In recent years, artificial intelligence has made significant progress in various fields, but its mathematical reasoning ability has always been a bottleneck. Today, the emergence of a new benchmark called FrontierMath provides a new yardstick for evaluating AI's mathematical capabilities. It pushes AI's mathematical reasoning capabilities to unprecedented limits and poses severe challenges to existing AI models. . The editor of Downcodes will take you to have an in-depth understanding of FrontierMath and see how it subverts our understanding of AI's mathematical capabilities.
In the vast universe of artificial intelligence, mathematics was once regarded as the last bastion of machine intelligence. Today, a new benchmark test called FrontierMath has emerged, pushing AI's mathematical reasoning capabilities to unprecedented limits.
Epoch AI has joined hands with more than 60 top brains in the mathematics world to jointly create this AI challenge field that can be called the Mathematical Olympiad. This is not only a technical test, but also the ultimate test of the mathematical wisdom of artificial intelligence.
Imagine a laboratory filled with the world's top mathematicians, who have crafted hundreds of mathematical puzzles that exceed the imagination of ordinary people. These problems span the most cutting-edge mathematical fields such as number theory, real analysis, algebraic geometry, and category theory, and are of staggering complexity. Even a math genius with an International Mathematical Olympiad gold medal needs hours or even days to solve a problem.
Shockingly, the current state-of-the-art AI models performed disappointingly on this benchmark: no model was able to solve more than 2% of the problems. This result was like a wake-up call and slapped the AI in the face.
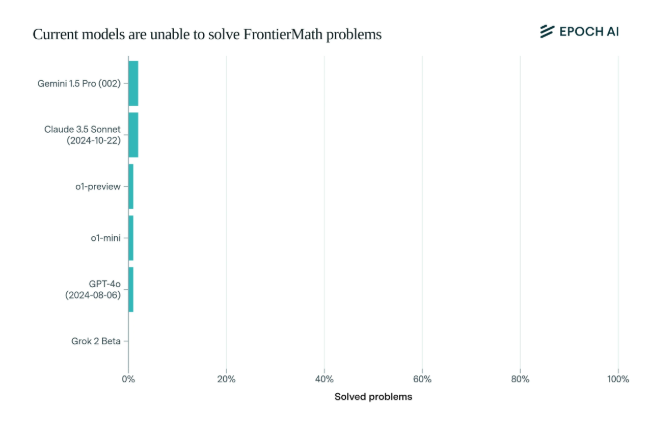
What makes FrontierMath unique is its rigorous evaluation mechanism. Traditional mathematical test benchmarks such as MATH and GSM8K have been maxed out by AI, and this new benchmark uses new, unpublished questions and an automated verification system to effectively avoid data pollution and truly test the mathematical reasoning capabilities of AI.
The flagship models of top AI companies such as OpenAI, Anthropic, and Google DeepMind, which have attracted much attention, collectively overturned in this test. This reflects a profound technical philosophy: For computers, seemingly complex mathematical problems may be easy, but tasks that humans find simple may make AI helpless.
As Andrej Karpathy said, this confirms Moravec's paradox: the difficulty of intelligent tasks between humans and machines is often counter-intuitive. This benchmark test is not only a rigorous examination of AI capabilities, but also a catalyst for the evolution of AI to higher dimensions.
For the mathematics community and AI researchers, FrontierMath is like an unconquered Mount Everest. It not only tests knowledge and skills, but also tests insight and creative thinking. In the future, whoever can take the lead in climbing this peak of intelligence will be recorded in the history of artificial intelligence development.
The emergence of the FrontierMath benchmark test is not only a severe test of the existing AI technology level, but also points out the direction for future AI development. It indicates that AI still has a long way to go in the field of mathematical reasoning, and it also stimulates research. Researchers continue to explore and innovate to break through the bottlenecks of existing technologies.