The editor of Downcodes learned that Peking University and other scientific research teams have released LLaVA-o1, a landmark multi-modal open source model. The model surpassed competitors such as Gemini, GPT-4o-mini and Llama in multiple benchmark tests, and its "slow thinking" reasoning mechanism allowed it to perform more complex reasoning, comparable to GPT-o1. The open source of LLaVA-o1 will bring new vitality to the research and application in the field of multi-modal AI.
Recently, Peking University and other scientific research teams announced the release of a multi-modal open source model called LLaVA-o1, which is said to be the first visual language model capable of spontaneous and systematic reasoning, comparable to GPT-o1.
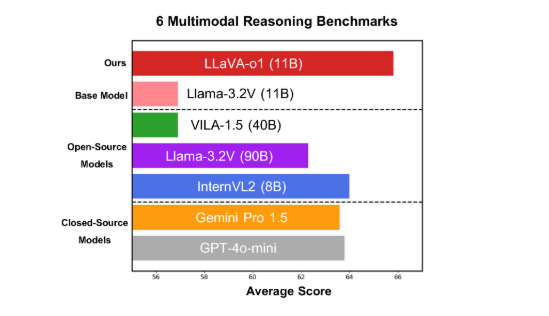
The model performs well on six challenging multi-modal benchmarks, with its 11B-parameter version outperforming other competitors such as Gemini-1.5-pro, GPT-4o-mini and Llama-3.2-90B-Vision- Instruct.
LLaVA-o1 is based on the Llama-3.2-Vision model and adopts a "slow thinking" reasoning mechanism, which can independently conduct more complex reasoning processes, surpassing the traditional thinking chain prompt method.
On the multi-modal inference benchmark, LLaVA-o1 outperformed its base model by 8.9%. The model is unique in that its reasoning process is divided into four stages: summary, visual explanation, logical reasoning and conclusion generation. In traditional models, the reasoning process is often relatively simple and can easily lead to wrong answers, while LLaVA-o1 ensures more accurate output through structured multi-step reasoning.
For example, when solving the problem "How many objects are left after subtracting all the small bright balls and purple objects?", LLaVA-o1 will first summarize the problem, then extract information from the image, then perform step-by-step reasoning, and finally give Answer. This staged approach improves the model's systematic reasoning capabilities, making it more efficient in handling complex problems.

It is worth mentioning that LLaVA-o1 introduces a stage-level beam search method in the inference process. This approach allows the model to generate multiple candidate answers at each inference stage and select the best answer to proceed to the next stage of inference, thereby significantly improving the overall inference quality. With supervised fine-tuning and reasonable training data, LLaVA-o1 performs well in comparisons with larger or closed-source models.
The research results of the Peking University team not only promote the development of multi-modal AI, but also provide new ideas and methods for future visual language understanding models. The team stated that the code, pre-training weights and data sets of LLaVA-o1 will be fully open source, and they look forward to more researchers and developers jointly exploring and applying this innovative model.
Paper: https://arxiv.org/abs/2411.10440
GitHub:https://github.com/PKU-YuanGroup/LLaVA-o1
The open source of LLaVA-o1 will undoubtedly promote technological development and application innovation in the field of multi-modal AI. Its efficient inference mechanism and excellent performance make it an important reference for future visual language model research and is worthy of attention and anticipation. We look forward to more developers participating and jointly promoting the progress of artificial intelligence technology.