Downcodes editor reports: Research teams from Shanghai Jiao Tong University, Cambridge University and Geely Automobile Research Institute recently launched a new text-to-speech (TTS) system called F5-TTS. The system uses an autoregression-free method, combined with flow matching and diffusion transformer (DiT), which effectively simplifies the complex process of the traditional TTS model and achieves significant breakthroughs in both synthesis quality and inference speed. Compared with traditional TTS models, F5-TTS performs well in terms of processing speed and robustness, bringing new possibilities to speech synthesis technology.
Recently, a research team from Shanghai Jiao Tong University, Cambridge University and Geely Automobile Research Institute launched a new text-to-speech (TTS) system called F5-TTS. What is special about this system is that it uses an autoregression-free method that combines flow matching with a diffusion transformer (DiT), successfully simplifying the complex steps in the traditional TTS model.

As we all know, traditional TTS models often require complex duration modeling, phoneme alignment, and specialized text encoding, which increase the complexity of the synthesis process. In particular, previous models such as E2TTS often face problems such as slow convergence and inaccurate alignment of text and speech, which makes them difficult to apply efficiently in real-world scenarios. The emergence of F5-TTS is precisely to solve these challenges.
The working principle of F5-TTS is simple. First, the input text is processed through the ConvNeXt architecture to make it easier to align with speech. The padded character sequence is then fed into the model along with a noisy version of the input speech.
The training of the system relies on the Diffusion Transformer (DiT), which effectively maps a simple initial distribution to the data distribution through flow matching. In addition, F5-TTS also innovatively introduces the Sway Sampling strategy during inference, which can prioritize early flow steps in the inference phase, thereby improving the alignment between generated speech and input text.
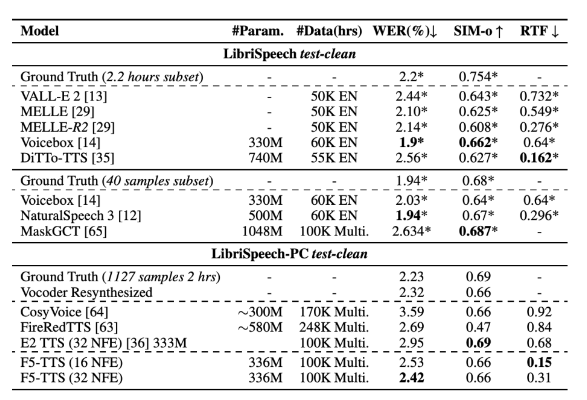
According to research results, F5-TTS surpasses many current TTS systems in both synthesis quality and inference speed. On the LibriSpeech-PC dataset, the model achieved a word error rate (WER) of 2.42 and a real-time factor (RTF) of 0.15 at inference time, which was significantly better than the previous diffusion model E2TTS, which performed better in processing speed and There are shortcomings in robustness.
At the same time, the Sway Sampling strategy significantly improves the naturalness and understandability of generated speech, allowing the model to achieve smooth and expressive generation without training.
F5-TTS improves alignment robustness and synthesis quality by simplifying the process and eliminating the need for duration prediction, phoneme alignment, and explicit text encoding. In addition, the researchers also emphasized ethical considerations and proposed the need to establish watermarking and detection systems to prevent the model from being abused.
Project entrance: https://github.com/SWivid/F5-TTS
Highlight:
F5-TTS is a new type of autoregressive text-to-speech system that simplifies the complexity of the traditional TTS model.
The system utilizes ConvNeXt and DiT architecture to improve the alignment of text and speech and significantly improve the synthesis quality.
? The researchers emphasized the need to pay attention to ethical issues and suggested the introduction of watermarking and detection mechanisms to prevent potential abuse.
The emergence of the F5-TTS system has brought new breakthroughs to text-to-speech technology, and its efficient performance and simplified processes are expected to be widely used in many fields. However, ethical issues also require attention, and subsequent research should be dedicated to establishing a sound regulatory mechanism to ensure the responsible development of technology.