The editor of Downcodes will take you to learn about Emu3, the latest multi-modal world model released by Zhiyuan Research Institute! Emu3 relies on its unique "next token prediction" ability to achieve breakthrough understanding and generation capabilities in three modalities: text, image and video. It can not only generate high-quality images and smooth and natural videos, but also perform accurate image understanding and video prediction. Its performance exceeds that of many well-known open source models. The open source nature of Emu3 also injects new vitality into the development of multi-modal AI. Let us explore the technological innovation and future potential behind it.
Zhiyuan Research Institute officially released their new generation multi-modal world model Emu3. The biggest highlight of this model is that it can predict the next token in three different modes: text, image and video. To understand and generate.

In terms of image generation, Emu3 is able to generate high-quality images based on visual token prediction. This means users can expect flexible resolutions and a variety of styles.

In terms of video generation, Emu3 works in a completely new way. Unlike other models that generate videos through noise, Emu3 directly generates videos through sequential prediction. This technological advancement makes video generation smoother and more natural.

On tasks such as image generation, video generation and visual language understanding, Emu3's performance exceeds that of many well-known open source models, such as SDXL, LLaVA and OpenSora. Behind it is a powerful visual tokenizer that can convert videos and images into discrete tokens. This design provides new ideas for unified processing of text, images and videos.
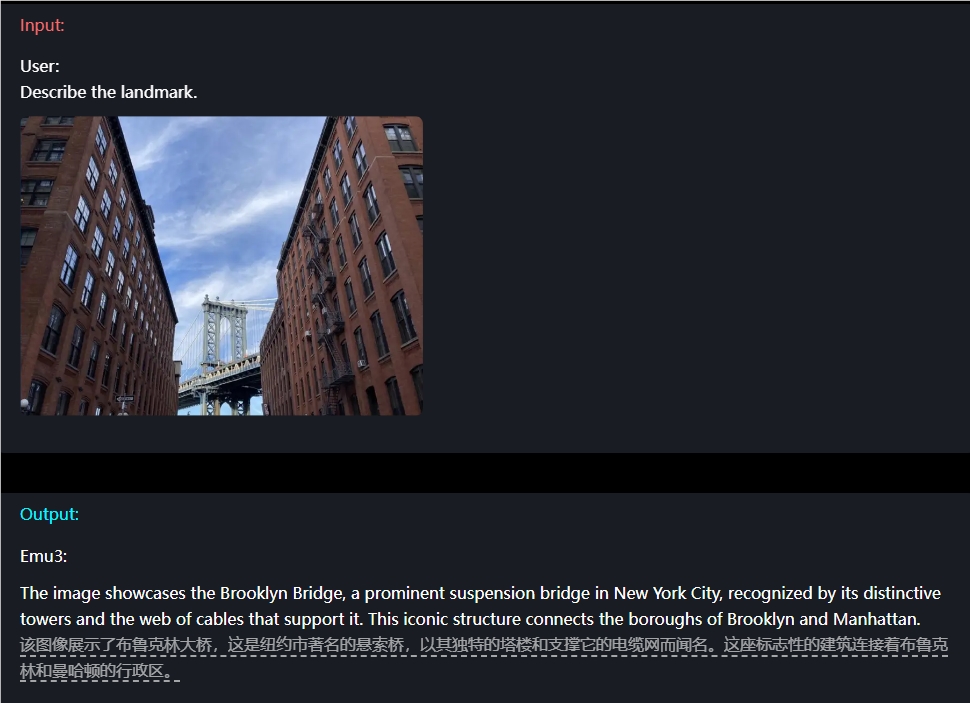
For example, in terms of image understanding, users only need to simply input a question, and Emu3 can accurately describe the image content.
Emu3 also has video prediction capabilities. When given a video, Emu3 can predict what will happen next based on existing content. This enables it to demonstrate strong capabilities in simulating environments, human and animal behaviors, allowing users to experience a more realistic interactive experience.

In addition, Emu3’s design flexibility is refreshing. It can be optimized directly with human preferences so that the generated content is more in line with user expectations. Moreover, Emu3, as an open source model, has attracted heated discussions in the technical community. Many people believe that this achievement will completely change the development pattern of multi-modal AI.
Project URL: https://emu.baai.ac.cn/about
Paper: https://arxiv.org/pdf/2409.18869
Highlight:
Emu3 realizes multi-modal understanding and generation of text, images and videos through prediction of the next token.
On multiple tasks, Emu3's performance surpassed that of many well-known open source models, demonstrating its powerful capabilities.
Emu3's flexible design and open source features provide developers with new opportunities and are expected to promote the innovation and development of multi-modal AI.
The emergence of Emu3 marks a new milestone in the field of multi-modal AI. Its powerful performance, flexible design and open source features will undoubtedly have a profound impact on the future development of AI. We look forward to Emu3 being used in more fields and bringing more convenience and surprises to mankind!