The editor of Downcodes will take you to understand a disturbing phenomenon in the field of AI - model collapse. Imagine that an AI model is like a food blogger who starts to eat the food he cooks. The more he eats, the more he becomes addicted to it, and the food becomes more and more unpalatable. Eventually, he becomes "bad". This is when the model collapses. It occurs when an AI model relies too much on the data it generates, leading to a decline in model quality or even complete failure. This article will delve into the causes, effects, and how to avoid model collapse.
A strange thing has happened in the AI circle recently, like a food blogger who suddenly started to eat the food he cooked, and the more he ate, the more he became addicted, and the food became more and more unpalatable. This thing is quite scary to say. The professional term is called model collapse.
What is model collapse? To put it simply, if an AI model uses a large amount of self-generated data during the training process, it will fall into a vicious cycle, causing the quality of model generation to get worse and worse, and eventually fail.
This is like a closed ecosystem. The AI model is the only living thing in this system, and the food it produces is data. In the beginning, it could still find some natural ingredients (real data), but as time went by, it began to rely more and more on the "artificial" ingredients it produced (synthetic data). The problem is, these “artificial” ingredients are nutritionally deficient and carry some of the flaws of the model itself. If you eat too much, the "body" of the AI model will collapse, and the things generated will become more and more outrageous.
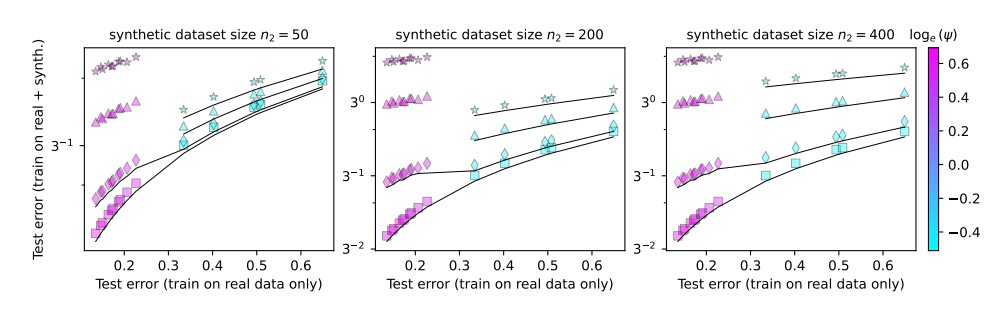
This paper studies the phenomenon of model collapse and attempts to answer two key questions:
Is model collapse inevitable? Can the problem be solved by mixing real and synthetic data?
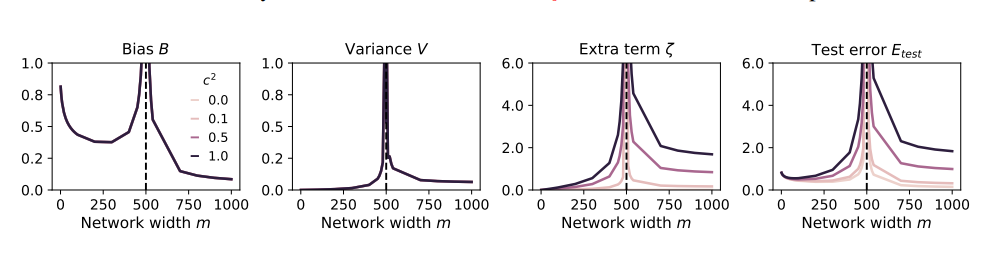
The larger the model, the easier it is to crash?
In order to study these issues, the authors of the paper designed a series of experiments and used a random projection model to simulate the training process of the neural network. They found that using even a small portion of the synthetic data (say, 1%) could cause the model to collapse. To make matters worse, as the size of the model increases, the phenomenon of model collapse becomes more serious.
This is like a food blogger who started trying all kinds of weird ingredients in order to attract attention, but ended up getting a bad stomach. In order to recover the losses, he could only increase his food intake and eat more and weirder things. As a result, his stomach got worse and worse, and he finally had to quit the world of eating and broadcasting.
So, how should we avoid model collapse?
The authors of the paper made some suggestions:
Prioritize the use of real data: Real data is like natural food, rich in nutrients, and is the key to the healthy growth of AI models.
Use synthetic data with caution: Synthetic data is like artificial food. Although it can supplement some nutrients, you should not rely too much on it, otherwise it will be counterproductive.
Control the size of the model: The larger the model, the greater the appetite, and the easier it is to have a bad stomach. When using synthetic data, control the size of the model to avoid overfeeding.
Model collapse is a new challenge encountered in the development process of AI. It reminds us that while pursuing model scale and efficiency, we must also pay attention to the quality of data and the health of the model. Only in this way can AI models continue to develop healthily and create greater value for human society.
Paper: https://arxiv.org/pdf/2410.04840
All in all, model collapse is a problem worthy of attention in the development of AI. We need to treat synthetic data with caution, pay attention to the quality of real data, and control the scale of the model to avoid the phenomenon of "AI eating too much." I hope this analysis can help everyone better understand model collapse and contribute to the healthy development of AI.