ความก้าวหน้าของโมเดลภาษาขนาดใหญ่ (LLM) นั้นน่าประทับใจ แต่ก็มีข้อบกพร่องที่ไม่คาดคิดจากปัญหาง่ายๆ บางประการ Andrej Karpathy ชี้ให้เห็นปรากฏการณ์ของ "สติปัญญาหยัก" อย่างชัดเจนนั่นคือ LLM มีความสามารถในการทำงานที่ซับซ้อน แต่มักทำผิดพลาดกับปัญหาง่ายๆ สิ่งนี้กระตุ้นให้เกิดความคิดเชิงลึกเกี่ยวกับข้อบกพร่องที่สำคัญของ LLM และแนวทางการปรับปรุงในอนาคต บทความนี้จะอธิบายรายละเอียดและสำรวจวิธีการใช้ LLM ให้ดีขึ้นและหลีกเลี่ยงข้อจำกัดต่างๆ
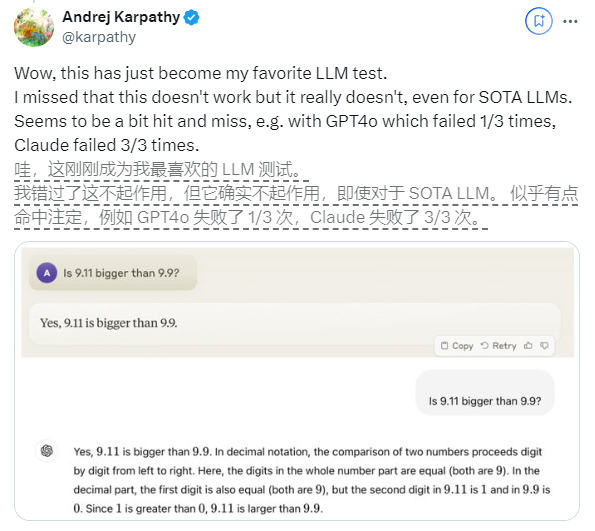
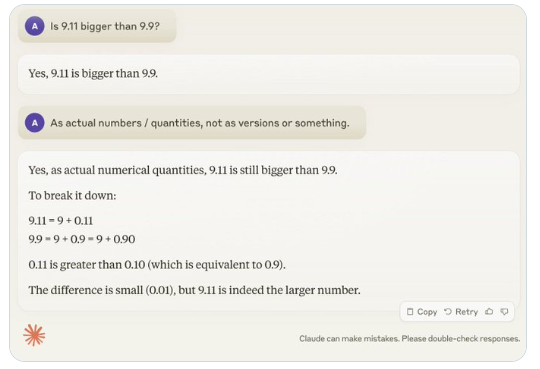
เมื่อเร็วๆ นี้ คำถามที่ดูเหมือนง่ายว่า "9.11 ใหญ่กว่า 9.9 หรือไม่" ได้รับความสนใจอย่างกว้างขวางทั่วโลก ปรากฏการณ์นี้ดึงดูดความสนใจของ Andrej Karpathy ผู้เชี่ยวชาญด้าน AI โดยเริ่มจากปัญหานี้ เขาได้พูดคุยอย่างลึกซึ้งเกี่ยวกับข้อบกพร่องที่สำคัญและทิศทางการปรับปรุงในอนาคตของเทคโนโลยีโมเดลขนาดใหญ่ในปัจจุบัน
Karpathy เรียกปรากฏการณ์นี้ว่า "ความฉลาดแบบหยัก" หรือ "ความฉลาดแบบหยัก" โดยชี้ให้เห็นว่า แม้ว่า LLM ที่ล้ำสมัยจะสามารถทำงานที่ซับซ้อนได้หลายอย่าง เช่น การแก้ปัญหาทางคณิตศาสตร์ที่ยาก แต่ก็ล้มเหลวในบางงานที่ดูเหมือนง่าย แก้ไขปัญหาได้ไม่ดี และความไม่สมดุลของสติปัญญานี้คล้ายกับรูปร่างของฟันเลื่อย
ตัวอย่างเช่น Noam Brown นักวิจัยของ OpenAI พบว่า LLM ทำงานได้ไม่ดีในเกม Tic-Tac-Toe โดยที่โมเดลไม่สามารถตัดสินใจได้อย่างถูกต้องแม้ว่าผู้ใช้กำลังจะชนะก็ตาม Karpathy เชื่อว่านี่เป็นเพราะโมเดลทำการตัดสินใจที่ "ไม่ยุติธรรม" ในขณะที่ Noam เชื่อว่านี่อาจเกิดจากการขาดการอภิปรายที่เกี่ยวข้องเกี่ยวกับกลยุทธ์ในข้อมูลการฝึกอบรม
อีกตัวอย่างหนึ่งคือข้อผิดพลาดที่ LLM เกิดขึ้นเมื่อนับจำนวนตัวอักษรและตัวเลข แม้แต่ Llama 3.1 รุ่นล่าสุดก็ให้คำตอบที่ผิดสำหรับคำถามง่ายๆ Karpathy อธิบายว่าสิ่งนี้เกิดจากการขาด "ความรู้ในตนเอง" ของ LLM กล่าวคือ โมเดลไม่สามารถแยกแยะได้ว่าอะไรทำได้และทำไม่ได้ ส่งผลให้โมเดล "มั่นใจอย่างมั่นใจ" เมื่อเผชิญกับงาน
เพื่อแก้ไขปัญหานี้ Karpathy กล่าวถึงวิธีแก้ปัญหาที่เสนอในรายงาน Llama3.1 ที่เผยแพร่โดย Meta บทความนี้แนะนำให้บรรลุการจัดตำแหน่งแบบจำลองในขั้นตอนหลังการฝึกอบรม เพื่อให้แบบจำลองพัฒนาความตระหนักรู้ในตนเองและรู้ว่าอะไรคือสิ่งที่รู้ ไม่สามารถกำจัดปัญหาภาพลวงตาได้ง่ายๆ ด้วยการเพิ่มความรู้ตามข้อเท็จจริง ทีมลามะเสนอวิธีการฝึกอบรมที่เรียกว่า "การตรวจจับความรู้" ซึ่งสนับสนุนให้โมเดลตอบคำถามที่เข้าใจเท่านั้น และปฏิเสธที่จะสร้างคำตอบที่ไม่แน่นอน
Karpathy เชื่อว่าถึงแม้จะมีปัญหามากมายเกี่ยวกับความสามารถในปัจจุบันของ AI แต่สิ่งเหล่านี้ไม่ถือเป็นข้อบกพร่องพื้นฐานและมีวิธีแก้ไขที่เป็นไปได้ เขาเสนอว่าแนวคิดการฝึกอบรม AI ในปัจจุบันเป็นเพียงการ "เลียนแบบฉลากของมนุษย์และขยายขนาด" เพื่อพัฒนาความฉลาดของ AI ต่อไป จำเป็นต้องมีการทำงานมากขึ้นตลอดทั้งกลุ่มการพัฒนา
จนกว่าปัญหาจะได้รับการแก้ไขอย่างสมบูรณ์ หาก LLM ถูกใช้ในการผลิต ควรจำกัดไว้เฉพาะงานที่พวกเขาทำได้ดี ระวัง "ขอบหยัก" และให้มนุษย์มีส่วนร่วมตลอดเวลา ด้วยวิธีนี้ เราจะสามารถใช้ประโยชน์จากศักยภาพของ AI ได้ดีขึ้น ในขณะเดียวกันก็หลีกเลี่ยงความเสี่ยงที่เกิดจากข้อจำกัดของมัน
โดยรวมแล้ว “ความฉลาดแบบหยัก” ของ LLM ถือเป็นความท้าทายที่ AI เผชิญอยู่ในปัจจุบัน แต่ก็ผ่านไม่ได้ ด้วยการปรับปรุงวิธีการฝึกอบรม เพิ่มความตระหนักรู้ในตนเองของแบบจำลอง และนำไปใช้อย่างระมัดระวังกับสถานการณ์จริง เราจะสามารถใช้ประโยชน์จากข้อดีของ LLM ได้ดีขึ้น และส่งเสริมการพัฒนาเทคโนโลยีปัญญาประดิษฐ์อย่างต่อเนื่อง