Large model training is time-consuming and labor-intensive. How to improve efficiency and reduce energy consumption has become a key issue in the AI field. AdamW, as the default optimizer for Transformer pre-training, is gradually unable to cope with increasingly large models. The editor of Downcodes will take you to learn about a new optimizer developed by a Chinese team - C-AdamW. With its "cautious" strategy, it greatly reduces energy consumption while ensuring training speed and stability, and brings great benefits to large model training. to revolutionize change.
In the world of AI, working hard to achieve miracles seems to be the golden rule. The larger the model, the more data, and the stronger the computing power, the closer it seems to be to the Holy Grail of intelligence. However, behind this rapid development, there are also huge pressures on cost and energy consumption.
In order to make AI training more efficient, scientists have been looking for more powerful optimizers, like a coach, to guide the parameters of the model to continuously optimize and ultimately reach the best state. AdamW, as the default optimizer for Transformer pre-training, has been the industry benchmark for many years. However, in the face of the increasingly large model scale, AdamW also began to appear unable to cope with its capabilities.
Isn’t there a way to increase training speed while reducing energy consumption? Don’t worry, an all-Chinese team is here with their secret weapon C-AdamW!
C-AdamW's full name is Cautious AdamW, and its Chinese name is Cautious AdamW. Doesn't it sound very Buddhist? Yes, the core idea of C-AdamW is to think twice before acting.

Imagine that the parameters of the model are like a group of energetic children who always want to run around. AdamW is like a dedicated teacher, trying to guide them in the right direction. But sometimes, children get too excited and run in the wrong direction, wasting time and energy.
At this time, C-AdamW is like a wise elder with a pair of piercing eyes, able to accurately identify whether the update direction is correct. If the direction is wrong, C-AdamW will decisively call a stop to prevent the model from going further down the wrong road.
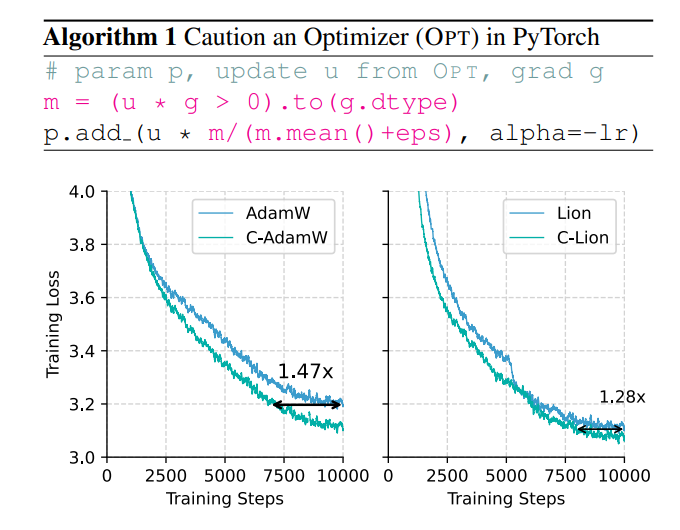
This cautious strategy ensures that each update can effectively reduce the loss function, thereby speeding up the convergence of the model. Experimental results show that C-AdamW increases the training speed to 1.47 times in Llama and MAE pre-training!
More importantly, C-AdamW requires almost no additional computational overhead and can be implemented with a simple one-line modification of existing code. This means that developers can easily apply C-AdamW to various model training and enjoy the speed and passion!
The great thing about C-AdamW is that it retains Adam's Hamiltonian function and does not destroy the convergence guarantee under Lyapunov analysis. This means that C-AdamW is not only faster, but its stability is also guaranteed, and there will be no problems such as training crashes.
Of course, being Buddhist does not mean that you are not enterprising. The research team stated that they will continue to explore richer ϕ functions and apply masks in feature space rather than parameter space to further improve the performance of C-AdamW.
It is foreseeable that C-AdamW will become the new favorite in the field of deep learning, bringing revolutionary changes to large model training!
Paper address: https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
The emergence of C-AdamW provides new ideas for solving the problems of large model training efficiency and energy consumption. Its high efficiency, stability and easy-to-use characteristics make it very promising for application. It is expected that C-AdamW can be applied in more fields in the future and promote the continuous development of AI technology. The editor of Downcodes will continue to pay attention to relevant technological progress, so stay tuned!