การเพิ่มขึ้นของสถาปัตยกรรม Transformer ได้ปฏิวัติขอบเขตการประมวลผลภาษาธรรมชาติ แต่ต้นทุนการคำนวณที่สูงได้กลายเป็นปัญหาคอขวดในการประมวลผลข้อความขนาดยาว เพื่อตอบสนองต่อปัญหานี้ บทความนี้จะแนะนำวิธีการใหม่ที่เรียกว่า Tree Attention ซึ่งลดความซับซ้อนในการคำนวณการเอาใจใส่ตนเองของโมเดล Transformer บริบทแบบยาวได้อย่างมีประสิทธิภาพผ่านการลดแบบทรี และใช้พลังของคลัสเตอร์ GPU สมัยใหม่อย่างเต็มที่ ปรับปรุงประสิทธิภาพการประมวลผลอย่างมาก
ในยุคแห่งการระเบิดของข้อมูลเช่นนี้ ปัญญาประดิษฐ์เปรียบเสมือนดวงดาวที่ส่องสว่าง ส่องสว่างท้องฟ้ายามค่ำคืนแห่งปัญญาของมนุษย์ ในบรรดาดวงดาวเหล่านี้ สถาปัตยกรรม Transformer ถือเป็นสถาปัตยกรรมที่น่าตื่นตาตื่นใจที่สุดอย่างไม่ต้องสงสัย ด้วยกลไกการเอาใจใส่ตนเองเป็นแกนหลัก จึงนำไปสู่ยุคใหม่ของการประมวลผลภาษาธรรมชาติ อย่างไรก็ตาม แม้แต่ดวงดาวที่สว่างที่สุดก็ยังมีมุมที่เข้าถึงได้ยาก สำหรับโมเดล Transformer ที่มีบริบทยาว การใช้ทรัพยากรสูงในการคำนวณการเอาใจใส่ตนเองจะกลายเป็นปัญหา ลองนึกภาพว่าคุณกำลังพยายามให้ AI เข้าใจบทความที่มีความยาวนับหมื่นคำ จะต้องนำมาเปรียบเทียบกับคำอื่นๆ ในบทความ ซึ่งปริมาณการคำนวณนั้นมหาศาลอย่างไม่ต้องสงสัย
เพื่อที่จะแก้ไขปัญหานี้ กลุ่มนักวิทยาศาสตร์จาก Zyphra และ EleutherAI ได้เสนอวิธีการใหม่ที่เรียกว่า Tree Attention
การเอาใจใส่ตนเองซึ่งเป็นแกนหลักของโมเดล Transformer ความซับซ้อนในการคำนวณจะเพิ่มขึ้นเป็นกำลังสองเมื่อความยาวของลำดับเพิ่มขึ้น สิ่งนี้กลายเป็นอุปสรรคที่ผ่านไม่ได้เมื่อต้องรับมือกับข้อความขนาดยาว โดยเฉพาะอย่างยิ่งสำหรับโมเดลภาษาขนาดใหญ่ (LLM)
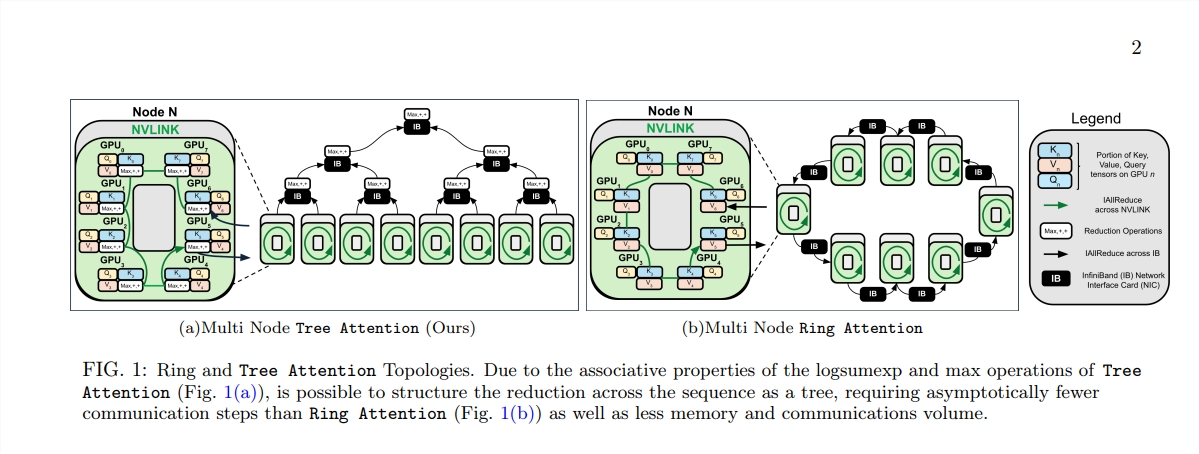
การกำเนิดของ Tree Attention ก็เหมือนกับการปลูกต้นไม้ที่สามารถคำนวณได้อย่างมีประสิทธิภาพในป่าการคำนวณนี้ โดยแบ่งย่อยการคำนวณความสนใจในตนเองออกเป็นงานคู่ขนานหลายงานโดยการลดขนาดต้นไม้ แต่ละงานก็เหมือนกับใบไม้บนต้นไม้ซึ่งรวมกันเป็นต้นไม้ที่สมบูรณ์
สิ่งที่น่าทึ่งยิ่งกว่านั้นคือผู้เสนอ Tree Attention ยังได้รับฟังก์ชันพลังงานของการเอาใจใส่ตนเอง ซึ่งไม่เพียงแต่ให้คำอธิบายแบบเบย์สำหรับการเอาใจใส่ตนเองเท่านั้น แต่ยังเชื่อมโยงอย่างใกล้ชิดกับแบบจำลองพลังงาน เช่น เครือข่าย Hopfield ที่โดดเด่น
Tree Attention ยังพิจารณาเป็นพิเศษเกี่ยวกับโทโพโลยีเครือข่ายของคลัสเตอร์ GPU สมัยใหม่ และลดข้อกำหนดการสื่อสารข้ามโหนดโดยใช้การเชื่อมต่อแบนด์วิธสูงภายในคลัสเตอร์อย่างชาญฉลาด ซึ่งจะช่วยปรับปรุงประสิทธิภาพการประมวลผล
นักวิทยาศาสตร์ได้ตรวจสอบประสิทธิภาพของ Tree Attention ผ่านชุดการทดลองต่างๆ ภายใต้ลำดับความยาวและจำนวน GPU ที่แตกต่างกัน ผลลัพธ์แสดงให้เห็นว่า Tree Attention เร็วกว่าวิธี Ring Attention ที่มีอยู่ถึง 8 เท่าเมื่อถอดรหัสบน GPU หลายตัว ในขณะที่ลดปริมาณการสื่อสารและการใช้หน่วยความจำสูงสุดลงอย่างมาก
ข้อเสนอ Tree Attention ไม่เพียงแต่มอบโซลูชันที่มีประสิทธิภาพสำหรับการคำนวณโมเดลความสนใจในบริบทแบบยาว แต่ยังให้มุมมองใหม่ให้เราเข้าใจกลไกภายในของโมเดล Transformer เนื่องจากเทคโนโลยี AI ยังคงก้าวหน้าอย่างต่อเนื่อง เราจึงมีเหตุผลที่เชื่อได้ว่า Tree Attention จะมีบทบาทสำคัญในการวิจัยและการประยุกต์ใช้ AI ในอนาคต
ที่อยู่กระดาษ: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
การเกิดขึ้นของ Tree Attention มอบโซลูชันที่มีประสิทธิภาพและเป็นนวัตกรรมในการแก้ปัญหาคอขวดในการคำนวณของการประมวลผลข้อความแบบยาว ซึ่งมีความสำคัญอย่างกว้างขวางสำหรับการทำความเข้าใจและการพัฒนาโมเดล Transformer ในอนาคต วิธีการนี้ไม่เพียงแต่ทำให้ประสิทธิภาพดีขึ้นอย่างมีนัยสำคัญเท่านั้น แต่ที่สำคัญกว่านั้นคือให้แนวคิดและแนวทางใหม่สำหรับการวิจัยในภายหลัง ซึ่งคุ้มค่ากับการศึกษาและอภิปรายในเชิงลึก