Are you curious about the technology behind AI products such as ChatGPT and Wenxinyiyan? They all rely on large language models (LLM). The editor of Downcodes will take you to understand the operating principle of LLM in a simple and easy-to-understand way. Even if you only have a second grade mathematics level, you can easily understand it! We will start from the basic concepts of neural networks and gradually explain model training, advanced techniques, and core technologies such as GPT and Transformer architecture, so that you have a clear understanding of LLM.
Have you heard of advanced AI such as ChatGPT and Wen Xinyiyan? The core technology behind them is "large language model" (LLM). Do you find it complicated and difficult to understand? Don’t worry, even if you only have a second-grade mathematics level, you can easily grasp the operating principle of LLM after reading this article!
Neural Networks: The Magic of Numbers
First, we need to know that a neural network is like a supercomputer, it can only process numbers. Both input and output must be numbers. So how do we make it understand text?
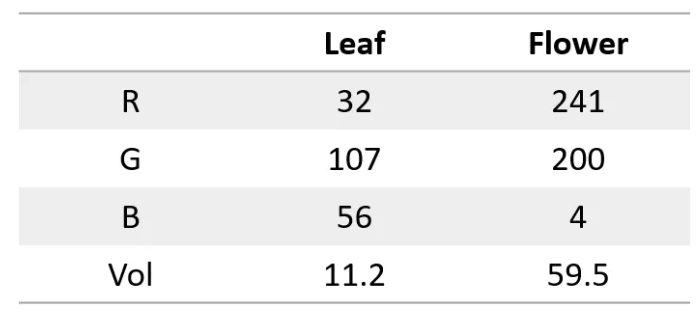
The secret is to convert words into numbers! For example, we can represent each letter with a number, such as a=1, b=2, and so on. In this way, the neural network can "read" the text.
Training the model: Let the network “learn” language
With digital text, the next step is to train the model and let the neural network "learn" the rules of language.
The training process is like playing a guessing game. We show the network some text, such as "Humpty Dumpty," and ask it to guess what the next letter is. If it guesses correctly, we give it a reward; if it guesses wrong, we give it a penalty. By constantly guessing and adjusting, the network can predict the next letter with increasing accuracy, eventually producing complete sentences such as "Humpty Dumpty sat on a wall."
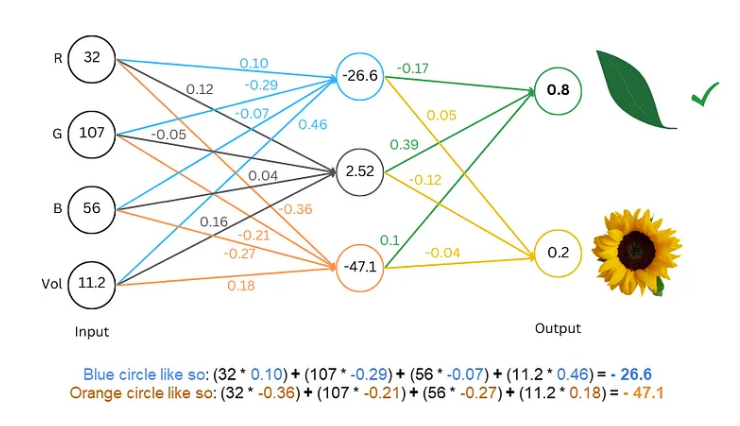
Advanced techniques: Make the model more "smart"
In order to make the model more "smart", researchers have invented many advanced techniques, such as:
Word embedding: Instead of using simple numbers to represent letters, we use a set of numbers (vectors) to represent each word, which can more fully describe the meaning of the word.
Subword segmenter: Split words into smaller units (subwords), such as splitting "cats" into "cat" and "s", which can reduce vocabulary and improve efficiency.
Self-attention mechanism: When the model predicts the next word, it will adjust the weight of the prediction based on all the words in the context, just like we understand the meaning of the word based on the context when reading.
Residual connection: In order to avoid training difficulties caused by too many network layers, researchers invented residual connection to make the network easier to learn.
Multi-head attention mechanism: By running multiple attention mechanisms in parallel, the model can understand the context from different perspectives and improve the accuracy of predictions.
Positional encoding: In order for the model to understand the order of words, researchers will add positional information to word embeddings, just like we pay attention to the order of words when reading.
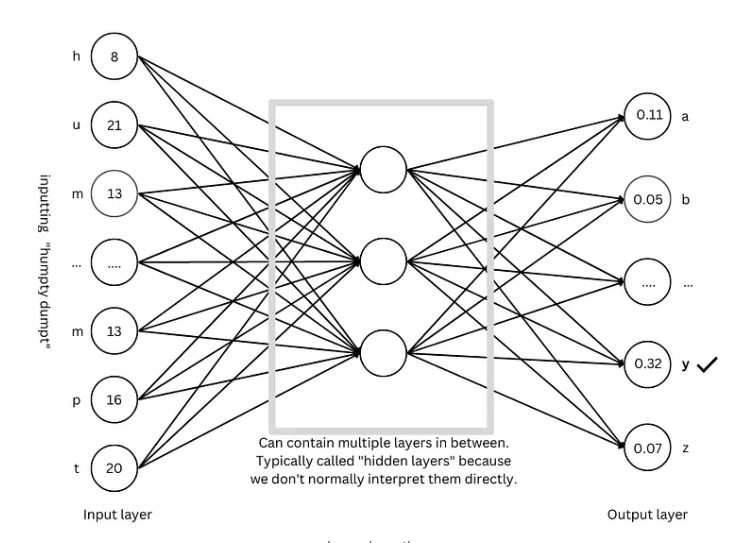
GPT architecture: the “blueprint” for large-scale language models
The GPT architecture is one of the most popular large-scale language model architectures at present. It is like a "blueprint" that guides the design and training of the model. The GPT architecture cleverly combines the above-mentioned advanced techniques to enable the model to learn and generate language efficiently.
Transformer Architecture: The “revolution” of language models
The Transformer architecture is a major breakthrough in the field of language models in recent years. It not only improves the accuracy of prediction, but also reduces the difficulty of training, laying the foundation for the development of large-scale language models. The GPT architecture also evolved based on the Transformer architecture.
Reference: https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
I hope that the explanation by the editor of Downcodes can help you understand the operating principles of large language models. Of course, LLM technology is still developing. This article is just the tip of the iceberg. More and more in-depth content requires you to continue to learn and explore!