The editor of Downcodes learned that Meta recently released a new multi-language multi-turn dialogue command following ability assessment benchmark test Multi-IF. The benchmark covers eight languages and contains 4501 three-round dialogue tasks, aiming to more comprehensively evaluate large language models. (LLM) performance in practical applications. Unlike existing evaluation standards that mainly focus on single-turn dialogue and single-language tasks, Multi-IF focuses on examining the model's ability in complex multi-turn and multi-language scenarios, providing a clearer direction for the improvement of LLM.
Meta recently released a new benchmark test called Multi-IF, which is designed to evaluate the instruction following ability of large language models (LLM) in multi-turn conversations and multi-language environments. This benchmark covers eight languages and contains 4501 three-turn dialogue tasks, focusing on the performance of current models in complex multi-turn and multi-language scenarios.
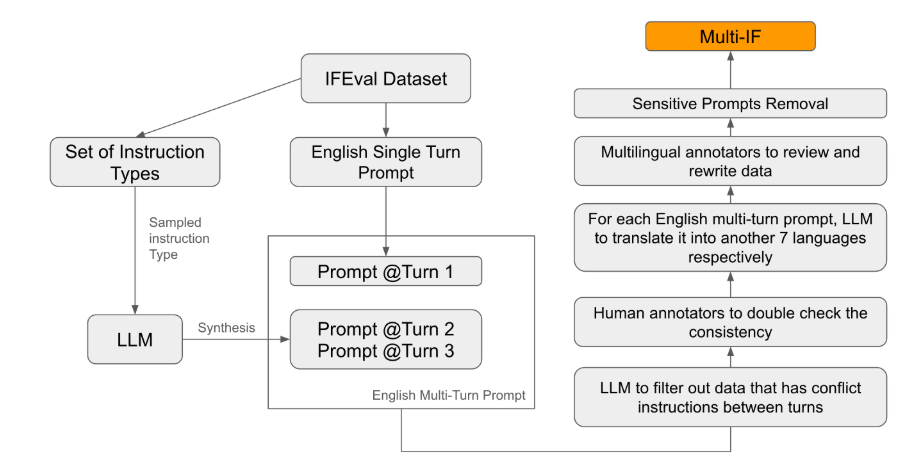
Among the existing evaluation standards, most focus on single-turn dialogue and single-language tasks, which are difficult to fully reflect the performance of the model in practical applications. The launch of Multi-IF is to fill this gap. The research team generated complex dialogue scenarios by extending a single round of instructions into multiple rounds of instructions, and ensured that each round of instructions was logically coherent and progressive. In addition, the data set also achieves multi-language support through steps such as automatic translation and manual proofreading.
Experimental results show that the performance of most LLMs drops significantly over multiple dialogue rounds. Taking the o1-preview model as an example, its average accuracy in the first round was 87.7%, but dropped to 70.7% in the third round. Especially in languages with non-Latin scripts, such as Hindi, Russian and Chinese, the performance of the model is generally lower than that of English, showing limitations in multi-language tasks.
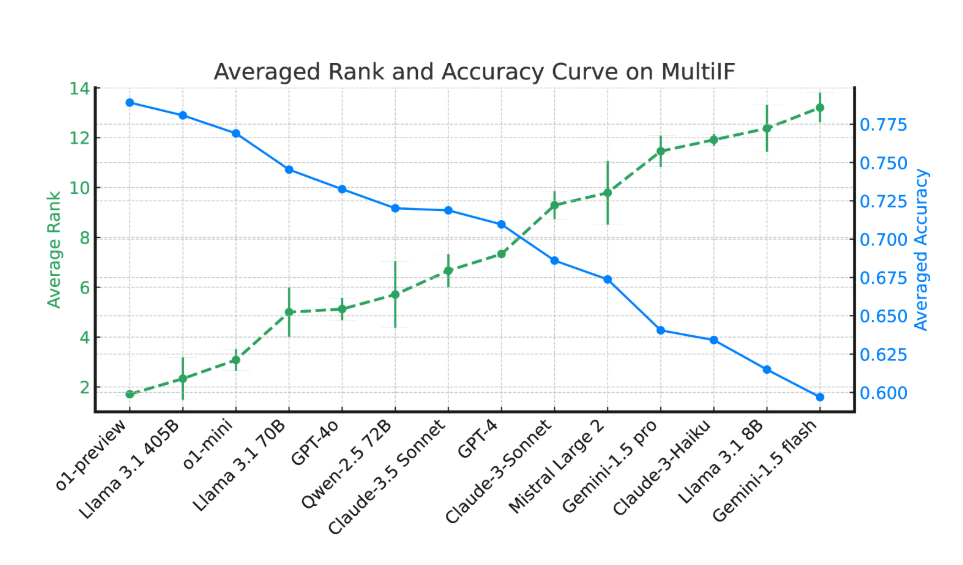
In the evaluation of 14 cutting-edge language models, o1-preview and Llama3.1405B performed best, with average accuracy rates of 78.9% and 78.1% in three rounds of instructions respectively. However, across multiple rounds of dialogue, all models showed a general decline in their ability to follow instructions, reflecting the challenges faced by the models in complex tasks. The research team also introduced the "Instruction Forgetting Rate" (IFR) to quantify the model's instruction forgetting phenomenon in multiple rounds of dialogue. The results show that high-performance models perform relatively well in this regard.
The release of Multi-IF provides researchers with a challenging benchmark and promotes the development of LLM in globalization and multilingual applications. The launch of this benchmark not only reveals the shortcomings of current models in multi-round and multi-language tasks, but also provides a clear direction for future improvements.
Paper: https://arxiv.org/html/2410.15553v2
The release of the Multi-IF benchmark test provides an important reference for the research of large language models in multi-turn dialogue and multi-language processing, and also points the way for future model improvements. It is expected that more and more powerful LLMs will emerge in the future to better cope with the challenges of complex multi-round multi-language tasks.