เมื่อเร็วๆ นี้ การศึกษาที่ตีพิมพ์ในนิตยสาร Cureus แสดงให้เห็นว่าโมเดล GPT-4 ของ OpenAI ประสบความสำเร็จในการผ่านการตรวจกายภาพบำบัดแห่งชาติของญี่ปุ่น โดยไม่ต้องผ่านการฝึกอบรมเพิ่มเติม นักวิจัยได้ทดสอบ GPT-4 โดยใช้คำถาม 1,000 ข้อ ซึ่งครอบคลุมเรื่องความจำ ความเข้าใจ การนำไปใช้ การวิเคราะห์ และการประเมินผล ผลการวิจัยพบว่ามีอัตราความแม่นยำ 73.4% และผ่านการทดสอบทั้ง 5 ส่วน งานวิจัยนี้ทำให้เกิดความกังวลเกี่ยวกับศักยภาพของ GPT-4 สำหรับการใช้งานทางการแพทย์ ขณะเดียวกันก็เผยให้เห็นข้อจำกัดในการจัดการกับปัญหาบางประเภท เช่น ปัญหาในทางปฏิบัติและปัญหาที่มีตารางรูปภาพ
การศึกษาที่ผ่านการตรวจสอบโดยผู้ทรงคุณวุฒิเมื่อเร็วๆ นี้ซึ่งตีพิมพ์ในวารสาร Cureus แสดงให้เห็นว่าโมเดลภาษา GPT-4 ของ OpenAI ประสบความสำเร็จในการผ่านการตรวจกายภาพบำบัดแห่งชาติของญี่ปุ่น โดยไม่ต้องผ่านการฝึกอบรมเพิ่มเติมใดๆ
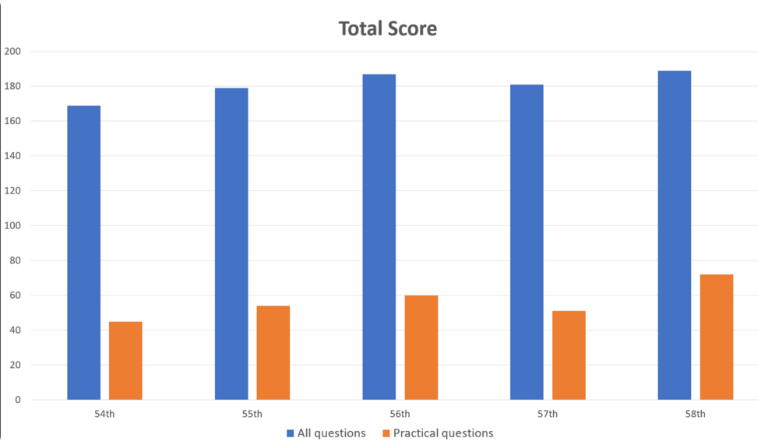
นักวิจัยป้อนคำถาม 1,000 ข้อลงใน GPT-4 ซึ่งครอบคลุมหัวข้อต่างๆ เช่น หน่วยความจำ ความเข้าใจ การประยุกต์ การวิเคราะห์ และการประเมินผล ผลการวิจัยพบว่า GPT-4 ตอบคำถามโดยรวมได้อย่างถูกต้องถึง 73.4% โดยผ่านการทดสอบทั้ง 5 ส่วน อย่างไรก็ตาม การวิจัยยังได้เปิดเผยข้อจำกัดของ AI ในบางด้านด้วย

GPT-4 ทำงานได้ดีกับปัญหาทั่วไป โดยมีความแม่นยำ 80.1% แต่สำหรับปัญหาในทางปฏิบัติมีเพียง 46.6% เท่านั้น ในทำนองเดียวกัน การจัดการคำถามแบบข้อความเท่านั้น (ถูกต้อง 80.5%) ดีกว่าคำถามที่มีรูปภาพและตาราง (ถูกต้อง 35.4%) มาก การค้นพบนี้สอดคล้องกับการวิจัยก่อนหน้าเกี่ยวกับข้อจำกัดของการทำความเข้าใจด้วยภาพ GPT-4
เป็นที่น่าสังเกตว่าความยากของคำถามและความยาวของข้อความมีผลกระทบเพียงเล็กน้อยต่อประสิทธิภาพของ GPT-4 แม้ว่าแบบจำลองนี้จะได้รับการฝึกโดยใช้ข้อมูลภาษาอังกฤษเป็นหลัก แต่ก็ทำงานได้ดีเมื่อจัดการกับอินพุตภาษาญี่ปุ่น
นักวิจัยตั้งข้อสังเกตว่าแม้ว่าการศึกษานี้แสดงให้เห็นถึงศักยภาพของ GPT-4 ในการฟื้นฟูทางคลินิกและการศึกษาทางการแพทย์ แต่ก็ควรดูด้วยความระมัดระวัง พวกเขาเน้นย้ำว่า GPT-4 ไม่ได้ตอบคำถามทุกข้ออย่างถูกต้อง และจำเป็นต้องมีการประเมินเวอร์ชันใหม่และความสามารถของโมเดลในการทดสอบข้อเขียนและการใช้เหตุผลในอนาคต
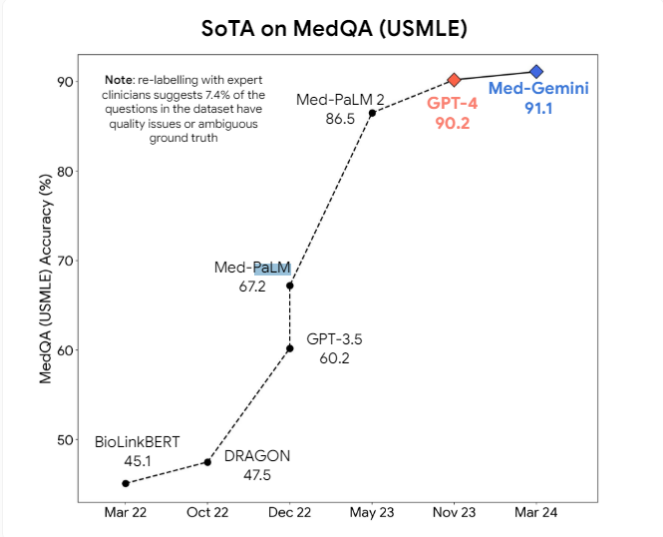
นอกจากนี้ นักวิจัยยังเสนอว่าโมเดลหลายรูปแบบเช่น GPT-4v อาจช่วยปรับปรุงความเข้าใจด้านภาพให้ดีขึ้นอีก ปัจจุบัน โมเดล AI ทางการแพทย์ระดับมืออาชีพ เช่น Med-PaLM2 และ Med-Gemini ของ Google รวมถึงโมเดลทางการแพทย์ของ Meta ที่ใช้ Llama3 กำลังได้รับการพัฒนาอย่างกระตือรือร้น โดยมีเป้าหมายที่จะเหนือกว่าโมเดลวัตถุประสงค์ทั่วไปในงานทางการแพทย์
อย่างไรก็ตาม ผู้เชี่ยวชาญเชื่อว่าอาจใช้เวลานานก่อนที่โมเดล AI ทางการแพทย์จะถูกนำมาใช้อย่างแพร่หลายในทางปฏิบัติ พื้นที่ข้อผิดพลาดของแบบจำลองปัจจุบันยังคงมีขนาดใหญ่เกินไปในการตั้งค่าทางการแพทย์ และจำเป็นต้องมีความก้าวหน้าอย่างมากในความสามารถในการอนุมานเพื่อรวมแบบจำลองเหล่านี้เข้ากับการปฏิบัติทางการแพทย์ในแต่ละวันอย่างปลอดภัย
แม้ว่าการศึกษานี้แสดงให้เห็นถึงศักยภาพของ GPT-4 ในสาขาการแพทย์ แต่ยังเตือนเราด้วยว่าเทคโนโลยี AI ยังคงต้องได้รับการปรับปรุงอย่างต่อเนื่องก่อนที่จะนำไปใช้กับสถานการณ์ทางการแพทย์ที่ซับซ้อนได้อย่างแท้จริง ในอนาคต โมเดลหลายรูปแบบและความสามารถในการให้เหตุผลที่มีประสิทธิภาพมากขึ้นจะเป็นการปรับปรุงที่สำคัญเพื่อให้มั่นใจในความปลอดภัยและความน่าเชื่อถือของ AI ในการรักษาพยาบาล