เมื่อเร็วๆ นี้ MLCommons เปิดเผยผลการอนุมาน MLPerf เวอร์ชัน 4.1 มีผู้ผลิตชิปอนุมาน AI หลายรายเข้าร่วม และการแข่งขันก็ดุเดือด เป็นครั้งแรกที่การแข่งขันครั้งนี้ประกอบด้วยชิปจาก AMD, Google, UntetherAI และผู้ผลิตรายอื่น รวมถึงชิป Blackwell ล่าสุดของ Nvidia นอกเหนือจากการเปรียบเทียบประสิทธิภาพแล้ว ประสิทธิภาพการใช้พลังงานยังกลายเป็นมิติการแข่งขันที่สำคัญอีกด้วย ผู้ผลิตหลายรายได้แสดงทักษะพิเศษของตนและแสดงให้เห็นถึงข้อได้เปรียบของตนในการทดสอบเกณฑ์มาตรฐานต่างๆ ซึ่งนำพลังใหม่มาสู่ตลาดชิปอนุมาน AI
ในด้านการฝึกอบรมปัญญาประดิษฐ์ กราฟิกการ์ดของ Nvidia แทบจะไม่มีใครเทียบได้ แต่เมื่อพูดถึงการอนุมานของ AI คู่แข่งดูเหมือนจะเริ่มตามทัน โดยเฉพาะในแง่ของประสิทธิภาพการใช้พลังงาน แม้จะมีประสิทธิภาพที่แข็งแกร่งของชิป Blackwell ล่าสุดของ Nvidia แต่ก็ไม่ชัดเจนว่าจะสามารถรักษาความเป็นผู้นำได้หรือไม่ วันนี้ ML Commons ประกาศผลการแข่งขันการอนุมาน AI ล่าสุด - MLPerf Inference v4.1 นับเป็นครั้งแรกที่ Instinct accelerator ของ AMD, Trillium accelerator ของ Google, ชิป UntetherAI สตาร์ทอัพของแคนาดา และชิป Blackwell ของ Nvidia เข้าร่วม บริษัทอื่นอีกสองแห่ง ได้แก่ Cerebras และ FuriosaAI ได้เปิดตัวชิปอนุมานใหม่ แต่ยังไม่ได้ส่ง MLPerf เพื่อทำการทดสอบ
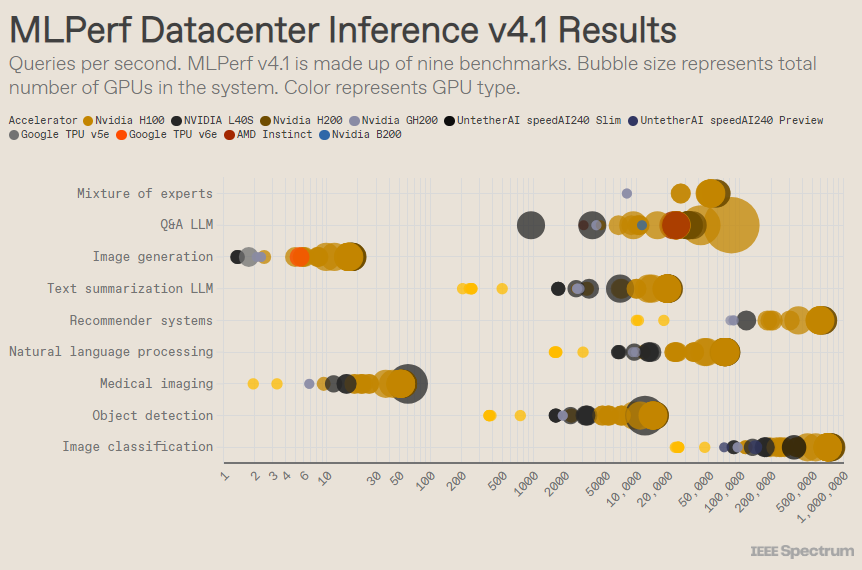
MLPerf มีโครงสร้างเหมือนกับการแข่งขันโอลิมปิก โดยมีกิจกรรมและกิจกรรมย่อยมากมาย หมวดหมู่ “ตู้ศูนย์ข้อมูล” มีรายการมากที่สุด ต่างจากหมวดหมู่เปิด หมวดหมู่ปิดกำหนดให้ผู้เข้าร่วมทำการอนุมานโดยตรงบนโมเดลที่กำหนด โดยไม่ต้องดัดแปลงซอฟต์แวร์อย่างมีนัยสำคัญ หมวดหมู่ศูนย์ข้อมูลจะทดสอบความสามารถในการประมวลผลคำขอเป็นชุดเป็นหลัก ในขณะที่หมวดหมู่ Edge มุ่งเน้นไปที่การลดเวลาแฝง
มีเกณฑ์มาตรฐานที่แตกต่างกัน 9 รายการในแต่ละหมวดหมู่ ครอบคลุมงาน AI ที่หลากหลาย รวมถึงการสร้างภาพยอดนิยม (ลองนึกถึง Midjourney) และการตอบคำถามด้วยโมเดลภาษาขนาดใหญ่ (เช่น ChatGPT) รวมถึงงานที่สำคัญแต่ไม่ค่อยมีใครรู้จัก เช่น การจำแนกภาพ การตรวจจับวัตถุ และกลไกการแนะนำ
รอบนี้จะเพิ่มเกณฑ์มาตรฐานใหม่ - "รุ่นไฮบริดแบบผู้เชี่ยวชาญ" นี่เป็นวิธีการปรับใช้โมเดลภาษาที่ได้รับความนิยมเพิ่มมากขึ้น โดยแบ่งโมเดลภาษาออกเป็นโมเดลขนาดเล็กหลายๆ โมเดล โดยแต่ละโมเดลจะได้รับการปรับแต่งสำหรับงานเฉพาะ เช่น การสนทนารายวัน การแก้ปัญหาทางคณิตศาสตร์ หรือความช่วยเหลือในการเขียนโปรแกรม Miroslav Hodak สมาชิกเจ้าหน้าที่ด้านเทคนิคอาวุโสของ AMD กล่าวว่า ด้วยการมอบหมายแต่ละคำถามให้กับโมเดลขนาดเล็กที่สอดคล้องกัน การใช้ทรัพยากรจะลดลง ลดต้นทุนและเพิ่มปริมาณงาน

ในเกณฑ์มาตรฐาน "ศูนย์ข้อมูลปิด" ที่ได้รับความนิยม ผู้ชนะยังคงส่งผลงานโดยใช้ GPU Nvidia H200 และซูเปอร์ชิป GH200 ซึ่งรวม GPU และ CPU ไว้ในแพ็คเกจเดียว อย่างไรก็ตาม เมื่อพิจารณาผลลัพธ์อย่างละเอียดยิ่งขึ้นจะเผยให้เห็นรายละเอียดที่น่าสนใจบางประการ คู่แข่งบางรายใช้ตัวเร่งความเร็วหลายตัว ในขณะที่บางรายใช้เพียงตัวเดียว ผลลัพธ์จะยิ่งสับสนมากขึ้นหากเราทำให้การสืบค้นต่อวินาทีเป็นมาตรฐานตามจำนวนตัวเร่งความเร็ว และเก็บการส่งที่มีประสิทธิภาพดีที่สุดสำหรับตัวเร่งความเร็วแต่ละประเภท ควรสังเกตว่าแนวทางนี้ละเว้นบทบาทของ CPU และการเชื่อมต่อระหว่างกัน
เมื่อพิจารณาตามแต่ละตัวเร่งความเร็ว Blackwell ของ Nvidia ก็เป็นเลิศในงานคำถามและคำตอบโมเดลภาษาขนาดใหญ่ โดยให้ความเร็วเพิ่มขึ้น 2.5 เท่า จากการทำซ้ำชิปครั้งก่อน ซึ่งเป็นเกณฑ์มาตรฐานเดียวที่ส่งไป ปล่อยชิปแสดงตัวอย่าง speedAI240 ของ AI ออกมาได้เกือบจะเหมือนกับ H200 ในงานจดจำภาพเดียวที่ถูกส่งไป Trillium ของ Google ทำงานได้ต่ำกว่า H100 และ H200 เล็กน้อยในงานสร้างภาพ ในขณะที่ Instinct ของ AMD ทำงานได้เทียบเท่ากับ H100 ในงานคำถามและคำตอบโมเดลภาษาขนาดใหญ่
ส่วนหนึ่งของความสำเร็จของ Blackwell มาจากความสามารถในการรันโมเดลภาษาขนาดใหญ่โดยใช้ความแม่นยำของจุดลอยตัว 4 บิต Nvidia และคู่แข่งพยายามลดจำนวนบิตที่แสดงในโมเดลการแปลง เช่น ChatGPT เพื่อเร่งความเร็วในการคำนวณ Nvidia เปิดตัวคณิตศาสตร์ 8 บิตใน H100 และการนำเสนอนี้ถือเป็นการสาธิตคณิตศาสตร์ 4 บิตครั้งแรกในเกณฑ์มาตรฐาน MLPerf
ความท้าทายที่ใหญ่ที่สุดในการทำงานกับตัวเลขที่มีความแม่นยำต่ำคือการรักษาความถูกต้อง Dave Salvator ผู้อำนวยการฝ่ายการตลาดผลิตภัณฑ์ของ Nvidia กล่าว เพื่อรักษาความแม่นยำสูงในการส่ง MLPerf ทีมงาน Nvidia ได้สร้างนวัตกรรมมากมายในซอฟต์แวร์
นอกจากนี้ แบนด์วิธหน่วยความจำของ Blackwell เพิ่มขึ้นเกือบสองเท่าเป็น 8 เทราไบต์ต่อวินาที เมื่อเทียบกับ H200 ที่ 4.8 เทราไบต์
การส่ง Blackwell ของ Nvidia ใช้ชิปตัวเดียว แต่ Salvator กล่าวว่ามันได้รับการออกแบบมาสำหรับเครือข่ายและการปรับขนาด และจะทำงานได้ดีที่สุดเมื่อรวมกับการเชื่อมต่อระหว่างกัน NVLink ของ Nvidia GPU ของ Blackwell รองรับการเชื่อมต่อ NVLink สูงสุด 18 GB ต่อวินาที โดยมีแบนด์วิธรวม 1.8 เทราไบต์ต่อวินาที ซึ่งเกือบสองเท่าของแบนด์วิดท์การเชื่อมต่อระหว่างกันของ H100
Salvator เชื่อว่าในขณะที่โมเดลภาษาขนาดใหญ่ยังคงขยายขนาดต่อไป แม้แต่การอนุมานก็ยังต้องใช้แพลตฟอร์ม GPU หลายตัวเพื่อตอบสนองความต้องการ และ Blackwell ได้รับการออกแบบมาสำหรับสถานการณ์นี้ “Havel เป็นแพลตฟอร์ม” Salvator กล่าว
Nvidia ส่งระบบชิป Blackwell ของตนไปยังหมวดหมู่ย่อย Preview ซึ่งหมายความว่ายังไม่พร้อมใช้งาน แต่คาดว่าจะพร้อมใช้งานก่อนการเปิดตัว MLPerf ถัดไปซึ่งประมาณหกเดือนนับจากนี้
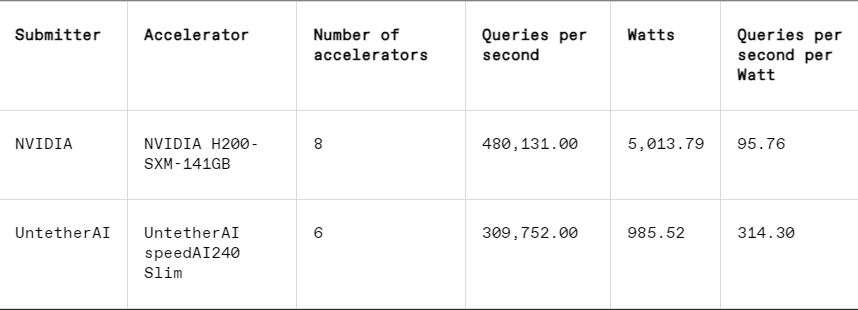
ในแต่ละการวัดประสิทธิภาพ MLPerf ยังมีส่วนการวัดพลังงานที่จะทดสอบการใช้พลังงานจริงของแต่ละระบบอย่างเป็นระบบในขณะที่ปฏิบัติงาน การแข่งขันหลักของรอบนี้ (หมวด Data Center Enclosed Energy) มีผู้ส่งผลงานเพียงสองคน ได้แก่ Nvidia และ Untether AI แม้ว่า Nvidia จะเข้าร่วมในการวัดประสิทธิภาพทั้งหมด แต่ Untether ก็ส่งเฉพาะผลลัพธ์ในงานการจดจำภาพเท่านั้น
Untether AI เป็นเลิศในเรื่องนี้ และประสบความสำเร็จในการบรรลุประสิทธิภาพการใช้พลังงานที่ยอดเยี่ยม ชิปของพวกเขาใช้วิธีการที่เรียกว่า "การประมวลผลในหน่วยความจำ" ชิปของ Untether AI ประกอบด้วยเซลล์หน่วยความจำที่มีโปรเซสเซอร์ขนาดเล็กอยู่ใกล้ๆ โปรเซสเซอร์แต่ละตัวทำงานแบบขนาน โดยประมวลผลข้อมูลพร้อมกันกับหน่วยหน่วยความจำที่อยู่ติดกัน ช่วยลดเวลาและพลังงานที่ใช้ในการถ่ายโอนข้อมูลแบบจำลองระหว่างหน่วยความจำและแกนประมวลผลได้อย่างมาก
“เราพบว่าเมื่อใช้เวิร์กโหลด AI 90% ของการใช้พลังงานกำลังย้ายข้อมูลจาก DRAM ไปยังหน่วยประมวลผลแคช” Robert Beachler รองประธานฝ่ายผลิตภัณฑ์ของ Untether AI กล่าว “สิ่งที่ Untether ทำคือย้ายการคำนวณให้ใกล้กับข้อมูลมากขึ้น แทนที่จะย้ายข้อมูลไปยังหน่วยประมวลผล”
วิธีการนี้ใช้ได้ผลดีเป็นพิเศษในหมวดหมู่ย่อยอื่นของ MLPerf: การปิดขอบ หมวดหมู่นี้มุ่งเน้นไปที่กรณีการใช้งานจริงมากขึ้น เช่น การตรวจสอบเครื่องจักรในโรงงาน หุ่นยนต์มองเห็นนำทาง และยานพาหนะอัตโนมัติ—แอปพลิเคชันที่มีข้อกำหนดที่เข้มงวดสำหรับประสิทธิภาพการใช้พลังงานและการประมวลผลที่รวดเร็ว Beachler อธิบาย
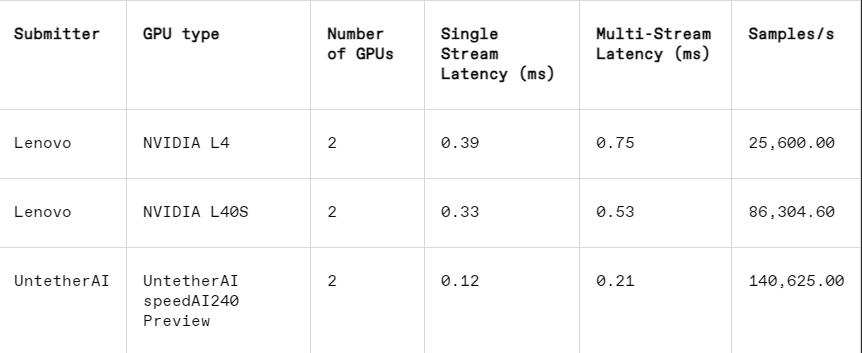
ในงานการจดจำภาพ ประสิทธิภาพความหน่วงของชิปแสดงตัวอย่าง speedAI240 ของ Untether AI นั้นเร็วกว่า L40S ของ Nvidia ถึง 2.8 เท่า และปริมาณงาน (จำนวนตัวอย่างต่อวินาที) ก็เพิ่มขึ้น 1.6 เท่าเช่นกัน สตาร์ทอัพยังส่งผลการใช้พลังงานในหมวดหมู่นี้ด้วย แต่คู่แข่งของ Nvidia ไม่ได้ทำ ซึ่งทำให้การเปรียบเทียบโดยตรงทำได้ยาก อย่างไรก็ตาม ชิปแสดงตัวอย่าง speedAI240 ของ Untether AI มีการใช้พลังงานเล็กน้อยที่ 150 วัตต์ ในขณะที่ L40S ของ Nvidia อยู่ที่ 350 วัตต์ ซึ่งแสดงให้เห็นถึงความได้เปรียบ 2.3 เท่าในด้านการใช้พลังงานและประสิทธิภาพความหน่วงที่ดีขึ้น
แม้ว่า Cerebras และ Furiosa จะไม่ได้เข้าร่วมใน MLPerf แต่พวกเขาก็ได้เปิดตัวชิปใหม่ตามลำดับ Cerebras เปิดตัวบริการอนุมานในการประชุม IEEE Hot Chips ที่มหาวิทยาลัยสแตนฟอร์ด Cerebras ซึ่งตั้งอยู่ใน Sunny Valley รัฐแคลิฟอร์เนียผลิตชิปขนาดยักษ์ที่มีขนาดใหญ่เท่ากับเวเฟอร์ซิลิคอน ดังนั้นจึงหลีกเลี่ยงการเชื่อมต่อระหว่างชิปและเพิ่มแบนด์วิธหน่วยความจำของอุปกรณ์อย่างมาก โดยส่วนใหญ่จะใช้เพื่อฝึกโครงข่ายประสาทเทียมขนาดยักษ์ ตอนนี้พวกเขาได้อัปเกรดคอมพิวเตอร์รุ่นล่าสุด CS3 เพื่อรองรับการอนุมาน
แม้ว่า Cerebras จะไม่ได้ส่ง MLPerf แต่บริษัทอ้างว่าแพลตฟอร์มของตนมีประสิทธิภาพเหนือกว่า H100 ถึง 7x และชิป Groq ของคู่แข่งถึง 2x ในจำนวนโทเค็น LLM ที่สร้างขึ้นต่อวินาที “วันนี้ เราอยู่ในยุค dial-up ของ generative AI” Andrew Feldman ซีอีโอและผู้ร่วมก่อตั้ง Cerebras กล่าว "ทั้งหมดนี้เป็นเพราะมีปัญหาคอขวดของแบนด์วิธหน่วยความจำ ไม่ว่าจะเป็น H100 ของ Nvidia หรือ MI300 ของ AMD หรือ TPU ต่างก็ใช้หน่วยความจำภายนอกเดียวกัน ส่งผลให้เกิดข้อจำกัดเดียวกัน เราทำลายอุปสรรคนั้นเพราะเราทำที่การออกแบบระดับเวเฟอร์ "
ในการประชุม Hot Chips Furiosa จากกรุงโซลยังได้สาธิตชิปรุ่นที่สอง RNGD (อ่านว่า "กบฏ") ชิปใหม่ของ Furiosa มีสถาปัตยกรรม Tensor Contraction Processing (TCP) ในปริมาณงาน AI ฟังก์ชันทางคณิตศาสตร์พื้นฐานคือการคูณเมทริกซ์ ซึ่งมักนำไปใช้ในฮาร์ดแวร์ในรูปแบบดั้งเดิม อย่างไรก็ตาม ขนาดและรูปร่างของเมทริกซ์ เช่น เทนเซอร์ที่กว้างขึ้น อาจแตกต่างกันอย่างมีนัยสำคัญ RNGD ใช้การคูณเทนเซอร์ทั่วไปมากกว่านี้ในรูปแบบดั้งเดิม “ในระหว่างการอนุมาน ขนาดแบตช์จะแตกต่างกันอย่างมาก ดังนั้นจึงจำเป็นอย่างยิ่งที่จะต้องใช้ประโยชน์จากความเท่าเทียมโดยธรรมชาติและการนำข้อมูลกลับมาใช้ใหม่ของรูปร่างเทนเซอร์ที่กำหนด” June Paik ผู้ก่อตั้งและซีอีโอของ Furiosa กล่าวที่ Hot Chips
แม้ว่า Furiosa จะไม่มี MLPerf แต่พวกเขาก็เปรียบเทียบชิป RNGD กับเกณฑ์มาตรฐานโดยสรุป LLM ของ MLPerf ในการทดสอบภายใน และผลลัพธ์ก็เทียบได้กับชิป L40S ของ Nvidia แต่ใช้พลังงานเพียง 185 วัตต์ เมื่อเทียบกับ 320 วัตต์ของ L40S Paik กล่าวว่าประสิทธิภาพจะดีขึ้นด้วยการเพิ่มประสิทธิภาพซอฟต์แวร์เพิ่มเติม
นอกจากนี้ IBM ยังประกาศเปิดตัวชิป Spyre ใหม่ ซึ่งออกแบบมาสำหรับองค์กรต่างๆ เพื่อสร้างเวิร์กโหลด AI และคาดว่าจะวางจำหน่ายในช่วงไตรมาสแรกของปี 2568
เห็นได้ชัดว่าตลาดชิปอนุมาน AI จะต้องคึกคักในอนาคตอันใกล้
อ้างอิง: https://spectrum.ieee.org/new-inference-chips
โดยรวมแล้ว ผลลัพธ์ของ MLPerf v4.1 แสดงให้เห็นว่าการแข่งขันในตลาดชิปอนุมาน AI เริ่มรุนแรงขึ้นเรื่อยๆ แม้ว่า Nvidia จะยังคงรักษาความเป็นผู้นำไว้ได้ แต่การเติบโตของผู้ผลิตอย่าง AMD, Google และ Untether AI ก็ไม่สามารถละเลยได้ ในอนาคต ประสิทธิภาพการใช้พลังงานจะกลายเป็นปัจจัยการแข่งขันที่สำคัญ และเทคโนโลยีใหม่ๆ เช่น การประมวลผลในหน่วยความจำก็จะมีบทบาทสำคัญเช่นกัน นวัตกรรมทางเทคโนโลยีของผู้ผลิตหลายรายจะยังคงส่งเสริมการปรับปรุงความสามารถในการให้เหตุผลของ AI และเป็นแรงผลักดันที่แข็งแกร่งในการทำให้แอปพลิเคชัน AI เป็นที่นิยมและการพัฒนา