ประสบการณ์ของ Meta ในการฝึกอบรมโมเดลภาษาขนาดใหญ่ Llama 3.1 แสดงให้เราเห็นถึงความท้าทายและโอกาสที่ไม่เคยมีมาก่อนในการพัฒนา AI กลุ่ม GPU ขนาดใหญ่ 16,384 ตัวประสบความล้มเหลวโดยเฉลี่ยทุก 3 ชั่วโมงในช่วงระยะเวลาการฝึกอบรม 54 วัน สิ่งนี้ไม่เพียงเน้นการเติบโตอย่างรวดเร็วของขนาดของโมเดล AI แต่ยังเผยให้เห็นปัญหาคอขวดขนาดใหญ่ในความเสถียรของซูเปอร์คอมพิวเตอร์ ระบบ. บทความนี้จะเจาะลึกถึงความท้าทายที่ Meta พบในระหว่างกระบวนการฝึกอบรม Llama 3.1 กลยุทธ์ที่พวกเขานำมาใช้เพื่อจัดการกับความท้าทายเหล่านี้ และวิเคราะห์ผลกระทบของมันต่ออุตสาหกรรม AI ทั้งหมด
ในโลกแห่งปัญญาประดิษฐ์ ทุกความก้าวหน้ามาพร้อมกับข้อมูลที่ทำให้ต้องอ้าปากค้าง ลองนึกภาพว่ามี GPU 16,384 ตัวทำงานพร้อมกัน นี่ไม่ใช่ฉากในภาพยนตร์นิยายวิทยาศาสตร์ แต่เป็นการแสดง Meta ที่แท้จริงเมื่อฝึกโมเดล Llama3.1 ล่าสุด อย่างไรก็ตาม ความล้มเหลวที่เกิดขึ้นโดยเฉลี่ยทุกๆ 3 ชั่วโมงอยู่เบื้องหลังงานฉลองทางเทคโนโลยีนี้ ตัวเลขอันน่าทึ่งนี้ไม่เพียงแต่แสดงให้เห็นถึงความเร็วของการพัฒนา AI เท่านั้น แต่ยังเผยให้เห็นถึงความท้าทายครั้งใหญ่ที่เทคโนโลยีในปัจจุบันต้องเผชิญอีกด้วย
จาก GPU 2,028 ตัวที่ใช้ใน Llama1 ไปจนถึง 16,384 GPU ที่ใช้ใน Llama3.1 การเติบโตแบบก้าวกระโดดนี้ไม่เพียงแต่เป็นการเปลี่ยนแปลงปริมาณเท่านั้น แต่ยังเป็นความท้าทายอย่างยิ่งต่อความเสถียรของระบบซูเปอร์คอมพิวเตอร์ที่มีอยู่ด้วย ข้อมูลการวิจัยของ Meta แสดงให้เห็นว่าในระหว่างรอบการฝึกอบรม 54 วันของ Llama3.1 มีความล้มเหลวของส่วนประกอบที่ไม่คาดคิดทั้งหมด 419 ครั้งเกิดขึ้น ประมาณครึ่งหนึ่งเกี่ยวข้องกับ H100 GPU และหน่วยความจำ HBM3 ข้อมูลนี้ทำให้เราต้องคิดว่า: ในขณะที่แสวงหาความก้าวหน้าในประสิทธิภาพ AI ความน่าเชื่อถือของระบบได้รับการปรับปรุงไปพร้อม ๆ กันหรือไม่?
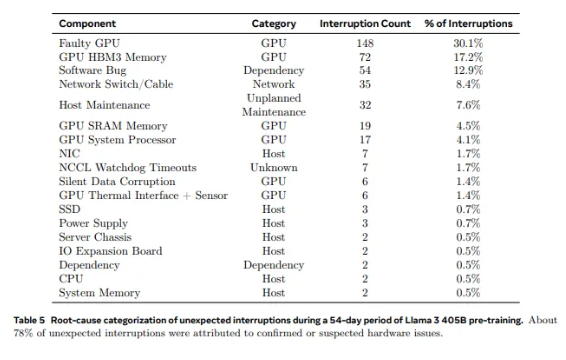
ในความเป็นจริง มีข้อเท็จจริงที่ไม่อาจโต้แย้งได้ในสาขาซูเปอร์คอมพิวเตอร์: ยิ่งมีขนาดใหญ่เท่าใด การหลีกเลี่ยงความล้มเหลวก็จะยิ่งยากขึ้นเท่านั้น คลัสเตอร์การฝึกซ้อม Llama 3.1 ของ Meta ประกอบด้วยโปรเซสเซอร์หลายหมื่นตัว ชิปอื่นๆ หลายแสนตัว และสายเคเบิลยาวหลายร้อยไมล์ ซึ่งเป็นระดับความซับซ้อนที่เทียบได้กับโครงข่ายประสาทเทียมของเมืองเล็กๆ ในยักษ์ใหญ่เช่นนี้ การทำงานผิดปกติดูเหมือนจะเป็นเรื่องปกติ
เมื่อต้องเผชิญกับความล้มเหลวบ่อยครั้ง ทีม Meta ก็ไม่ได้ทำอะไรไม่ถูก พวกเขานำกลยุทธ์การรับมือมาใช้ เช่น การลดเวลาในการเริ่มต้นงานและจุดตรวจสอบ การพัฒนาเครื่องมือวินิจฉัยที่เป็นกรรมสิทธิ์ การใช้ประโยชน์จากเครื่องบันทึกการบิน NCCL ของ PyTorch เป็นต้น มาตรการเหล่านี้ไม่เพียงปรับปรุงความทนทานต่อข้อผิดพลาดของระบบ แต่ยังเพิ่มความสามารถในการประมวลผลแบบอัตโนมัติอีกด้วย วิศวกรของ Meta เปรียบเสมือนนักดับเพลิงยุคใหม่ พร้อมที่จะดับไฟที่อาจขัดขวางกระบวนการฝึกอบรม
อย่างไรก็ตาม ความท้าทายไม่ได้มาจากตัวฮาร์ดแวร์เท่านั้น ปัจจัยด้านสิ่งแวดล้อมและความผันผวนของการใช้พลังงานยังนำมาซึ่งความท้าทายที่ไม่คาดคิดมาสู่คลัสเตอร์ซูเปอร์คอมพิวเตอร์ ทีม Meta พบว่าการเปลี่ยนแปลงของอุณหภูมิทั้งกลางวันและกลางคืนและความผันผวนอย่างมากในการใช้พลังงานของ GPU จะมีผลกระทบอย่างมากต่อประสิทธิภาพการฝึกอบรม การค้นพบนี้เตือนเราว่าในขณะที่แสวงหาความก้าวหน้าทางเทคโนโลยี เราไม่สามารถละเลยความสำคัญของการจัดการสิ่งแวดล้อมและการใช้พลังงานได้
กระบวนการฝึกอบรมของ Llama3.1 เรียกได้ว่าเป็นการทดสอบขั้นสูงสุดเกี่ยวกับความเสถียรและความน่าเชื่อถือของระบบซูเปอร์คอมพิวเตอร์ กลยุทธ์ที่ทีม Meta นำมาใช้เพื่อจัดการกับความท้าทายและเครื่องมืออัตโนมัติที่พัฒนาขึ้นมอบประสบการณ์อันมีค่าและแรงบันดาลใจสำหรับอุตสาหกรรม AI ทั้งหมด แม้จะมีความยากลำบาก แต่เรามีเหตุผลที่เชื่อได้ว่าด้วยความก้าวหน้าทางเทคโนโลยีอย่างต่อเนื่อง ระบบซูเปอร์คอมพิวเตอร์ในอนาคตจะมีประสิทธิภาพและมีเสถียรภาพมากขึ้น
ในยุคของการพัฒนาอย่างรวดเร็วของเทคโนโลยี AI ความพยายามของ Meta ถือเป็นการผจญภัยที่กล้าหาญอย่างไม่ต้องสงสัย ไม่เพียงแต่ผลักดันขอบเขตประสิทธิภาพของโมเดล AI เท่านั้น แต่ยังแสดงให้เราเห็นถึงความท้าทายที่แท้จริงที่เราเผชิญในการบรรลุขีดจำกัด ให้เราตั้งตารอความเป็นไปได้อันไม่มีที่สิ้นสุดที่มาจากเทคโนโลยี AI และในขณะเดียวกันก็ชื่นชมวิศวกรที่ทำงานอย่างไม่รู้จักเหน็ดเหนื่อยในระดับแนวหน้าของเทคโนโลยี ทุกความพยายาม ทุกความล้มเหลว และทุกความก้าวหน้าที่พวกเขาทำ ปูทางไปสู่ความก้าวหน้าทางเทคโนโลยีของมนุษย์
อ้างอิง:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- ความล้มเหลวหนึ่งครั้งทุก ๆ สามชั่วโมงสำหรับ metas-16384-gpu-training-cluster
กรณีการฝึกอบรมของ Llama 3.1 ให้บทเรียนอันมีค่าแก่เราและชี้ให้เห็นทิศทางการพัฒนาในอนาคตของระบบซูเปอร์คอมพิวเตอร์: ในขณะที่ดำเนินการตามประสิทธิภาพ เราต้องให้ความสำคัญอย่างยิ่งต่อความเสถียรและความน่าเชื่อถือของระบบ และสำรวจกลยุทธ์อย่างแข็งขันเพื่อจัดการกับความล้มเหลวต่างๆ ด้วยวิธีนี้เท่านั้นที่เราสามารถรับประกันการพัฒนาเทคโนโลยี AI อย่างต่อเนื่องและมั่นคงและเป็นประโยชน์ต่อมนุษยชาติ