In large-scale cloud computing environments, even small performance degradation can lead to huge waste of resources. Meta is faced with the challenge of effectively detecting and resolving these subtle performance issues. To this end, the Meta AI team developed FBDetect, a system that can detect extremely small performance regressions in production environments with an accuracy of even 0.005%. The editor of Downcodes will introduce to you in detail the working principle and remarkable results of FBDetect.
In the management of large cloud infrastructure, even small performance degradations can lead to significant resource waste. For example, in a company like Meta, a 0.05% slowdown in an application may seem insignificant, but when millions of servers are running simultaneously, this tiny delay can add up to thousands of wasted servers. Therefore, discovering and resolving these minor performance regressions in a timely manner is a huge challenge for Meta.

To solve this problem, Meta AI launched FBDetect, a performance regression detection system for production environments that can capture the smallest performance regressions, even as low as 0.005%. FBDetect is able to monitor approximately 800,000 time series, covering multiple indicators such as throughput, latency, CPU and memory usage, involving hundreds of services and millions of servers. By employing innovative techniques such as stack trace sampling across an entire server cluster, FBDetect is able to capture subtle subroutine-level performance differences.
FBDetect mainly focuses on subroutine-level performance analysis, which can reduce the difficulty of detection from 0.05% application-level regression to the more easily identifiable 5% subroutine-level changes. This approach significantly reduces noise, making tracking changes more practical.
The technical core of FBDetect consists of three main aspects. First, it reduces the variance of performance data through regression detection at the subroutine level, so that small regressions can be identified in time. Second, the system performs stack trace sampling across the entire server cluster to accurately measure the performance of each subroutine, similar to performance analysis in a large-scale environment. Finally, for each detected regression, FBDetect performs a root cause analysis to determine whether the regression is caused by a temporary issue, a cost change, or an actual code change.
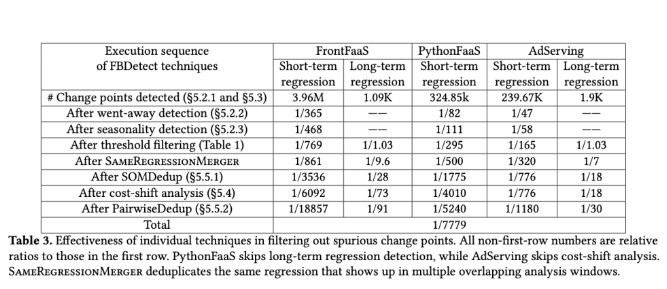
After seven years of testing in actual production environments, FBDetect has strong anti-interference capabilities and can effectively filter out false regression signals. The introduction of this system will not only significantly reduce the number of incidents that developers need to investigate, but also improve the efficiency of Meta infrastructure. By detecting small regressions, FBDetect helps Meta avoid wasting resources on approximately 4,000 servers per year.
In large enterprises like Meta with millions of servers, the detection of performance regression is particularly important. With its advanced monitoring capabilities, FBDetect not only improves the identification rate of minor regressions, but also provides developers with effective root cause analysis methods to help solve potential problems in a timely manner, thus promoting the efficient operation of the entire infrastructure.
Paper entrance: https://tangchq74.github.io/FBDetect-SOSP24.pdf
The successful cases of FBDetect provide valuable experience for large enterprises and provide new directions for the development of future performance monitoring systems. Its efficient resource utilization and accurate regression detection capabilities are worthy of reference and learning by the industry. Hopefully, more innovative technologies like this will emerge to help enterprises better manage and optimize their cloud infrastructure.