The editor of Downcodes brings you big news! There is a new member in the field of artificial intelligence - Zyphra officially released its small language model Zamba2-7B! This 7 billion parameter model has achieved a breakthrough in performance, especially in terms of efficiency and adaptability, showing impressive advantages. It is not only suitable for high-performance computing environments, but more importantly, Zamba2-7B can also run on consumer-grade GPUs, allowing more users to easily experience the charm of advanced AI technology. This article will delve into the innovations of Zamba2-7B and its impact on the field of natural language processing.
Recently, Zyphra officially launched Zamba2-7B, a small language model with unprecedented performance, with the number of parameters reaching 7B.
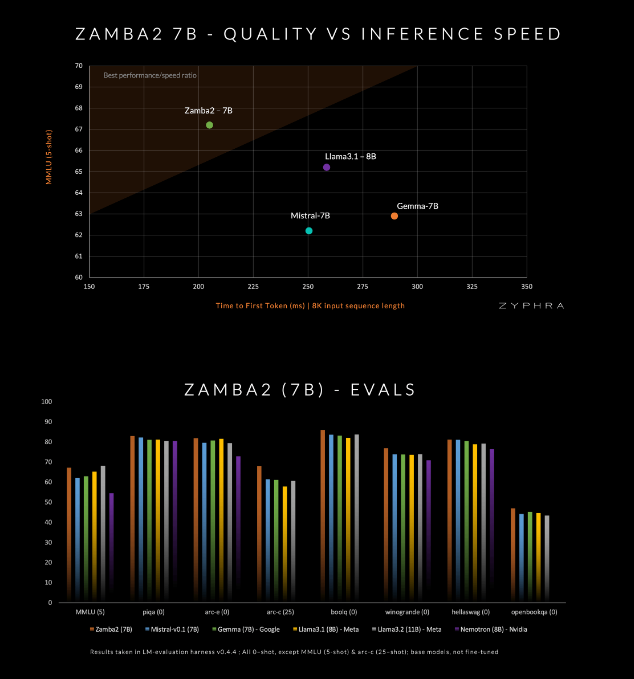
This model claims to surpass current competitors in quality and speed, including Mistral-7B, Google's Gemma-7B and Meta's Llama3-8B.
Zamba2-7B is designed to meet the needs of environments that require powerful language processing capabilities but are limited by hardware conditions, such as on-device processing or using consumer-grade GPUs. By improving efficiency without sacrificing quality, Zyphra hopes to enable a wider range of users, whether enterprises or individual developers, to enjoy the convenience of advanced AI.
Zamba2-7B has made many innovations in its architecture to improve the efficiency and expression capabilities of the model. Different from the previous generation model Zamba1, Zamba2-7B uses two shared attention blocks. This design can better handle the dependencies between information flow and sequences.
The Mamba2 block forms the core of the entire architecture, which makes the parameter utilization of the model higher than that of traditional converter models. In addition, Zyphra also uses low-rank adaptation (LoRA) projection on shared MLP blocks, which further improves the adaptability of each layer while maintaining the compactness of the model. Thanks to these innovations, Zamba2-7B's first response time has been reduced by 25%, and the number of tokens processed per second has increased by 20%.
The efficiency and adaptability of Zamba2-7B have been verified by rigorous testing. The model is pre-trained on a massive data set containing three trillion tokens, which are high-quality and rigorously screened open data.
In addition, Zyphra also introduces an "annealing" pre-training stage that quickly reduces the learning rate to process high-quality tokens more efficiently. This strategy allows Zamba2-7B to perform well in benchmarks, outperforming competitors in inference speed and quality, and is suitable for tasks such as natural language understanding and generation without requiring the massive computing resources required by traditional high-quality models. .
amba2-7B represents a major advancement in small language models, maintaining high quality and performance while paying special attention to accessibility. Through innovative architectural design and efficient training technology, Zyphra has successfully created a model that is not only easy to use, but can also meet various natural language processing needs. The open source release of Zamba2-7B invites researchers, developers, and businesses to explore its potential and is expected to advance the development of advanced natural language processing within the broader community.
Project entrance: https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
The open source release of Zamba2-7B has brought new vitality to the field of natural language processing and provided more possibilities for developers. We look forward to Zamba2-7B being more widely used in the future and promoting the continued progress of artificial intelligence technology!