Google DeepMind ร่วมมือกับมหาวิทยาลัยหลายแห่งเพื่อพัฒนาวิธีการใหม่ที่เรียกว่า Generative Reward Model (GenRM) ซึ่งมีจุดมุ่งหมายเพื่อแก้ไขปัญหาความแม่นยำและความน่าเชื่อถือที่ไม่เพียงพอของ generative AI ในงานการให้เหตุผล แม้ว่าโมเดล AI เจนเนอเรชั่นที่มีอยู่จะถูกใช้กันอย่างแพร่หลายในด้านต่างๆ เช่น การประมวลผลภาษาธรรมชาติ แต่ก็มักจะแสดงข้อมูลที่ผิดพลาดอย่างมั่นใจ โดยเฉพาะอย่างยิ่งในสาขาที่ต้องการความแม่นยำสูงมาก ซึ่งจำกัดขอบเขตการใช้งาน นวัตกรรมของ GenRM คือการกำหนดกระบวนการตรวจสอบใหม่ให้เป็นงานทำนายคำถัดไป ผสานความสามารถในการสร้างข้อความของโมเดลภาษาขนาดใหญ่ (LLM) เข้ากับกระบวนการตรวจสอบ และสนับสนุนการให้เหตุผลแบบลูกโซ่ ซึ่งจะทำให้ได้รับการตรวจสอบที่ครอบคลุมและเป็นระบบมากขึ้น
เมื่อเร็วๆ นี้ ทีมวิจัยของ Google DeepMind ได้ร่วมมือกับมหาวิทยาลัยหลายแห่งเพื่อเสนอวิธีการใหม่ที่เรียกว่า Generative Reward Model (GenRM) ซึ่งมีเป้าหมายเพื่อปรับปรุงความแม่นยำและความน่าเชื่อถือของ generative AI ในงานการให้เหตุผล
Generative AI ถูกนำมาใช้กันอย่างแพร่หลายในหลายสาขา เช่น การประมวลผลภาษาธรรมชาติ โดยส่วนใหญ่จะสร้างข้อความที่สอดคล้องกันโดยการทำนายคำถัดไปของชุดคำ อย่างไรก็ตาม บางครั้งแบบจำลองเหล่านี้แสดงข้อมูลที่ไม่ถูกต้องอย่างมั่นใจ ซึ่งเป็นปัญหาใหญ่โดยเฉพาะอย่างยิ่งในสาขาที่ความถูกต้องแม่นยำเป็นสิ่งสำคัญ เช่น การศึกษา การเงิน และการดูแลสุขภาพ
ปัจจุบัน นักวิจัยได้ลองใช้วิธีแก้ไขปัญหาต่างๆ ที่พบในโมเดล AI ทั่วไปในด้านความแม่นยำของเอาท์พุต ในหมู่พวกเขา แบบจำลองการให้รางวัลแบบเลือกปฏิบัติ (RM) ถูกนำมาใช้เพื่อพิจารณาว่าคำตอบที่เป็นไปได้นั้นถูกต้องตามคะแนนหรือไม่ แต่วิธีนี้ล้มเหลวในการใช้ความสามารถในการสร้างของแบบจำลองภาษาขนาดใหญ่ (LLM) ได้อย่างเต็มที่ อีกวิธีหนึ่งที่ใช้กันทั่วไปคือ "LLM ในฐานะผู้พิพากษา" แต่วิธีนี้มักไม่ค่อยได้ผลเท่ากับผู้ตรวจสอบมืออาชีพเมื่อต้องแก้งานการให้เหตุผลที่ซับซ้อน
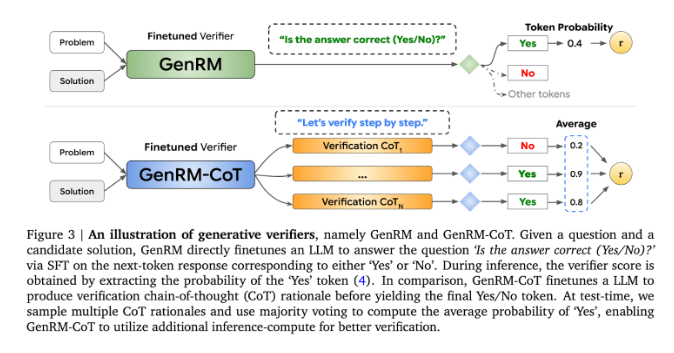
นวัตกรรมของ GenRM คือการกำหนดกระบวนการตรวจสอบใหม่ให้เป็นงานทำนายคำถัดไป ซึ่งหมายความว่า GenRM ต่างจากโมเดลการให้รางวัลแบบเลือกปฏิบัติแบบดั้งเดิม โดยผสมผสานความสามารถในการสร้างข้อความของ LLM เข้ากับกระบวนการตรวจสอบ ทำให้โมเดลสามารถสร้างและประเมินวิธีแก้ปัญหาที่เป็นไปได้ไปพร้อมๆ กัน นอกจากนี้ GenRM ยังรองรับการใช้เหตุผลแบบลูกโซ่ (CoT) กล่าวคือ โมเดลสามารถสร้างขั้นตอนการให้เหตุผลระดับกลางก่อนที่จะถึงข้อสรุปขั้นสุดท้าย จึงทำให้กระบวนการตรวจสอบมีความครอบคลุมและเป็นระบบมากขึ้น
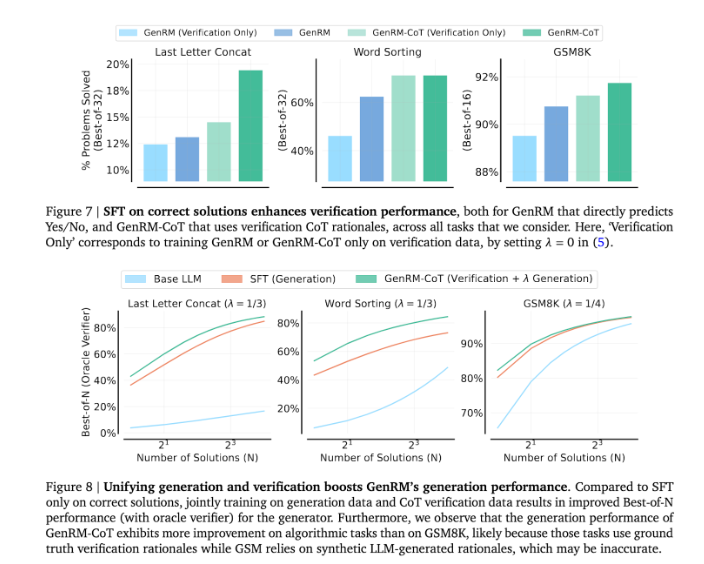
ด้วยการรวมการสร้างและการตรวจสอบเข้าด้วยกัน แนวทาง GenRM จะนำกลยุทธ์การฝึกอบรมแบบรวมศูนย์มาใช้ ซึ่งช่วยให้โมเดลสามารถปรับปรุงความสามารถในการสร้างและการตรวจสอบความถูกต้องได้พร้อมๆ กันในระหว่างการฝึกอบรม ในการใช้งานจริง แบบจำลองจะสร้างขั้นตอนการอนุมานระดับกลางที่ใช้ในการตรวจสอบคำตอบสุดท้าย
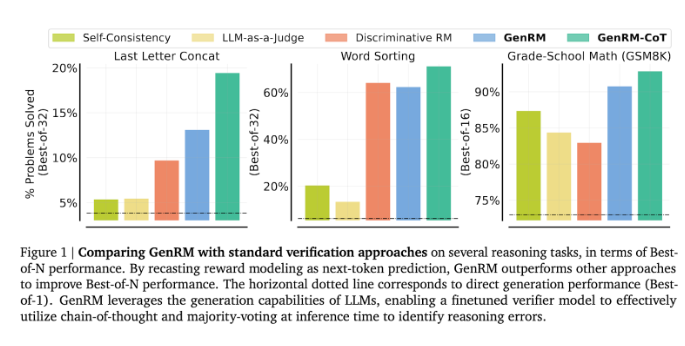
นักวิจัยพบว่าโมเดล GenRM ทำงานได้ดีกับการทดสอบที่เข้มงวดหลายประการ เช่น ความแม่นยำที่ดีขึ้นอย่างมากในวิชาคณิตศาสตร์ก่อนวัยเรียน และงานการแก้ปัญหาอัลกอริทึม เมื่อเปรียบเทียบกับรูปแบบการให้รางวัลแบบเลือกปฏิบัติและ LLM เป็นวิธีตัดสิน อัตราความสำเร็จในการแก้ปัญหาของ GenRM เพิ่มขึ้น 16% เป็น 64%
ตัวอย่างเช่น เมื่อตรวจสอบผลลัพธ์ของรุ่น Gemini1.0Pro GenRM จะเพิ่มอัตราความสำเร็จในการแก้ปัญหาจาก 73% เป็น 92.8%
การนำวิธี GenRM มาใช้ถือเป็นความก้าวหน้าครั้งสำคัญในด้าน generative AI ซึ่งปรับปรุงความแม่นยำและความน่าเชื่อถือของโซลูชันที่สร้างโดย AI อย่างมีนัยสำคัญ ด้วยการรวมการสร้างและการตรวจสอบโซลูชันไว้ในกระบวนการเดียว
โดยรวมแล้ว การเกิดขึ้นของ GenRM ทำให้เกิดแนวคิดใหม่ในการปรับปรุงความน่าเชื่อถือของ generative AI การปรับปรุงที่สำคัญในการแก้ปัญหาการใช้เหตุผลที่ซับซ้อน บ่งชี้ถึงความเป็นไปได้ที่ generative AI จะถูกนำไปใช้ในสาขาต่างๆ มากขึ้น ซึ่งคุ้มค่ากับการวิจัยและการสำรวจเพิ่มเติม