Downcodes editor reports: FunASR has launched a powerful multi-language offline file transcription software package to provide users with an efficient and accurate speech-to-text solution. The software package supports multiple languages, including Chinese, English, Japanese, Cantonese and Korean, and can generate transcribed text with punctuation marks. It also provides word-level timestamps to facilitate users to pinpoint audio content. In addition, it also supports custom hot word functions to improve transcription accuracy, and provides a rich client library to facilitate developers for secondary development and system integration. The package’s offline transcription capabilities are particularly impressive and can efficiently process hours-long audio or video files, making it an ideal tool for professionals working with large amounts of audio material.
Recently, FunASR launched a powerful multi-language offline file transcription software package, providing users with an efficient and accurate speech-to-text solution.
The core strength of this software package is its offline file transcription capabilities. It can easily process hours-long audio or video files and generate transcribed text with punctuation. This feature is undoubtedly a great boon for professionals who need to process large amounts of audio material.
FunASR's multi-language support is also impressive. Currently, the software package supports multiple languages such as Chinese, English, Japanese, Cantonese and Korean, demonstrating excellent speech recognition capabilities. What’s more worth mentioning is that it also provides word-level timestamps, allowing users to pinpoint specific content in the audio.
In order to meet the personalized needs of users, FunASR has introduced a custom hot word function. Users can define specific terms or proper nouns, and the software will optimize the recognition results accordingly, greatly improving the accuracy and practicality of transcription.
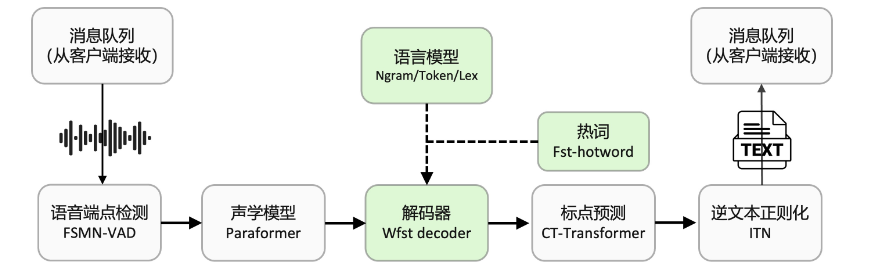
From a technical perspective, FunASR integrates multiple advanced models, including speech endpoint detection, speech recognition, and punctuation mark insertion. This comprehensive speech recognition process ensures high-quality transcription results. At the same time, the software supports parallel processing of multiple transcription requests, greatly improving work efficiency.
For developers, FunASR provides a rich set of client libraries covering multiple programming languages such as HTML, Python, C++, Java and C#. This diversity provides convenience for secondary development and system integration.
In practical applications, FunASR performs well. It can handle hundreds of concurrent requests at the same time and is suitable for various scenarios such as meeting recording and interview transcription. The software also supports Initial Time Normalization (ITN), further improving transcription accuracy.
To simplify the deployment process, FunASR provides Docker installation and startup instructions. Users can pull the Docker image and start the server with just a few simple commands, and easily experience the efficient offline transcription function.
Project address: https://github.com/modelscope/FunASR/blob/main/runtime/docs/SDK_advanced_guide_offline.md
All in all, FunASR provides users with an efficient and accurate speech-to-text solution with its powerful offline transcription capabilities, multi-language support, custom hot word functions and convenient deployment methods. Interested users can visit the project address to learn more and experience the package. The editor of Downcodes recommends everyone to try it!