OpenAI has released an eye-catching new model gpt-4o-audio-preview, which has made significant breakthroughs in the field of speech generation and analysis, bringing users a more natural and intelligent voice interaction experience. The editor of Downcodes will take you to have an in-depth understanding of the core functions, application scenarios and pricing strategies of this model, and analyze its potential impact on various industries.
OpenAI once again leads the trend of artificial intelligence technology and launches a new gpt-4o-audio-preview model. This model not only demonstrates amazing capabilities in speech generation and analysis, but also opens up new possibilities for human-computer interaction. Let’s take a closer look at the features of this innovative model and its potential applications.
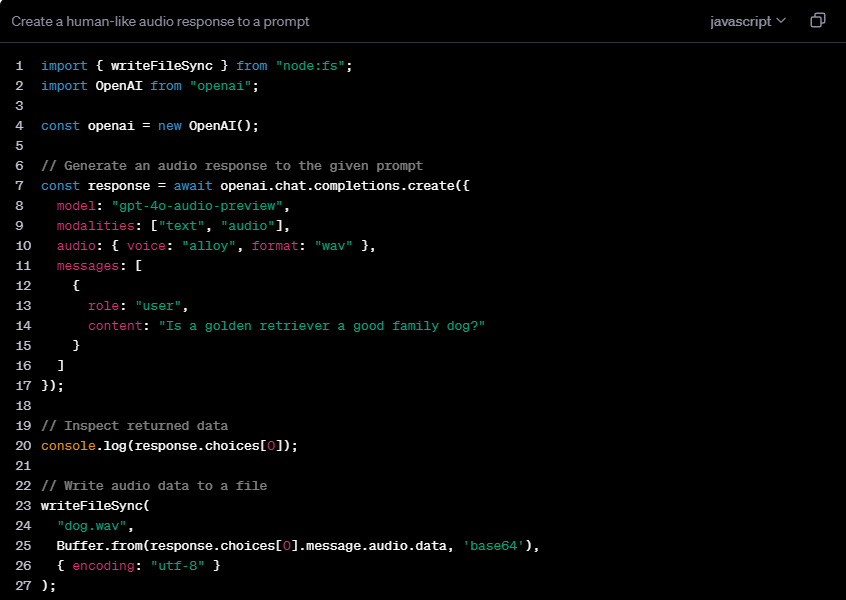
The core functions of gpt-4o-audio-preview include three major aspects: First, it can generate natural and smooth voice responses based on text, providing strong support for applications such as voice assistants and virtual customer service. Secondly, the model has the ability to analyze the emotion, intonation and pitch of audio input, which has broad application prospects in the fields of affective computing and user experience analysis. Finally, it supports voice-to-voice interaction, where audio can be used as both input and output, laying the foundation for a full range of voice interaction systems.
Compared with OpenAI's existing Realtime API, gpt-4o-audio-preview focuses more on the details of speech processing. It excels in speech generation, sentiment analysis, and speech interaction, with a particular focus on processing subtle features such as intonation and emotion. In contrast, Realtime API focuses more on real-time data processing and is suitable for scenarios that require immediate feedback, such as real-time speech-to-text or real-time translation and other continuously interactive applications.
The flexibility of gpt-4o-audio-preview is reflected in its support for multiple mode combinations. Users can select text input to generate text and audio output, or use audio input to obtain text and speech output. In addition, it also supports audio-to-text conversion and mixed input modes, providing developers with rich options.
In terms of pricing, OpenAI adopts a token-based billing model. The price for text input is relatively low at around $5 per million tokens. Text output is slightly higher at around $15 per million tokens. The cost of audio processing is relatively high, with the input costing $100 per million tokens (approximately $0.06 per minute), while the audio output reaches $200 per million tokens (approximately $0.24 per minute). This pricing strategy reflects the complexity and computing resource requirements of audio processing.
The launch of gpt-4o-audio-preview will undoubtedly have a transformative impact on multiple industries. In the field of customer service, it can provide a more natural and emotional voice interaction experience. In the education industry, this technology can be used to develop intelligent language learning assistants to help students improve their pronunciation and intonation. In the entertainment industry, it is expected to drive more realistic speech synthesis and virtual character interaction. In addition, in terms of assistive technology, gpt-4o-audio-preview may provide more accurate speech-to-text services for the hearing-impaired, or provide richer voice descriptions for the visually impaired.
Details: https://platform.openai.com/docs/guides/audio/quickstart
All in all, the emergence of the gpt-4o-audio-preview model marks a new stage in voice artificial intelligence technology. Its powerful functions and wide application prospects will bring revolutionary changes to the future human-computer interaction methods. The editor of Downcodes looks forward to seeing more innovative applications based on this model.