The editor of Downcodes learned that scientists from Meta, the University of California, Berkeley, and New York University jointly developed a new technology called "Thinking Preference Optimization" (TPO), aiming to improve the performance of large language models (LLMs). This technology improves AI's "thinking" ability by allowing the model to generate a series of thinking steps before answering a question, and using the evaluation model to optimize the quality of the final answer, allowing it to perform better in various tasks. Different from the traditional "chain thinking" technology, TPO has a wider range of applications, especially showing significant advantages in creative writing, common sense reasoning, etc.
Recently, scientists from Meta, the University of California, Berkeley, and New York University collaborated to develop a new technology called Thought Preference Optimization (TPO). The goal of this technology is to improve the performance of large language models (LLMs) when performing various tasks, allowing AI to consider its responses more carefully before answering.
Researchers say Thinking should have broad utility. For example, in creative writing tasks, AI can use internal thought processes to plan the overall structure and character development. This method is significantly different from the previous "Chain-of-Thought" (CoT) prompting technology. The latter is mainly used in mathematical and logical tasks, while TPO has a wider range of applications. The researchers mentioned OpenAI's new o1 model and believe that the thinking process is also helpful for a wider range of tasks.
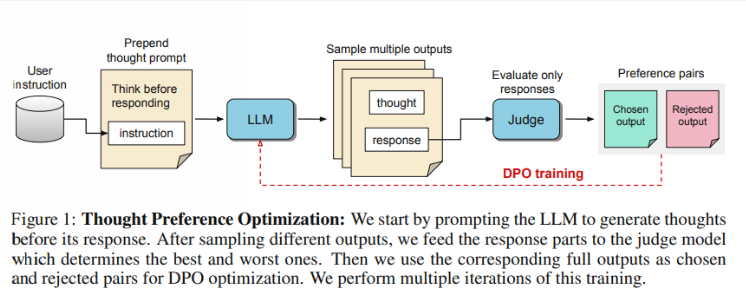
So, how does TPO work? First, the model generates a series of thought steps before answering a question. Next, it creates multiple outputs, which are then evaluated by an evaluation model only on the final answer, not the thought steps themselves. Finally, the model is trained through preference optimization of these evaluation results. The researchers hope that improving the quality of answers can be achieved by improving the thinking process, so that the model can gain more effective reasoning capabilities in implicit learning.
In testing, the Llama38B model using TPO performed better on a general instruction following benchmark than a version without explicit inference. In the AlpacaEval and Arena-Hard benchmarks, TPO's winning rates reached 52.5% and 37.3% respectively. Even more exciting is that TPO is also making progress in areas that typically don’t require explicit thinking, such as common sense, marketing, and health.
However, the research team noted that the current setup is not suitable for mathematical problems, as TPO actually performs worse than the base model on these tasks. This suggests that a different approach may be required for highly specialized tasks. Future research may focus on aspects such as the length control of thought processes and the impact of thinking on larger models.
Highlight:
The research team launched "Thinking Preference Optimization" (TPO), which aims to improve AI's thinking ability in task execution.
? TPO uses assessment models to optimize answer quality by letting the model generate thought steps before answering.
Tests have shown that TPOs perform well in areas such as general knowledge and marketing, but do poorly on math tasks.
All in all, TPO technology provides a new direction for the improvement of large language models, and its potential in improving AI thinking capabilities is worth looking forward to. However, this technology also has limitations, and future research needs to further improve and expand its application scope. The editor of Downcodes will continue to pay attention to the latest developments in this field and bring more exciting reports to readers.