ในช่วงไม่กี่ปีที่ผ่านมาประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ (LLM) ได้รับความสนใจอย่างมาก บทความนี้แนะนำการวิจัยที่น่าตื่นเต้น การวิจัยนี้ท้าทายแนวคิดของ "แบบจำลองที่ใหญ่กว่าและดีกว่า" แบบดั้งเดิมให้แนวคิดและทิศทางใหม่สำหรับการพัฒนาในอนาคตของ LLM และยังให้ความเป็นไปได้มากขึ้นสำหรับนักวิจัยและนักพัฒนาที่มีทรัพยากร จำกัด มันแสดงให้เห็นถึงศักยภาพที่ยิ่งใหญ่ของกลยุทธ์การค้นหาในการปรับปรุงความสามารถในการให้เหตุผลและทริกเกอร์ในการคิดเชิงลึกเกี่ยวกับความสัมพันธ์ระหว่างทรัพยากรการคำนวณและพารามิเตอร์โมเดล
เมื่อเร็ว ๆ นี้การศึกษาใหม่น่าตื่นเต้นและพิสูจน์ได้ว่าแบบจำลองภาษาขนาดใหญ่ (LLM) สามารถปรับปรุงประสิทธิภาพได้อย่างมีนัยสำคัญผ่านฟังก์ชั่นการค้นหา โดยเฉพาะอย่างยิ่งรุ่น LLAMA3.1 ที่มีปริมาณพารามิเตอร์เพียง 800 ล้านผ่านการค้นหา 100 ครั้งและไม่สามารถเทียบได้กับ GPT-4O ในรหัส Python
ความคิดนี้ดูเหมือนจะเตือนผู้คนถึงผู้บุกเบิกการเรียนรู้โพสต์บล็อกคลาสสิกของ Rich Sutton "The Bitter Lesson" ในปี 2019 เขากล่าวว่าด้วยการปรับปรุงพลังการคำนวณเราต้องรับรู้ถึงพลังของวิธีการทั่วไป โดยเฉพาะอย่างยิ่งสองวิธีของ "การค้นหา" และ "การเรียนรู้" ดูเหมือนจะเป็นตัวเลือกที่ยอดเยี่ยมที่สามารถขยายได้ต่อไป
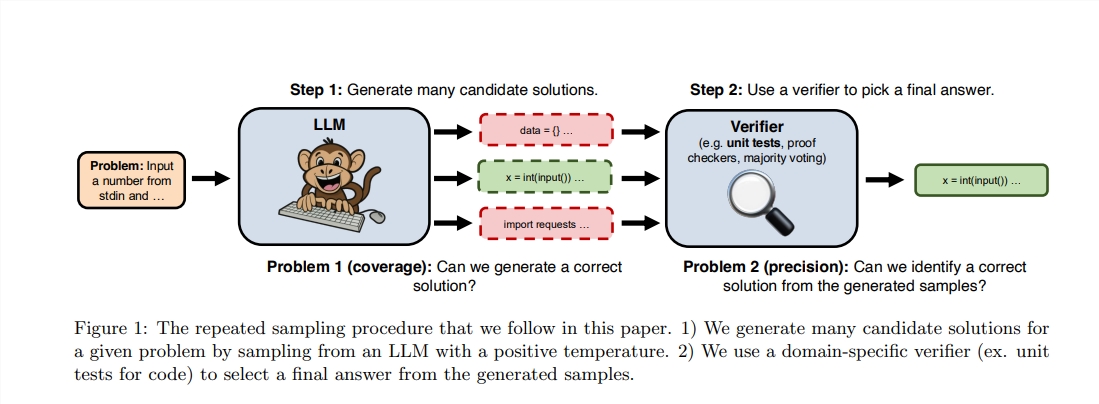
แม้ว่า Sutton จะเน้นความสำคัญของการเรียนรู้นั่นคือแบบจำลองที่ยิ่งใหญ่กว่ามักจะสามารถเรียนรู้ความรู้เพิ่มเติมได้ แต่เรามักจะเพิกเฉยต่อศักยภาพของการค้นหาในกระบวนการให้เหตุผล เมื่อเร็ว ๆ นี้นักวิจัยจาก Stanford, Oxford และ Deepmind พบว่าการเพิ่มจำนวนเวลาการสุ่มตัวอย่างซ้ำ ๆ ในระหว่างขั้นตอนการให้เหตุผลสามารถปรับปรุงประสิทธิภาพของแบบจำลองในสาขาคณิตศาสตร์การให้เหตุผลและการสร้างรหัสได้อย่างมีนัยสำคัญ
หลังจากได้รับแรงบันดาลใจจากการศึกษาเหล่านี้วิศวกรทั้งสองตัดสินใจทำการทดลอง พวกเขาพบว่าการใช้รุ่น Llama ขนาดเล็ก 100 รุ่นสำหรับการค้นหาสามารถเกินกว่าและผูก GPT-4O ในงานการเขียนโปรแกรม Python พวกเขาใช้คำอุปมาอุปมัยที่สดใสเพื่ออธิบาย: "ในอดีตมาเลเซียมาเลเซียสามารถบรรลุความสามารถบางอย่างตอนนี้มีเพียง 100 ลูกเท่านั้นที่สามารถทำสิ่งเดียวกันได้"
เพื่อให้ได้ประสิทธิภาพที่สูงขึ้นพวกเขาใช้ไลบรารี VLLM เพื่อดำเนินการตามแบตช์และทำงานบน 10 A100-40GB GPUs ผู้เขียนเลือกการทดสอบมาตรฐานของ Humaneval เพราะสามารถเรียกใช้รหัสที่สร้างขึ้นโดยการประเมินผลการทดสอบซึ่งมีวัตถุประสงค์และแม่นยำมากขึ้น
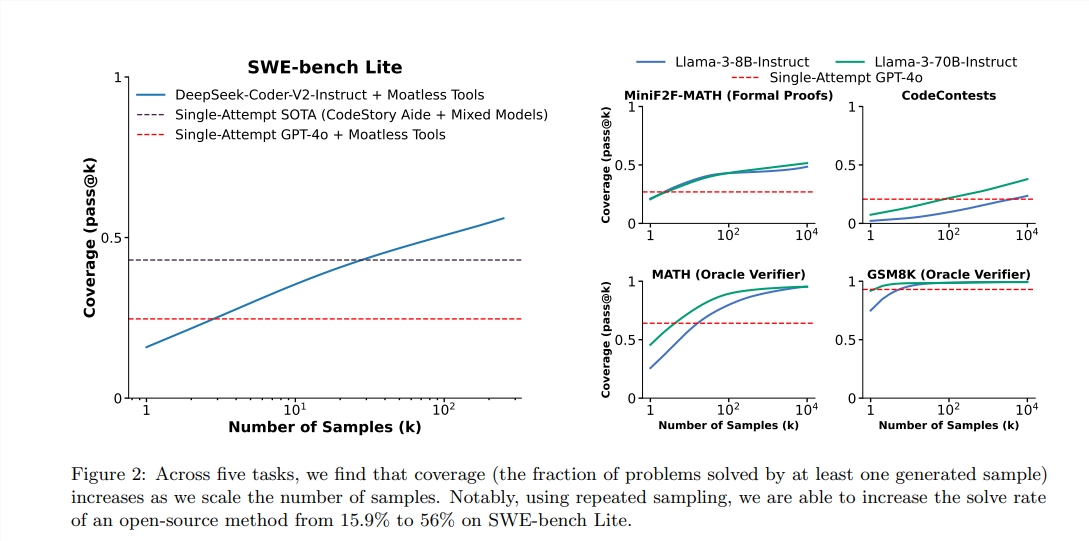
ตามรายงานคะแนน PASS@1 ของ GPT-4O คือ 90.2%ในการใช้เหตุผลตัวอย่างเป็นศูนย์ ด้วยวิธีการข้างต้นคะแนน Pass@K ของ LLAMA3.18B ก็ปรับปรุงอย่างมีนัยสำคัญเช่นกัน เมื่อจำนวนการสุ่มตัวอย่างซ้ำ ๆ คือ 100 คะแนนของ Llama ถึง 90.5%;
เป็นเรื่องที่ควรค่าแก่การกล่าวถึงว่าถึงแม้ว่าการทดลองนี้จะไม่ใช่การทำซ้ำอย่างเข้มงวดของการวิจัยดั้งเดิม แต่ก็เน้นว่าเมื่อวิธีการค้นหาช่วยเพิ่มขั้นตอนการใช้เหตุผล แต่โมเดลขนาดเล็กก็สามารถเกินความเป็นไปได้ของโมเดลขนาดใหญ่ภายในช่วงที่มองเห็นได้
การค้นหามีความแข็งแกร่งเนื่องจากสามารถขยายได้อย่างโปร่งใสด้วยการเพิ่มขึ้นของการคำนวณและถ่ายโอนทรัพยากรจากหน่วยความจำไปสู่การคำนวณดังนั้นจึงบรรลุยอดเงินทุน เมื่อเร็ว ๆ นี้ DeepMind ได้มีความก้าวหน้าที่สำคัญในสาขาคณิตศาสตร์พิสูจน์พลังของการค้นหา
อย่างไรก็ตามความสำเร็จของการค้นหาครั้งแรกจำเป็นต้องดำเนินการประเมินคุณภาพสูงของผลลัพธ์ แบบจำลอง DeepMind ได้รับการดูแลอย่างมีประสิทธิภาพโดยการแปลงปัญหาทางคณิตศาสตร์ในภาษาธรรมชาติเพื่อสร้างการแสดงออกอย่างเป็นทางการ ในพื้นที่อื่น ๆ การเปิดงาน NLP เช่น "อีเมลสรุป" นั้นยากกว่าที่จะทำการค้นหาที่มีประสิทธิภาพมากขึ้น
การศึกษาครั้งนี้แสดงให้เห็นว่าการปรับปรุงประสิทธิภาพของแบบจำลองการสร้างในสาขาเฉพาะนั้นเกี่ยวข้องกับการประเมินและความสามารถในการค้นหาและการวิจัยในอนาคตสามารถสำรวจวิธีการปรับปรุงความสามารถเหล่านี้ผ่านสภาพแวดล้อมดิจิตอลซ้ำ ๆ
ที่อยู่วิทยานิพนธ์: https: //arxiv.org/pdf/2407.21787
โดยรวมแล้วการวิจัยนี้ให้มุมมองใหม่สำหรับการปรับปรุงประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ ในอนาคตวิธีการรวมกลยุทธ์การเรียนรู้และการค้นหาอย่างมีประสิทธิภาพจะเป็นทิศทางที่สำคัญสำหรับการพัฒนา LLM การเชื่อมโยงที่เชื่อมโยงของการศึกษานี้ได้รับการจัดเตรียมและผู้อ่านที่สนใจสามารถเข้าใจเพิ่มเติมได้