Andrej Karpathy ผู้มีอำนาจในด้าน AI เพิ่งตั้งคำถามเกี่ยวกับการเรียนรู้แบบเสริมกำลังตามความคิดเห็นของมนุษย์ (RLHF) โดยเชื่อว่านี่ไม่ใช่วิธีเดียวที่จะบรรลุ AI ระดับมนุษย์ที่แท้จริง ซึ่งก่อให้เกิดความกังวลอย่างกว้างขวางและการอภิปรายที่ดุเดือดในอุตสาหกรรม . เขาเชื่อว่า RLHF เป็นตัววัดชั่วคราวมากกว่าวิธีแก้ปัญหาขั้นสูงสุด และใช้ AlphaGo เป็นตัวอย่างในการเปรียบเทียบความแตกต่างในการแก้ปัญหาระหว่างการเรียนรู้แบบเสริมกำลังจริงกับ RLHF มุมมองของ Karpathy ให้มุมมองใหม่เกี่ยวกับทิศทางการวิจัย AI ในปัจจุบันอย่างไม่ต้องสงสัย และยังนำความท้าทายใหม่มาสู่การพัฒนา AI ในอนาคตอีกด้วย
เมื่อเร็ว ๆ นี้ Andrej Karpathy นักวิจัยที่มีชื่อเสียงในอุตสาหกรรม AI ได้หยิบยกมุมมองที่ขัดแย้งกัน เขาเชื่อว่าการเรียนรู้แบบเสริมกำลังที่ได้รับการยกย่องอย่างกว้างขวางในปัจจุบันโดยอาศัยเทคโนโลยีตอบรับของมนุษย์ (RLHF) อาจไม่ใช่วิธีเดียวที่จะบรรลุเป้าหมาย ความสามารถในการแก้ไขปัญหาระดับมนุษย์อย่างแท้จริง คำพูดนี้ทิ้งระเบิดหนักอย่างไม่ต้องสงสัยในสาขาการวิจัย AI ในปัจจุบัน
ครั้งหนึ่ง RLHF ได้รับการยกย่องว่าเป็นปัจจัยสำคัญในความสำเร็จของโมเดลภาษาขนาดใหญ่ (LLM) เช่น ChatGPT และได้รับการยกย่องว่าเป็นอาวุธลับที่ให้ความสามารถในการเข้าใจ การเชื่อฟัง และปฏิสัมพันธ์ที่เป็นธรรมชาติของ AI ในกระบวนการฝึกอบรม AI แบบดั้งเดิม RLHF มักจะใช้เป็นลิงก์สุดท้ายหลังจากการฝึกอบรมล่วงหน้าและการปรับแต่งแบบละเอียดภายใต้การดูแล (SFT) อย่างไรก็ตาม Karpathy เปรียบเทียบ RLHF กับปัญหาคอขวดและมาตรการหยุดชะงัก โดยเชื่อว่ายังห่างไกลจากวิธีแก้ปัญหาขั้นสูงสุดสำหรับวิวัฒนาการ AI
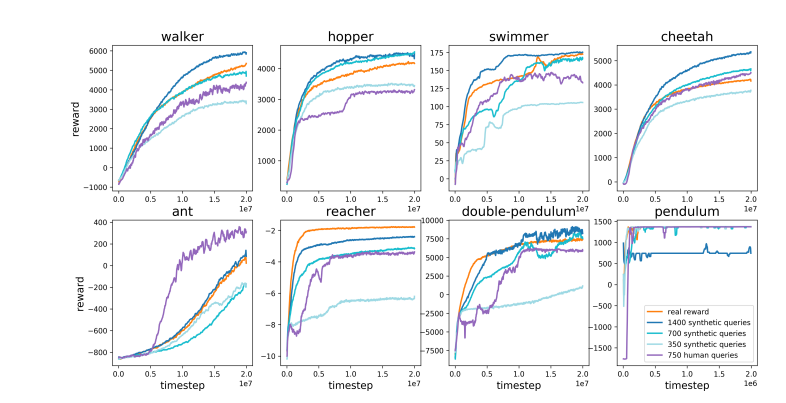
Karpathy เปรียบเทียบ RLHF กับ AlphaGo ของ DeepMind อย่างชาญฉลาด AlphaGo ใช้สิ่งที่เขาเรียกว่าเทคโนโลยี RL (การเรียนรู้แบบเสริมกำลัง) ที่แท้จริง และด้วยการเล่นกับตัวเองอย่างต่อเนื่องและเพิ่มอัตราการชนะให้สูงสุด ในที่สุดมันก็แซงหน้าผู้เล่นหมากรุกชั้นนำของมนุษย์โดยปราศจากการแทรกแซงของมนุษย์ วิธีการนี้บรรลุถึงระดับประสิทธิภาพเหนือมนุษย์โดยการเพิ่มประสิทธิภาพโครงข่ายประสาทเทียมเพื่อเรียนรู้โดยตรงจากผลลัพธ์ของเกม
ในทางตรงกันข้าม Karpathy เชื่อว่า RLHF เป็นการเลียนแบบความชอบของมนุษย์มากกว่าการแก้ปัญหาจริงๆ เขาจินตนาการว่าหาก AlphaGo ใช้วิธีการ RLHF ผู้ประเมินที่เป็นมนุษย์จะต้องเปรียบเทียบสถานะของเกมจำนวนมากและเลือกการตั้งค่าที่ต้องการ กระบวนการนี้อาจต้องมีการเปรียบเทียบมากถึง 100,000 ครั้งเพื่อฝึกโมเดลรางวัลที่เลียนแบบการตรวจสอบบรรยากาศของมนุษย์ อย่างไรก็ตาม การตัดสินตามบรรยากาศดังกล่าวสามารถสร้างผลลัพธ์ที่ทำให้เข้าใจผิดได้ในเกมที่เข้มงวดเช่น Go
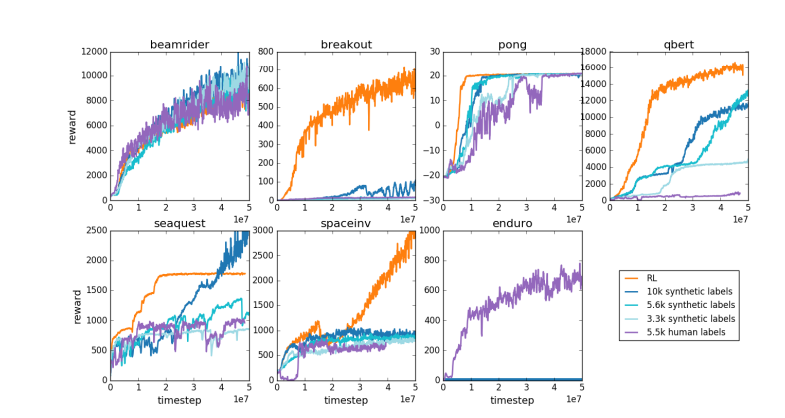
ด้วยเหตุผลเดียวกัน รูปแบบการให้รางวัล LLM ในปัจจุบันจึงทำงานในลักษณะเดียวกัน โดยมีแนวโน้มที่จะจัดอันดับคำตอบที่สูงซึ่งผู้ประเมินที่เป็นมนุษย์ดูเหมือนจะชอบมากกว่าในทางสถิติ นี่เป็นตัวแทนที่ตอบสนองความต้องการแบบผิวเผินของมนุษย์มากกว่าการสะท้อนความสามารถในการแก้ปัญหาที่แท้จริง ที่น่ากังวลยิ่งกว่านั้นคือโมเดลอาจเรียนรู้วิธีใช้ประโยชน์จากฟังก์ชันการให้รางวัลนี้ได้อย่างรวดเร็ว แทนที่จะปรับปรุงความสามารถของตนจริงๆ
Karpathy ชี้ให้เห็นว่าในขณะที่การเรียนรู้แบบเสริมกำลังทำงานได้ดีในสภาพแวดล้อมแบบปิดเช่น Go แต่การเรียนรู้แบบเสริมกำลังที่แท้จริงยังคงเป็นเรื่องยากสำหรับงานภาษาเปิด สาเหตุหลักมาจากเป็นการยากที่จะกำหนดเป้าหมายที่ชัดเจนและกลไกการให้รางวัลในงานที่เปิดอยู่ จะให้รางวัลตามวัตถุประสงค์สำหรับงานต่างๆ เช่น การสรุปบทความ ตอบคำถามที่คลุมเครือเกี่ยวกับการติดตั้ง pip การเล่าเรื่องตลก หรือการเขียนโค้ด Java ใหม่ลงใน Python ได้อย่างไร Karpathy ถามคำถามที่ลึกซึ้งนี้ และการดำเนินไปในทิศทางนี้ไม่ใช่หลักการ มันเป็นไปไม่ได้ แต่ก็ไม่ใช่เรื่องง่ายเช่นกัน และต้องใช้ความคิดสร้างสรรค์บ้าง

อย่างไรก็ตาม Karpathy เชื่อว่าหากปัญหาที่ยากลำบากนี้สามารถแก้ไขได้ แบบจำลองภาษาก็มีศักยภาพที่จะจับคู่ได้อย่างแท้จริงหรือเหนือกว่าความสามารถในการแก้ปัญหาของมนุษย์ มุมมองนี้เกิดขึ้นพร้อมกับบทความล่าสุดที่เผยแพร่โดย Google DeepMind ซึ่งชี้ให้เห็นว่าการเปิดกว้างเป็นรากฐานของปัญญาประดิษฐ์ทั่วไป (AGI)
ในฐานะหนึ่งในผู้เชี่ยวชาญด้าน AI อาวุโสหลายคนที่ออกจาก OpenAI ในปีนี้ Karpathy กำลังทำงานในสตาร์ทอัพด้าน AI เพื่อการศึกษาของเขาเอง คำพูดของเขาได้แทรกมิติใหม่ของการคิดเข้าไปในสาขาการวิจัย AI อย่างไม่ต้องสงสัย และให้ข้อมูลเชิงลึกที่มีคุณค่าเกี่ยวกับทิศทางการพัฒนา AI ในอนาคต
มุมมองของ Karpathy จุดประกายให้เกิดการอภิปรายอย่างกว้างขวางในอุตสาหกรรม ผู้สนับสนุนเชื่อว่าเขาเปิดเผยประเด็นสำคัญในการวิจัย AI ในปัจจุบัน ซึ่งก็คือจะทำให้ AI สามารถแก้ไขปัญหาที่ซับซ้อนได้อย่างแท้จริง แทนที่จะเลียนแบบพฤติกรรมของมนุษย์เท่านั้น ฝ่ายตรงข้ามกังวลว่าการละทิ้ง RLHF ก่อนเวลาอันควรอาจนำไปสู่การเบี่ยงเบนไปในทิศทางของการพัฒนา AI
ที่อยู่กระดาษ: https://arxiv.org/pdf/1706.03741
มุมมองของ Karpathy ก่อให้เกิดการอภิปรายเชิงลึกเกี่ยวกับทิศทางการพัฒนาในอนาคตของ AI ความสงสัยของเขาเกี่ยวกับ RLHF กระตุ้นให้นักวิจัยตรวจสอบวิธีการฝึกอบรม AI ในปัจจุบันอีกครั้ง และสำรวจเส้นทางที่มีประสิทธิภาพมากขึ้น โดยมีเป้าหมายสูงสุดในการบรรลุปัญญาประดิษฐ์ที่แท้จริง