NVIDIA เพิ่งเปิดตัวซีรีส์ Minitron ของโมเดลภาษาขนาดเล็ก รวมถึงเวอร์ชัน 4B และ 8B การเคลื่อนไหวนี้มีจุดมุ่งหมายเพื่อลดค่าใช้จ่ายในการฝึกอบรมและปรับใช้โมเดลภาษาขนาดใหญ่ และช่วยให้นักพัฒนาจำนวนมากขึ้นสามารถใช้เทคโนโลยีขั้นสูงนี้ได้อย่างง่ายดาย ด้วยเทคโนโลยี "การตัดแต่งกิ่ง" และ "การกลั่นกรองความรู้" โมเดล Minitron สามารถลดขนาดโมเดลลงได้อย่างมาก ในขณะที่ยังคงรักษาประสิทธิภาพไว้ได้เทียบเท่ากับรุ่นใหญ่ และยังเหนือกว่ารุ่นอื่นๆ ที่รู้จักกันดีในบางตัวชี้วัดอีกด้วย นี่เป็นสิ่งสำคัญอย่างยิ่งในการส่งเสริมความนิยมของเทคโนโลยีปัญญาประดิษฐ์
ล่าสุด NVIDIA ได้สร้างการเคลื่อนไหวใหม่ในด้านปัญญาประดิษฐ์ พวกเขาได้เปิดตัวซีรีส์ Minitron ของโมเดลภาษาขนาดเล็ก รวมถึงเวอร์ชัน 4B และ 8B โมเดลเหล่านี้ไม่เพียงแต่เพิ่มความเร็วการฝึกอบรมได้เต็ม 40 เท่า แต่ยังทำให้นักพัฒนาสามารถใช้โมเดลเหล่านี้กับแอปพลิเคชันต่างๆ ได้ง่ายขึ้น เช่น การแปล การวิเคราะห์ความรู้สึก และ AI การสนทนา
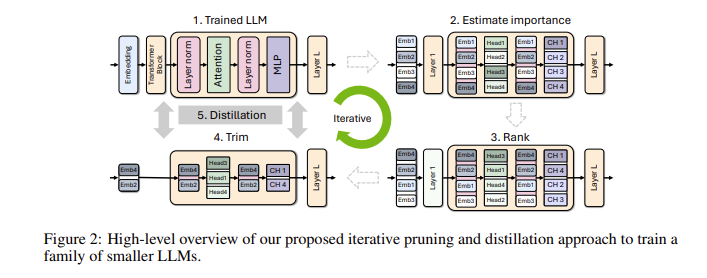
คุณอาจถามว่าทำไมโมเดลภาษาขนาดเล็กจึงมีความสำคัญ ที่จริงแล้ว แม้ว่าโมเดลภาษาขนาดใหญ่แบบดั้งเดิมจะมีประสิทธิภาพที่ดีเยี่ยม แต่ค่าใช้จ่ายในการฝึกอบรมและการใช้งานก็สูงมาก และมักต้องใช้ทรัพยากรคอมพิวเตอร์และข้อมูลจำนวนมาก เพื่อทำให้เทคโนโลยีขั้นสูงเหล่านี้มีราคาที่เอื้อมถึงสำหรับผู้คนจำนวนมาก ทีมวิจัยของ NVIDIA ได้คิดค้นวิธีการที่ยอดเยี่ยม: การผสมผสานเทคโนโลยีสองอย่างเข้าด้วยกัน: "การตัดแต่งกิ่ง" และ "การกลั่นกรองความรู้" เพื่อลดขนาดของแบบจำลองอย่างมีประสิทธิภาพ
โดยเฉพาะอย่างยิ่ง นักวิจัยจะเริ่มจากแบบจำลองขนาดใหญ่ที่มีอยู่แล้วตัดทิ้ง พวกเขาประเมินความสำคัญของแต่ละเซลล์ประสาท เลเยอร์ หรือส่วนหัวของความสนใจในแบบจำลอง และลบสิ่งเหล่านั้นที่มีความสำคัญน้อยกว่าออกไป ด้วยวิธีนี้ โมเดลจะเล็กลงมาก และทรัพยากรและเวลาที่จำเป็นสำหรับการฝึกอบรมก็ลดลงอย่างมากเช่นกัน ถัดไป พวกเขายังจะใช้ชุดข้อมูลขนาดเล็กเพื่อฝึกอบรมการกลั่นกรองความรู้เกี่ยวกับแบบจำลองที่ถูกตัดออกเพื่อคืนความแม่นยำของแบบจำลอง น่าแปลกที่กระบวนการนี้ไม่เพียงแต่ช่วยประหยัดเงิน แต่ยังช่วยปรับปรุงประสิทธิภาพของโมเดลด้วย!
ในการทดสอบจริง ทีมวิจัยของ NVIDIA ได้รับผลลัพธ์ที่ดีในตระกูลโมเดล Nemotron-4 พวกเขาประสบความสำเร็จในการลดขนาดโมเดลลง 2 ถึง 4 เท่าในขณะที่ยังคงประสิทธิภาพที่ใกล้เคียงกัน สิ่งที่น่าตื่นเต้นยิ่งกว่านั้นคือรุ่น 8B เหนือกว่ารุ่นอื่นๆ ที่รู้จักกันดี เช่น Mistral7B และ LLaMa-38B ในตัวบ่งชี้หลายตัว และต้องการข้อมูลการฝึกอบรมน้อยลงถึง 40 เท่าในระหว่างกระบวนการฝึกอบรม ซึ่งช่วยประหยัดค่าใช้จ่ายในการประมวลผลได้ 1.8 เท่า ลองจินตนาการดูว่าสิ่งนี้หมายความว่าอย่างไร นักพัฒนาจำนวนมากขึ้นสามารถสัมผัสกับความสามารถ AI อันทรงพลังด้วยทรัพยากรและต้นทุนที่น้อยลง!
NVIDIA สร้างโอเพ่นซอร์สรุ่น Minitron ที่ได้รับการปรับให้เหมาะสมเหล่านี้บน Huggingface เพื่อให้ทุกคนใช้งานได้อย่างอิสระ
ทางเข้าสาธิต: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
ไฮไลท์:
** ปรับปรุงความเร็วการฝึก **: ความเร็วการฝึกโมเดล Minitron เร็วกว่ารุ่นดั้งเดิมถึง 40 เท่า ช่วยให้นักพัฒนาประหยัดเวลาและความพยายาม
**ประหยัดต้นทุน**: ด้วยเทคโนโลยีการตัดแต่งกิ่งและการกลั่นความรู้ ทรัพยากรการประมวลผลและปริมาณข้อมูลที่จำเป็นสำหรับการฝึกอบรมจึงลดลงอย่างมาก
? **การแบ่งปันโอเพ่นซอร์ส**: โมเดล Minitron ได้รับการเปิดแหล่งที่มาบน Huggingface ทำให้ผู้คนสามารถเข้าถึงและใช้งานได้มากขึ้น ส่งเสริมให้เทคโนโลยี AI ได้รับความนิยม
โอเพ่นซอร์สของโมเดล Minitron ถือเป็นความก้าวหน้าครั้งสำคัญในการใช้งานจริงของโมเดลภาษาขนาดเล็ก นอกจากนี้ยังบ่งชี้ว่าเทคโนโลยีปัญญาประดิษฐ์จะได้รับความนิยมมากขึ้นและใช้งานง่ายขึ้น ช่วยเพิ่มศักยภาพให้กับนักพัฒนาและสถานการณ์การใช้งานต่างๆ ได้มากขึ้น ในอนาคต เราคาดหวังว่าจะมีนวัตกรรมที่คล้ายกันมากขึ้นเพื่อส่งเสริมการพัฒนาเทคโนโลยีปัญญาประดิษฐ์อย่างต่อเนื่อง