ในแวดวงวิชาการ การแพร่กระจายของเอกสารปลอมกลายเป็นปัญหาร้ายแรง ขัดขวางความก้าวหน้าของการวิจัยทางวิทยาศาสตร์และการเผยแพร่ความรู้อย่างจริงจัง เพื่อจัดการกับความท้าทายนี้ นักวิจัย Ahmed Abdin Hameed จากมหาวิทยาลัย Binghamton ในรัฐนิวยอร์กได้พัฒนาอัลกอริธึมการเรียนรู้ของเครื่องที่เรียกว่า xFakeSci ซึ่งสามารถระบุเอกสารทางวิชาการปลอมได้อย่างมีประสิทธิภาพ และให้การรักษาความสมบูรณ์ทางวิชาการทำให้เกิดวิธีการทางเทคนิคใหม่ บทความนี้จะเจาะลึกถึงหลักการ การใช้งาน และทิศทางการพัฒนาในอนาคตของอัลกอริทึม xFakeSci ซึ่งแสดงให้เห็นถึงศักยภาพมหาศาลในการต่อสู้กับการฉ้อโกงทางวิชาการ
ในยุคที่ข้อมูลล้นหลามในปัจจุบัน โดยเฉพาะอย่างยิ่งในสาขาการวิจัยทางวิทยาศาสตร์ การเกิดขึ้นของเอกสารปลอมเป็นเรื่องยากที่จะป้องกัน
เมื่อเร็วๆ นี้ Ahmed Abdeen Hamed นักวิจัยจากมหาวิทยาลัย Binghamton ในรัฐนิวยอร์ก พัฒนา อัลกอริธึมการเรียนรู้ของเครื่องที่เรียกว่า xFakeSci ซึ่งสามารถระบุเอกสารทางวิชาการปลอมแปลงได้ด้วยความแม่นยำสูงสุดถึง 94%
ฮามีดกล่าวว่าทิศทางการวิจัยหลักของเขาคือสารสนเทศชีวการแพทย์ และในช่วงที่เกิดโรคระบาด บทความวิจัยทางวิทยาศาสตร์ปลอมก็ปรากฏขึ้นอย่างไม่มีที่สิ้นสุด
เขาและทีมงานได้ทำการทดลองจำนวนมาก ผลิตบทความปลอม 50 บทความในหัวข้อทางการแพทย์ยอดนิยม 3 หัวข้อ ได้แก่ โรคอัลไซเมอร์ มะเร็ง และภาวะซึมเศร้า และทำการวิเคราะห์เปรียบเทียบกับบทความจริงในหัวข้อเดียวกัน ด้วยวิธีนี้เขาหวังที่จะค้นพบความแตกต่างและรูปแบบต่างๆ
ในระหว่างกระบวนการวิจัย Hameed ดึงข้อมูลวรรณกรรมที่เกี่ยวข้องโดยใช้ฐานข้อมูล PubMed ของสถาบันสุขภาพแห่งชาติ และใช้คำหลักเดียวกันเพื่อขอ ChatGPT เพื่อสร้างรายงาน สัญชาตญาณของเขาบอกเขาว่าต้องมีรูปแบบบางอย่างระหว่างกระดาษปลอมกับกระดาษจริง
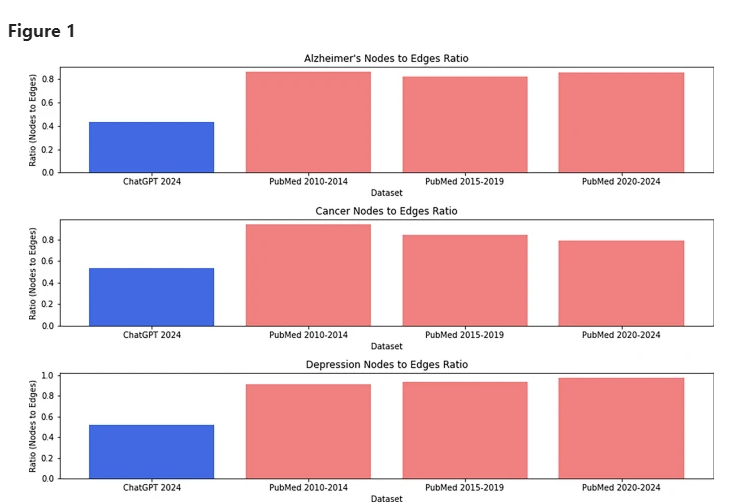
อัตราส่วนโหนดต่อขอบสำหรับชุดข้อมูล ChatGPT ที่แตกต่างกันและบทความทางวิทยาศาสตร์
หลังจากการวิเคราะห์เชิงลึก อัลกอริธึม xFakeSci จะมุ่งเน้นไปที่คุณสมบัติหลักสองประการเป็นหลัก: ประการแรก บิ๊กแกรมในบทความ เช่น "การเปลี่ยนแปลงสภาพภูมิอากาศ" "การทดลองทางคลินิก" ฯลฯ และประการที่สอง การเชื่อมโยงของบิ๊กแกรมเหล่านี้กับคำอื่น ๆ และ แนวคิด
เขาพบว่าจำนวนชุดค่าผสมคำสองคำที่ปรากฏในเอกสารปลอมนั้นต่ำกว่าชุดค่าผสมในเอกสารจริงอย่างมาก แม้ว่าชุดค่าผสมเหล่านี้จะเกี่ยวข้องอย่างใกล้ชิดกับเนื้อหาอื่นในเอกสารปลอมก็ตาม
เขาชี้ให้เห็นว่าเอกสารที่สร้างโดย AI มักได้รับการออกแบบมาเพื่อโน้มน้าวใจผู้อ่าน ในขณะที่เป้าหมายของนักวิจัยที่เป็นมนุษย์คือการรายงานผลการทดลองและวิธีการทดลองตามความเป็นจริง
ในอนาคต Hamed วางแผนที่จะขยายอัลกอริทึม xFakeSci ไปยังสาขาอื่นๆ มากขึ้น รวมถึงวิศวกรรมศาสตร์ วิทยาศาสตร์ และมนุษยศาสตร์ เพื่อตรวจสอบว่าลักษณะของเอกสารปลอมมีความสอดคล้องกันหรือไม่ เขาเน้นย้ำว่าด้วยความก้าวหน้าอย่างต่อเนื่องของเทคโนโลยี AI การระบุเอกสารจริงและเท็จจะทำได้ยากขึ้นต่อไป ดังนั้นการออกแบบโซลูชันที่ครอบคลุมจึงมีความสำคัญอย่างยิ่ง
แม้ว่าอัลกอริธึมปัจจุบันสามารถตรวจจับกระดาษปลอมได้ 94% แต่ กระดาษปลอม 6% อาจยังคงหลุดผ่านเน็ต เขากล่าวอย่างถ่อมตัวว่าถึงแม้จะมีความก้าวหน้าที่สำคัญ แต่ก็ยังจำเป็นต้องมีความพยายามอย่างต่อเนื่องเพื่อปรับปรุงอัตราการได้รับการยอมรับ และเพิ่มการรับรู้ของสาธารณชน
ทางเข้ากระดาษ: https://www.nature.com/articles/s41598-024-66784-6
ไฮไลท์:
** เครื่องมือใหม่ xFakeSci สามารถระบุผลงานวิจัยทางวิทยาศาสตร์ปลอมได้แม่นยำถึง 94% ปกป้องงานวิจัยทางวิทยาศาสตร์ -
? ** นักวิจัยผลิตเอกสารปลอมจำนวนมากและเปรียบเทียบกับเอกสารจริง และพบว่ารูปแบบการเขียนทั้งสองมีความแตกต่างกันอย่างมีนัยสำคัญ -
** ในอนาคต ขอบเขตการประยุกต์ใช้อัลกอริทึมจะได้รับการขยายเพื่อตอบสนองความท้าทายที่ซับซ้อนมากขึ้นของเอกสารที่สร้างโดย AI -
การเกิดขึ้นของอัลกอริธึม xFakeSci ถือเป็นอาวุธอันทรงพลังในการต่อสู้กับการฉ้อโกงทางวิชาการ แต่ก็ยังต้องได้รับการปรับปรุงและปรับปรุงอย่างต่อเนื่อง ความก้าวหน้าของเทคโนโลยีและการรักษาความซื่อสัตย์ทางวิชาการจำเป็นต้องอาศัยความพยายามร่วมกันเพื่อสร้างระบบนิเวศทางวิชาการที่ดียิ่งขึ้น