The editor of Downcodes learned that the Chinese research team successfully created the largest public multi-modal AI data set "Infinity-MM" and trained a small model Aquila-VL-2B with excellent performance based on this data set. The model achieved excellent results in multiple benchmark tests, demonstrating the huge potential of synthetic data in improving the performance of AI models. The Infinity-MM data set contains various types of data such as image descriptions and visual instruction data. Its generation process utilizes open source AI models such as RAM++ and MiniCPM-V, and undergoes multi-level processing to ensure data quality and diversity. The Aquila-VL-2B model is based on the LLaVA-OneVision architecture and uses Qwen-2.5 as the language model.
Recently, research teams from multiple Chinese institutions successfully created the "Infinity-MM" data set, which is currently one of the largest public multi-modal AI data sets, and trained a small new model with excellent performance - —Aquila-VL-2B.
The data set mainly contains four major categories of data: 10 million image descriptions, 24.4 million general visual instruction data, 6 million selected high-quality instruction data, and 3 million data generated by GPT-4 and other AI models.
On the generation side, the research team leveraged existing open source AI models. First, the RAM++ model analyzes the image and extracts important information, subsequently generating relevant questions and answers. In addition, the team built a special classification system to ensure the quality and diversity of the data generated.
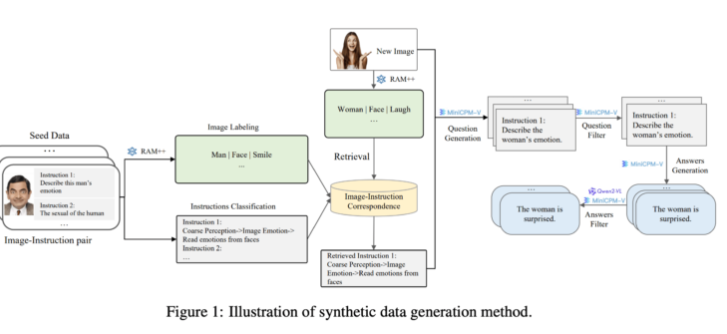
This synthetic data generation method uses a multi-level processing method, combining RAM++ and MiniCPM-V models to provide accurate training data for the AI system through image recognition, instruction classification and response generation.
The Aquila-VL-2B model is based on the LLaVA-OneVision architecture, uses Qwen-2.5 as the language model, and uses SigLIP for image processing. The training of the model is divided into four stages, gradually increasing the complexity. In the first stage, the model learns basic image-text associations; subsequent stages include general vision tasks, execution of specific instructions, and finally the integration of synthesized generated data. The image resolution is also gradually improved during training.
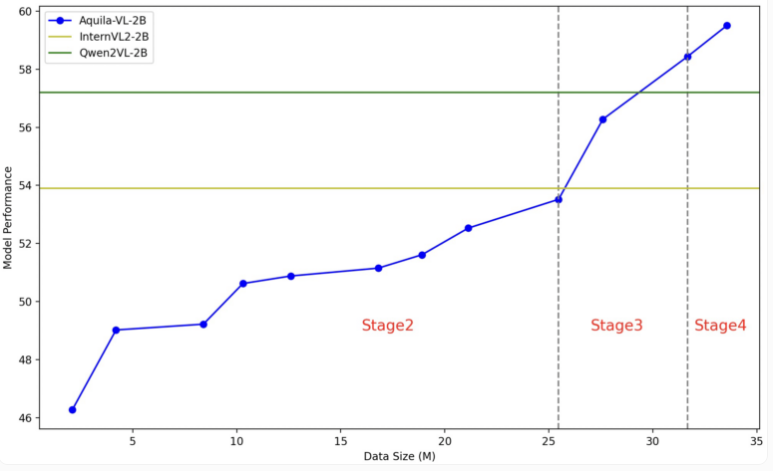
In the test, Aquila-VL-2B achieved the best result in the multi-modal MMStar-based test with a score of 54.9%, with a volume of only 2 billion parameters. In addition, the model performed particularly well in mathematical tasks, scoring 59% in the MathVista test, far exceeding similar systems.
In the general image understanding test, Aquila-VL-2B also performed well, with a HallusionBench score of 43% and an MMBench score of 75.2%. The researchers said that the addition of synthetically generated data significantly improved the performance of the model. Without the use of this additional data, the average performance of the model would have dropped by 2.4%.
This time the research team decided to open the data set and model to the research community. The training process mainly used Nvidia A100GPU and Chinese local chips. The successful launch of Aquila-VL-2B marks that open source models are gradually catching up with the trend of traditional closed source systems in AI research, especially showing good prospects in utilizing synthetic training data.
Infinity-MM paper entrance: https://arxiv.org/abs/2410.18558
Aquila-VL-2B project entrance: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
The success of Aquila-VL-2B not only proves China’s technical strength in the field of AI, but also provides valuable resources to the open source community. Its efficient performance and open strategy will promote the development of multi-modal AI technology, and it is worth looking forward to its future applications in more fields.