Ultra-long video understanding has always been a difficult problem for multi-modal large language models (MLLM). Existing models are difficult to process video data that exceeds the maximum context length, and information attenuation and high computational costs are also a major challenge. The editor of Downcodes learned that Zhiyuan Research Institute and several universities have proposed an ultra-long visual language model called Video-XL, which is designed to efficiently handle hour-level video understanding problems. The core technology of this model is "visual context latent summary", which cleverly utilizes the context modeling capabilities of LLM to compress long visual representations into a more compact form, similar to condensing a whole cow into a bowl of beef essence, making the model more efficient. Absorb key information.
Currently, multimodal large language models (MLLM) have made significant progress in the field of video understanding, but processing extremely long videos is still a challenge. This is because MLLM typically struggles to handle thousands of visual tokens that exceed the maximum context length and suffers from information decay caused by token aggregation. At the same time, a large number of video tags will also bring high computational costs.
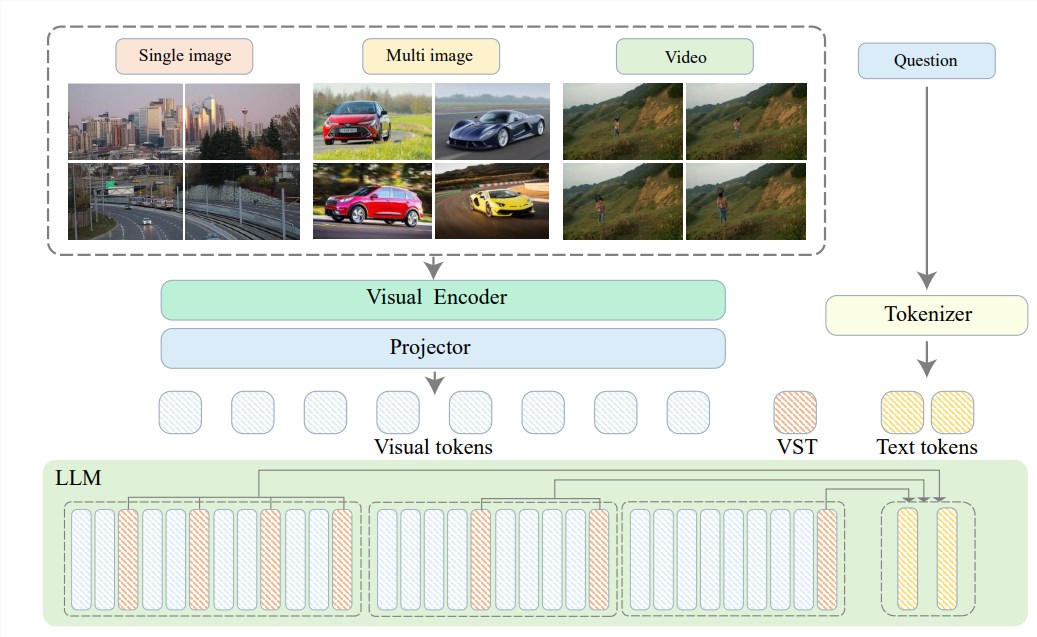
In order to solve these problems, Zhiyuan Research Institute teamed up with Shanghai Jiao Tong University, Renmin University of China, Peking University, Beijing University of Posts and Telecommunications and other universities to propose Video-XL, an ultra-high-definition system designed for efficient hour-level video understanding. Long visual language model. The core of Video-XL lies in the "visual context latent summarization" technology, which leverages the inherent context modeling capabilities of LLM to effectively compress long visual representations into a more compact form.
To put it simply, it is to compress the video content into a more streamlined form, just like condensing a whole cow into a bowl of beef essence, which is easier for the model to digest and absorb.
This compression technology not only improves efficiency, but also effectively preserves the key information of the video. You know, long videos are often filled with a lot of redundant information, like an old lady’s footcloth, long and smelly. Video-XL can accurately eliminate this useless information and retain only the essential parts, which ensures that the model will not lose its way when understanding long video content.
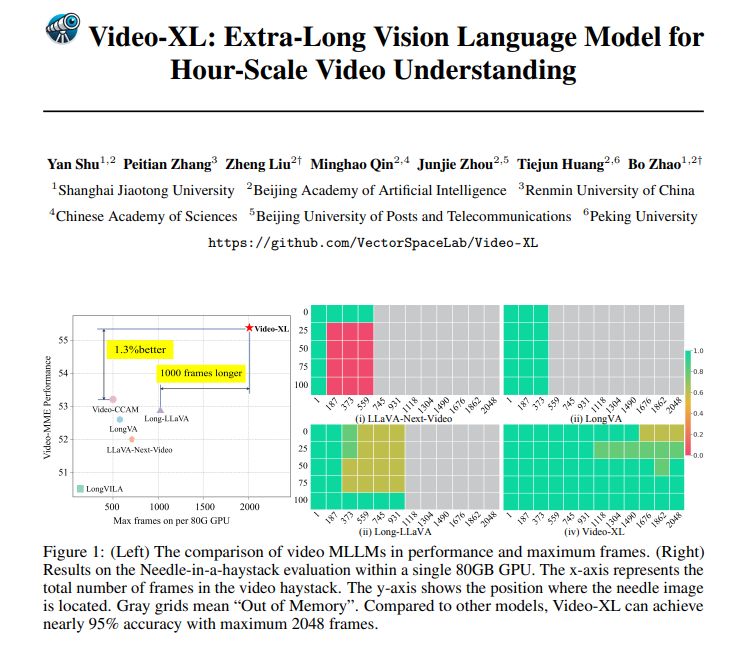
Video-XL is not only great in theory, but also quite capable in practice. Video-XL has achieved leading results in multiple long video understanding benchmarks, especially in the VNBench test, where its accuracy is nearly 10% higher than the best existing methods.
Even more impressively, Video-XL strikes an amazing balance between efficiency and effectiveness, capable of processing 2048 frames of video on a single 80GB GPU while still maintaining nearly 95% accuracy in the "needle in the haystack" evaluation. Rate.
Video-XL also has broad application prospects. In addition to being able to understand general long videos, it is also capable of specific tasks such as movie summarization, surveillance anomaly detection and ad placement recognition.
This means that you no longer have to endure lengthy plots when watching movies in the future. You can directly use Video-XL to generate a streamlined summary, saving time and effort; or you can use it to monitor surveillance footage and automatically identify abnormal events, which is much more efficient than manual tracking. .
Project address: https://github.com/VectorSpaceLab/Video-XL
Paper: https://arxiv.org/pdf/2409.14485
Video-XL has made breakthrough progress in the field of ultra-long video understanding. Its perfect combination of efficiency and accuracy provides a new solution for long video processing. It has broad application prospects in the future and is worth looking forward to!