เครื่องมือเพิ่มประสิทธิภาพการสืบค้นฐานข้อมูลอาศัยการประมาณจำนวนสมาชิก (CE) เป็นอย่างมากเพื่อคาดการณ์ขนาดผลลัพธ์การสืบค้น และเลือกแผนการดำเนินการที่ดีที่สุด การประมาณการจำนวนสมาชิกที่ไม่ถูกต้องอาจทำให้ประสิทธิภาพการสืบค้นลดลง วิธีการ CE ที่มีอยู่มีข้อจำกัด โดยเฉพาะอย่างยิ่งเมื่อต้องรับมือกับคำสั่งที่ซับซ้อน แม้ว่าโมเดลการเรียนรู้ CE จะมีความแม่นยำมากกว่า แต่ค่าใช้จ่ายในการฝึกอบรมก็สูงและขาดการประเมินเกณฑ์มาตรฐานอย่างเป็นระบบ
ในฐานข้อมูลเชิงสัมพันธ์สมัยใหม่ การประมาณจำนวนเชิงนับ (CE) มีบทบาทสำคัญ พูดง่ายๆ ก็คือ การประมาณจำนวนนับคือการคาดการณ์จำนวนผลลัพธ์ระดับกลางที่แบบสอบถามฐานข้อมูลจะกลับมา การคาดการณ์นี้มีผลกระทบอย่างมากต่อตัวเลือกแผนการดำเนินการของเครื่องมือเพิ่มประสิทธิภาพคิวรี เช่น การตัดสินใจลำดับการรวม ว่าจะใช้ดัชนีหรือไม่ และการเลือกวิธีการรวมที่ดีที่สุด หากการประมาณจำนวนสมาชิกไม่ถูกต้อง แผนการดำเนินการอาจถูกบุกรุกอย่างมาก ส่งผลให้ความเร็วในการสืบค้นช้ามาก และส่งผลร้ายแรงต่อประสิทธิภาพโดยรวมของฐานข้อมูล
อย่างไรก็ตาม วิธีการประมาณจำนวนนับที่มีอยู่มีข้อจำกัดมากมาย เทคโนโลยี CE แบบดั้งเดิมอาศัยสมมติฐานบางอย่างที่เรียบง่าย และมักจะคาดการณ์จำนวนสมาชิกของแบบสอบถามที่ซับซ้อนได้อย่างแม่นยำ โดยเฉพาะอย่างยิ่งเมื่อมีตารางและเงื่อนไขหลายรายการเกี่ยวข้อง แม้ว่าการเรียนรู้แบบจำลอง CE จะให้ความแม่นยำที่ดีกว่า แต่การประยุกต์ใช้งานนั้นถูกจำกัดด้วยเวลาการฝึกอบรมที่ยาวนาน ความต้องการชุดข้อมูลขนาดใหญ่ และการขาดการประเมินเกณฑ์มาตรฐานอย่างเป็นระบบ
เพื่อเติมเต็มช่องว่างนี้ ทีมวิจัยของ Google ได้เปิดตัว CardBench ซึ่งเป็นเฟรมเวิร์กการวัดประสิทธิภาพใหม่ CardBench มีฐานข้อมูลในโลกแห่งความเป็นจริงมากกว่า 20 รายการและการสืบค้นนับพันรายการ ซึ่งเกินกว่าเกณฑ์มาตรฐานก่อนหน้านี้มาก ช่วยให้นักวิจัยสามารถประเมินและเปรียบเทียบโมเดลการเรียนรู้ CE ที่แตกต่างกันอย่างเป็นระบบภายใต้เงื่อนไขต่างๆ เกณฑ์มาตรฐานรองรับการตั้งค่าหลัก 3 แบบ ได้แก่ โมเดลตามอินสแตนซ์ โมเดล Zero-Shot และโมเดลที่ได้รับการปรับแต่ง ซึ่งเหมาะสำหรับความต้องการการฝึกอบรมที่แตกต่างกัน
CardBench ยังได้รับการออกแบบให้มีชุดเครื่องมือที่สามารถคำนวณสถิติที่จำเป็น สร้างการสืบค้น SQL จริง และสร้างกราฟการสืบค้นคำอธิบายประกอบสำหรับการฝึกโมเดล CE
เกณฑ์มาตรฐานให้ข้อมูลการฝึกอบรมสองชุด: ชุดหนึ่งสำหรับการสืบค้นตารางเดียวที่มีเพรดิเคตตัวกรองหลายตัว และอีกชุดหนึ่งสำหรับการสืบค้นแบบรวมไบนารีที่เกี่ยวข้องกับสองตาราง เกณฑ์มาตรฐานประกอบด้วยแบบสอบถามตารางเดี่ยว 9125 รายการและแบบสอบถามรวมไบนารี 8454 รายการบนชุดข้อมูลขนาดเล็กชุดใดชุดหนึ่ง เพื่อให้มั่นใจว่าสภาพแวดล้อมที่แข็งแกร่งและท้าทายสำหรับการประเมินแบบจำลอง ป้ายกำกับข้อมูลการฝึกอบรมจาก Google BigQuery ต้องใช้เวลาดำเนินการค้นหา CPU 7 ปี โดยเน้นการลงทุนด้านการคำนวณที่สำคัญในการสร้างเกณฑ์มาตรฐานนี้ ด้วยการจัดหาชุดข้อมูลและเครื่องมือเหล่านี้ CardBench ช่วยลดอุปสรรคสำหรับนักวิจัยในการพัฒนาและทดสอบโมเดล CE ใหม่
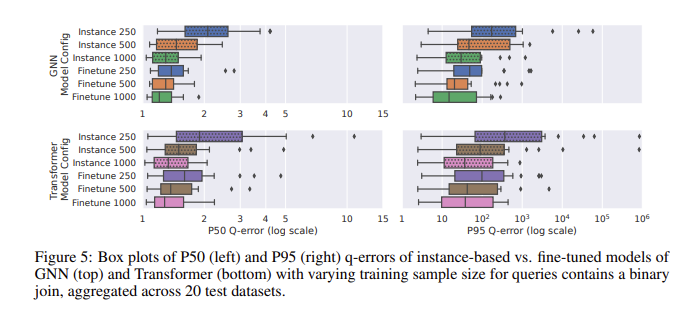
ในการประเมินประสิทธิภาพโดยใช้ CardBench โมเดลที่ได้รับการปรับแต่งทำงานได้ดีเป็นพิเศษ แม้ว่าโมเดล Zero-Shot จะพยายามปรับปรุงความแม่นยำเมื่อนำไปใช้กับชุดข้อมูลที่มองไม่เห็น โดยเฉพาะอย่างยิ่งในการสืบค้นที่ซับซ้อนที่เกี่ยวข้องกับการรวม โมเดลที่ได้รับการปรับแต่งอย่างละเอียดสามารถบรรลุความแม่นยำที่เทียบเคียงได้กับวิธีการแบบอิงอินสแตนซ์ซึ่งมีข้อมูลการฝึกน้อยกว่ามาก ตัวอย่างเช่น โมเดลเครือข่ายประสาทเทียมแบบกราฟ (GNN) ที่ได้รับการปรับแต่งอย่างละเอียดได้รับค่ามัธยฐานของข้อผิดพลาด q-error ที่ 1.32 และข้อผิดพลาด q-error เปอร์เซ็นไทล์ที่ 95 ที่ 120 ในการสืบค้นแบบรวมไบนารี ซึ่งดีกว่าโมเดล Zero-shot อย่างมาก ผลลัพธ์แสดงให้เห็นว่าแม้จะมีการสืบค้นถึง 500 รายการ การปรับแต่งโมเดลที่ได้รับการฝึกล่วงหน้าอย่างละเอียดสามารถปรับปรุงประสิทธิภาพได้อย่างมาก ทำให้เหมาะสำหรับการใช้งานจริงที่ข้อมูลการฝึกอบรมอาจมีจำกัด
การเปิดตัว CardBench นำมาซึ่งความหวังใหม่ให้กับการเรียนรู้การประมาณค่าเชิงจำนวนนับ ซึ่งช่วยให้นักวิจัยสามารถประเมินและปรับปรุงแบบจำลองได้อย่างมีประสิทธิภาพมากขึ้น ซึ่งจะช่วยขับเคลื่อนการพัฒนาเพิ่มเติมในสาขาที่สำคัญนี้
ทางเข้ากระดาษ: https://arxiv.org/abs/2408.16170
กล่าวโดยสรุป CardBench มอบกรอบการเปรียบเทียบประสิทธิภาพที่ครอบคลุมและมีประสิทธิภาพ มอบเครื่องมือและทรัพยากรที่สำคัญสำหรับการวิจัยและพัฒนาแบบจำลองการประมาณค่าเชิงจำนวนสมาชิกในการเรียนรู้ และส่งเสริมความก้าวหน้าของเทคโนโลยีการปรับประสิทธิภาพการสืบค้นฐานข้อมูล ประสิทธิภาพที่ยอดเยี่ยมของโมเดลที่ได้รับการปรับแต่งอย่างประณีตนั้นคุ้มค่าแก่การเอาใจใส่เป็นอย่างยิ่ง โดยมอบความเป็นไปได้ใหม่ๆ ให้กับสถานการณ์การใช้งานจริง