The editor of Downcodes will take you to learn about the latest research results of the Swiss Federal Institute of Technology in Lausanne (EPFL)! This study provides an in-depth comparison of two mainstream adaptive training methods for large language models (LLM): contextual learning (ICL) and instruction fine-tuning (IFT), and uses the MT-Bench benchmark to evaluate the model's ability to follow instructions. The research results show that the two methods have their own merits in different scenarios, providing valuable reference for the selection of LLM training methods.
A recent study from the Ecole Polytechnique Fédérale de Lausanne (EPFL) in Switzerland compared two mainstream adaptive training methods for large language models (LLM): contextual learning (ICL) and instruction fine-tuning (IFT). The researchers used the MT-Bench benchmark to evaluate a model's ability to follow instructions and found that both methods performed better and worse under certain circumstances.
Research has found that when the number of available training samples is small (for example, no more than 50), the effects of ICL and IFT are very close. This suggests that ICL may be an alternative to IFT when data are limited.
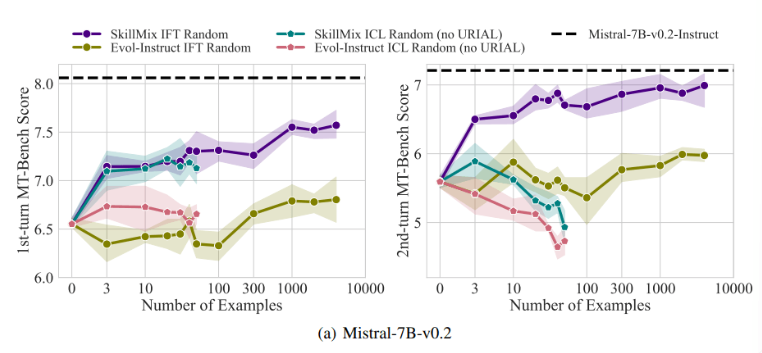
However, as task complexity increases, such as in multi-turn dialogue scenarios, the advantages of IFT become apparent. The researchers believe that the ICL model is prone to overfitting to the style of a single sample, resulting in poor performance when handling complex conversations, or even worse than the base model.
The study also examined the URIAL method, which uses only three samples and instructions to follow rules to train a base language model. Although URIAL has achieved certain results, there is still a gap compared with the model trained by IFT. EPFL researchers improved the performance of URIAL by improving the sample selection strategy, bringing it close to fine-tuning models. This highlights the importance of high-quality training data for ICL, IFT and basic model training.
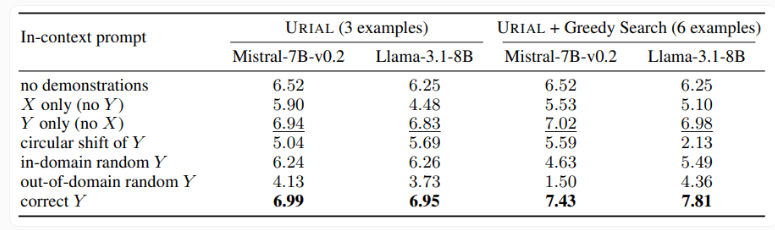
In addition, the study also found that decoding parameters have a significant impact on model performance. These parameters determine how the model generates text and are critical for both basic LLM and models trained with URIAL.
The researchers note that even the base model can follow instructions to a certain extent given suitable decoding parameters.
The significance of this study is that it reveals that contextual learning can quickly and efficiently tune language models, especially when training samples are limited. But for complex tasks such as multi-turn conversations, command fine-tuning is still a better choice.
As the size of the data set increases, the performance of IFT will continue to improve, while the performance of ICL will stabilize after reaching a certain number of samples. The researchers emphasize that the choice between ICL and IFT depends on a variety of factors, such as available resources, data volume, and specific application requirements. Whichever method you choose, high-quality training data is crucial.
All in all, this EPFL study provides new insights into the selection of training methods for large language models and points the way for future research directions. Choosing ICL or IFT requires weighing the pros and cons based on the specific situation, and high-quality data is always the key. We hope this research can help everyone better understand and apply large language models.