The editor of Downcodes learned that Alibaba Damo Academy and Renmin University of China jointly open sourced a document processing model called mPLUG-DocOwl1.5. The model can understand document content without OCR recognition and performs well in multiple benchmark tests. Its core lies in the "unified structure learning" method, which improves the multi-modal large language model (MLLM)'s structural understanding of rich text images. . The model has publicly released code, models and data sets on GitHub, providing valuable resources for research in related fields.
Alibaba Damo Academy and Renmin University of China recently jointly open sourced a document processing model called mPLUG-DocOwl1.5. This model focuses on understanding document content without OCR recognition, and has achieved results in multiple visual document understanding benchmark tests. leading performance.
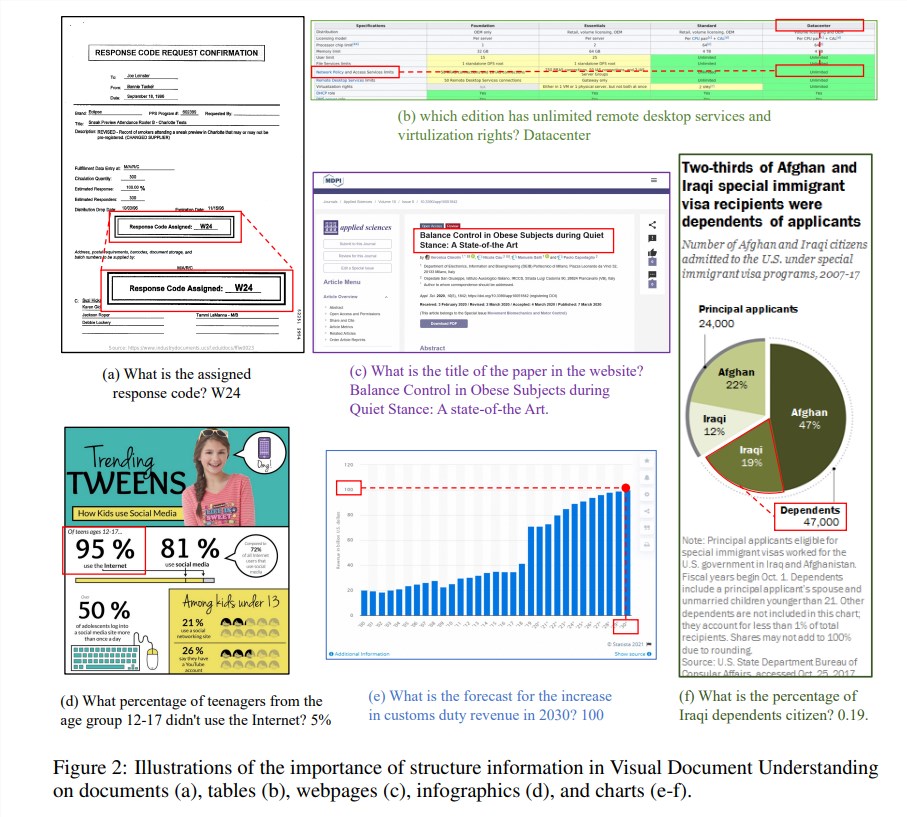
Structural information is crucial for understanding the semantics of text-rich images such as documents, tables, and charts. Although existing multimodal large language models (MLLM) have text recognition capabilities, they lack the ability to understand the general structure of rich text document images. In order to solve this problem, mPLUG-DocOwl1.5 emphasizes the importance of structural information in visual document understanding, and proposes "unified structure learning" to improve the performance of MLLM.
The model's "unified structure learning" covers 5 areas: documents, web pages, tables, charts and natural images, including structure-aware parsing tasks and multi-granularity text positioning tasks. In order to better encode structural information, the researchers designed a simple and effective visual-to-text module H-Reducer, which not only preserves layout information, but also reduces the length of visual features by merging horizontally adjacent image patches through convolution, Enable large language models to understand high-resolution images more efficiently.
In addition, to support structure learning, the research team built DocStruct4M, a comprehensive training set containing 4 million samples based on publicly available datasets, which contains structure-aware text sequences and multi-granularity text bounding box pairs. In order to further stimulate the reasoning capabilities of MLLM in the document field, they also constructed a reasoning fine-tuning data set DocReason25K containing 25,000 high-quality samples.
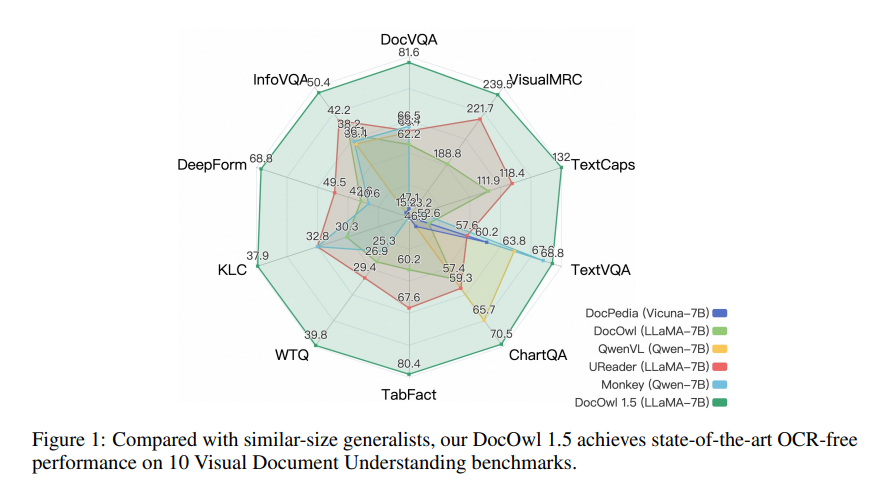
mPLUG-DocOwl1.5 adopts a two-stage training framework, which first performs unified structure learning and then performs multi-task fine-tuning in multiple downstream tasks. Through this training method, mPLUG-DocOwl1.5 achieved state-of-the-art performance in 10 visual document understanding benchmarks, improving the SOTA performance of 7B LLM by more than 10 percentage points in 5 benchmarks.
Currently, the code, model and data set of mPLUG-DocOwl1.5 have been publicly released on GitHub.
Project address: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
Paper address: https://arxiv.org/pdf/2403.12895
The open source of mPLUG-DocOwl1.5 brings new possibilities to the research and application in the field of visual document understanding. Its efficient performance and convenient access methods deserve the attention and use of developers. It is expected that this model can be used in more practical scenarios in the future.