็บรรลุผลการเร่งความเร็วในอุดมคติ
ในระยะการทดลอง นักวิจัยใช้ Zephyr-7B และ Llama-3Instruct8B ในการฝึกอบรมการกลั่นสามขั้นตอน ในท้ายที่สุด ใช้เวลาเพียง 3 ถึง 4 วันในการทำงานกับ 80G A100 จำนวน 8 ใบ เพื่อสร้างผลลัพธ์การวิจัยขึ้นมาใหม่ได้สำเร็จ งานวิจัยนี้ไม่เพียงแต่แสดงให้เห็นถึงการเปลี่ยนแปลงระหว่าง Mamba และ Llama เท่านั้น แต่ยังให้แนวคิดใหม่ๆ ในการปรับปรุงความเร็วการอนุมานและประสิทธิภาพของแบบจำลองในอนาคต
ที่อยู่กระดาษ: https://arxiv.org/pdf/2408.15237
งานวิจัยนี้มอบประสบการณ์อันมีค่าและแนวทางแก้ไขทางเทคนิคสำหรับการปรับปรุงประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ ผลลัพธ์ดังกล่าวคาดว่าจะนำไปใช้กับสาขาต่างๆ ได้มากขึ้น และส่งเสริมการพัฒนาเทคโนโลยีปัญญาประดิษฐ์เพิ่มเติม การจัดเตรียมที่อยู่กระดาษช่วยให้ผู้อ่านมีความเข้าใจรายละเอียดการวิจัยอย่างลึกซึ้งยิ่งขึ้น