ในสาขา AI ที่เฟื่องฟู วิธีการเก็บข้อมูลกำลังกลายเป็นจุดสนใจมากขึ้น บทความนี้สำรวจข้อโต้แย้งที่เกิดจากพฤติกรรมการขูดข้อมูลขนาดใหญ่ของทีม Claude ภายใต้บริษัท AI Anthropic โปรแกรมรวบรวมข้อมูลของทีม Claude ClaudeBot รวบรวมข้อมูลจำนวนมากจากหลายเว็บไซต์โดยไม่ได้รับอนุญาต ซึ่งไม่เพียงแต่ละเมิดกฎข้อบังคับของเว็บไซต์เท่านั้น แต่ยังทำให้เกิดการใช้ทรัพยากรเซิร์ฟเวอร์จำนวนมาก ทำให้เกิดการวิพากษ์วิจารณ์และข้อกังวลอย่างกว้างขวาง เหตุการณ์นี้เน้นย้ำถึงความขัดแย้งระหว่างการพัฒนา AI และการคุ้มครองลิขสิทธิ์ข้อมูล ส่งผลให้อุตสาหกรรมต้องคิดใหม่เกี่ยวกับจริยธรรมและบรรทัดฐานทางกฎหมายของการรวบรวมข้อมูล
สาเหตุของเหตุการณ์คือโปรแกรมรวบรวมข้อมูลของทีม Claude เยี่ยมชมเซิร์ฟเวอร์ของบริษัท 1 ล้านครั้งภายใน 24 ชั่วโมง และรวบรวมข้อมูลเนื้อหาเว็บไซต์ได้ฟรี พฤติกรรมนี้ไม่เพียงแต่เพิกเฉยต่อประกาศห้ามรวบรวมข้อมูลของเว็บไซต์อย่างโจ่งแจ้งเท่านั้น แต่ยังบังคับใช้ทรัพยากรเซิร์ฟเวอร์จำนวนมากอีกด้วย
แม้จะมีความพยายามอย่างเต็มที่เพื่อปกป้องตัวเอง แต่ท้ายที่สุดแล้วบริษัทที่ตกเป็นเหยื่อก็ล้มเหลวในการป้องกันไม่ให้ทีมของ Claude ขโมยข้อมูล ผู้นำบริษัทแสดงความโกรธต่อโซเชียลมีเดียเพื่อประณามการกระทำของทีมโคลด ชาวเน็ตจำนวนมากยังแสดงความไม่พอใจ และบางคนถึงกับแนะนำให้ใช้คำว่าขโมยเพื่ออธิบายพฤติกรรมนี้
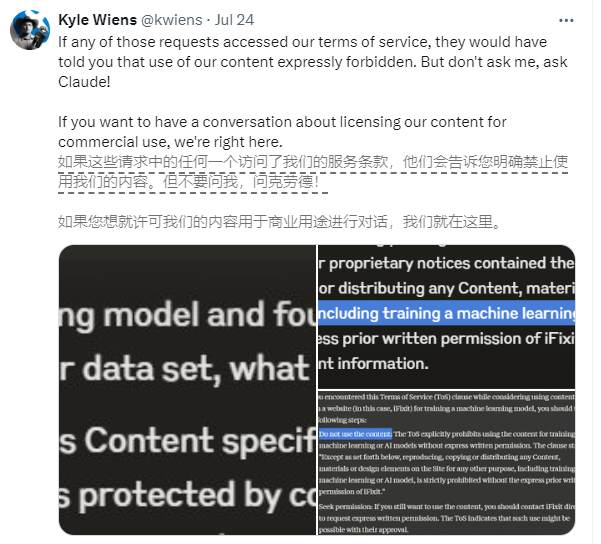
บริษัทที่เกี่ยวข้องคือ iFixit ซึ่งเป็นเว็บไซต์อีคอมเมิร์ซและวิธีใช้ของอเมริกา iFixit นำเสนอคู่มือการซ่อมออนไลน์ฟรีหลายล้านหน้า ซึ่งครอบคลุมถึงอุปกรณ์อิเล็กทรอนิกส์และอุปกรณ์สำหรับผู้บริโภค อย่างไรก็ตาม iFixit ค้นพบว่าโปรแกรมรวบรวมข้อมูลของ Claude ClaudeBot เริ่มคำขอจำนวนมากในช่วงเวลาสั้นๆ โดยเข้าถึงไฟล์ขนาด 10TB ในหนึ่งวัน และรวมทั้งหมด 73TB ตลอดทั้งเดือนพฤษภาคม
Kyle Wiens ซีอีโอของ iFixit กล่าวว่า ClaudeBot ขโมยข้อมูลทั้งหมดโดยไม่ได้รับอนุญาตและครอบครองทรัพยากรเซิร์ฟเวอร์ แม้ว่า iFixit จะระบุอย่างชัดเจนบนเว็บไซต์ว่าห้ามคัดลอกข้อมูลที่ไม่ได้รับอนุญาต แต่ดูเหมือนว่าทีมงานของ Claude จะเมินเฉยต่อเรื่องนี้
พฤติกรรมของทีมโคลดไม่ซ้ำกัน ในเดือนเมษายนของปีนี้ ฟอรัม Linux Mint ยังประสบปัญหาการเข้าชมบ่อยครั้งจาก ClaudeBot ทำให้ฟอรัมทำงานช้าหรืออาจขัดข้อง นอกจากนี้ ยังมีเสียงบางส่วนชี้ให้เห็นว่านอกเหนือจาก GPT ของ Claude และ OpenAI แล้ว ยังมีบริษัท AI อื่นๆ อีกหลายแห่งที่เพิกเฉยต่อการตั้งค่า robots.txt ของเว็บไซต์และบังคับให้ดึงข้อมูล
เมื่อเผชิญกับสถานการณ์เช่นนี้ จึงได้รับการแนะนำให้เจ้าของเว็บไซต์เพิ่มเนื้อหาปลอมที่มีข้อมูลที่สามารถติดตามได้หรือข้อมูลเฉพาะลงในเพจเพื่อตรวจสอบว่าข้อมูลถูกคัดลอกอย่างผิดกฎหมายหรือไม่ iFixit ได้ดำเนินการตามขั้นตอนนี้จริง ๆ และพบว่าข้อมูลของพวกเขาไม่เพียงแต่ถูกคัดลอกโดย Claude เท่านั้น แต่ยังถูกคัดลอกโดย OpenAI ด้วย
เหตุการณ์ดังกล่าวกระตุ้นให้เกิดการอภิปรายอย่างกว้างขวางเกี่ยวกับแนวปฏิบัติในการคัดลอกข้อมูลของบริษัท AI ในด้านหนึ่ง การพัฒนา AI ต้องใช้ข้อมูลจำนวนมากเพื่อรองรับ ในทางกลับกัน การเก็บข้อมูลควรเคารพสิทธิและกฎระเบียบของเจ้าของเว็บไซต์ด้วย วิธีค้นหาสมดุลระหว่างการส่งเสริมความก้าวหน้าทางเทคโนโลยีและการปกป้องลิขสิทธิ์เป็นคำถามที่ทั้งอุตสาหกรรมต้องคำนึงถึง
เหตุการณ์การแย่งชิงข้อมูลของทีมของ Claude ส่งเสียงเตือน โดยเตือนบริษัท AI ว่าในขณะที่ดำเนินการตามความก้าวหน้าทางเทคโนโลยี พวกเขาจะต้องเคารพสิทธิ์ในทรัพย์สินทางปัญญา ปฏิบัติตามกฎหมายและข้อบังคับ และกระตือรือร้นสำรวจวิธีที่สอดคล้องเพื่อรับข้อมูล ด้วยวิธีนี้เท่านั้นที่เราสามารถรับประกันการพัฒนาเทคโนโลยี AI ที่ดี และหลีกเลี่ยงความเสียหายต่อชื่อเสียงของอุตสาหกรรมและความไว้วางใจของสาธารณะเนื่องจากพฤติกรรมที่ไม่เหมาะสม