The Marco-o1 inference model recently released by Alibaba International AI Team focuses on solving open-ended problems, breaking through the limitations of traditional models that are limited to standard answer fields, and demonstrating its potential in handling complex and difficult-to-quantify tasks. The editor of Downcodes will give you an in-depth understanding of the characteristics, applications and usage of this model, as well as the innovation it brings to the field of artificial intelligence.
Alibaba International AI Team recently released a new reasoning model called Marco-o1, which pays special attention to the solution of open problems and is not limited to subject areas with standard answers, such as programming and mathematics. The research team is committed to exploring whether such models can be effectively generalized to areas that are difficult to quantify and lack clear rewards.
The characteristics of the Marco-o1 model include using ultra-long CoT data for fine-tuning, using MCTS to expand the solution space, and fine-grained solution space expansion. The model uses self-play+MCTS to construct a batch of ultra-long CoT data with the ability to reflect and correct, and is trained together with other open source data. In addition, the research team also defined mini-Step to further expand the solution space of the model and guide the model to output better answers.
In the translation task, the Marco-o1 model demonstrated its ability to handle the translation of long and difficult sentences. This is the first time that inference time extension has been applied to machine translation tasks. The research team has open sourced some CoT data and the best current models, and plans to open source more data and models in the future.
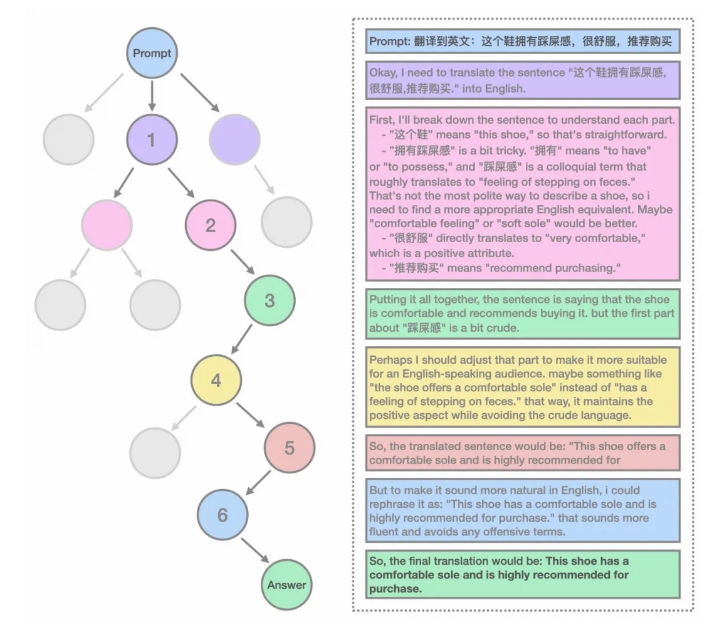
The model will think deeply about the response when reasoning. For example, when outputting the number of 'r's in the word 'strawberry', the model will gradually disassemble each letter in the word and compare it, and finally output the result correctly. In the field of machine translation, the model correctly identifies difficult points through inference links and translates them word by word, improving the overall translation accuracy.
The research team has also tried it in other fields, proving the model's ability to solve other general real-world problems. The overall structure of Marco-o1 uses self-play+MCTS to build a batch of ultra-long CoT data with the ability to reflect and correct, and train it together with other open source data. The research team also incorporated some instruction compliance data sets from the MarcoPolo family to improve the model's instruction compliance capabilities.
In terms of usage, the research team provides inference code and fine-tuning code. Users can easily load the model and tokenizer and start chatting or fine-tuning the model. In addition, the model can also be run directly on the GGUF version on ModelScope, providing a faster way to experience it.
The release of the Marco-o1 model marks an important step taken by Alibaba's international AI team in the field of inference models, providing new ideas and tools for solving open problems.
ModelScope:
https://modelscope.cn/models/AIDC-AI/Marco-o1
Arxiv:
https://arxiv.org/abs/2411.14405
Github:
https://github.com/AIDC-AI/Marco-o1
Hugging Face:
https://huggingface.co/AIDC-AI/Marco-o1
The open source of the Marco-o1 model provides valuable resources for researchers and developers. It is believed that more innovative applications based on this model will emerge in the future, promoting the continued development of artificial intelligence technology. Looking forward to more application cases and research results about Marco-o1!