The editor of Downcodes learned that aiOla recently released an open source AI audio transcription model, Whisper-NER, which can shield sensitive information in real time during the transcription process to protect user privacy. This move not only improves the security of audio transcription, but also provides new possibilities for the application of AI technology in fields with high privacy requirements such as law and medical care. Whisper-NER is built based on OpenAI's Whisper model and is completely open source, allowing users to freely use, modify and deploy it.
Recently, aiOla announced the launch of Whisper-NER, an open source AI audio transcription model that can mask sensitive information in real time during the transcription process.
aiOla's new Whisper-NER is built on OpenAI's industry-standard open source model Whisper, itself fully open source, and now available on Hugging Face and Github for enterprises, organizations and individuals to use, adapt, modify and deploy.
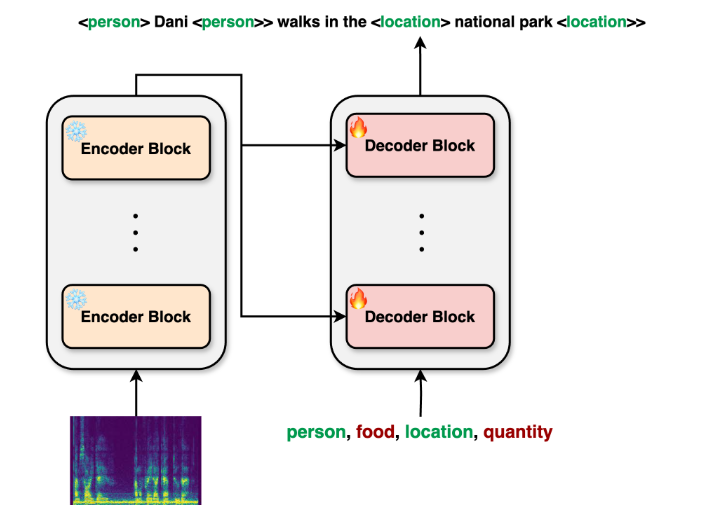
The audio transcription model has flexible configuration options, and users can choose whether to mask sensitive information according to their needs. When the user selects the masking function, the model will automatically identify and hide sensitive information such as personal names, addresses, phone numbers, etc., effectively preventing privacy leakage in the transcribed text. This ability makes the model particularly important in application scenarios in legal, medical, education and other fields.
In addition to protecting sensitive information, the model also has efficient and accurate transcription capabilities that work well across multiple languages and accents. This makes its application in multi-language environments even more widespread. For example, when companies deal with customer feedback, they can accurately record and analyze audio information from different regions, thereby improving service quality.
In addition, aiOla encourages developers and researchers to use this open source model to further enhance its capabilities. Users can obtain the source code on the open source platform and modify and optimize it according to their own needs. This approach not only improves the usability of the model, but also promotes the innovation and development of AI technology.
This new product from aiOla demonstrates its emphasis on privacy protection in the field of audio transcription, and also opens up more possibilities for future AI applications. As more users and developers join, we expect this open source model to bring wider application scenarios and influence.
Whisper-NER is completely open source and available under the MIT license, allowing users to freely adopt, modify and deploy it, including for commercial applications. Users can now also try out the demo model on Hugging Face, which allows them to record speech clips and have the model mask the specific words they type in the generated typing script.
huggingface: https://huggingface.co/aiola/whisper-ner-v1
github:https://github.com/aiola-lab/whisper-ner
All in all, Whisper-NER's open source and privacy protection features have brought new breakthroughs to the field of AI audio transcription, and its application prospects are worth looking forward to. The editor of Downcodes recommends interested readers to go to Hugging Face and Github to learn more.