Cohere announced that its most advanced multi-modal AI search model, Embed3, has received a major update and now supports multi-modal search, allowing users to use text and images for enterprise-level retrieval. This update marks a significant advancement in image search for Embed3, allowing enterprises to more effectively mine the value of image data and improve work efficiency and decision-making speed. The editor of Downcodes will take you to have an in-depth understanding of the latest functions and application cases of Embed3.
Cohere has released Embed3, the most advanced multi-modal AI search model - now supporting multi-modal search, which means users can conduct enterprise-level searches not only through text, but also through images.
Since its launch last year, Embed3 has been continuously optimized to help enterprises convert documents into digital representations, and this upgrade will make it even better at image search.
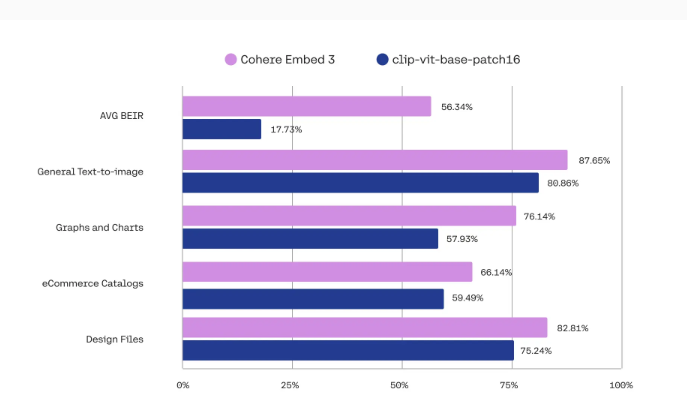
Cohere co-founder and CEO Aidan Gonzales shared a chart of Embed3's performance improvements in image search on social media.
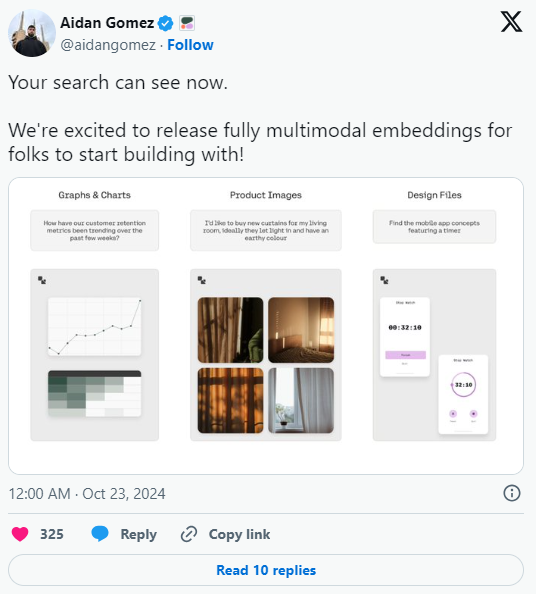
Cohere said in a blog that this new feature will help companies fully mine the massive data stored in images and improve work efficiency. Businesses can search multimodal assets such as complex reports, product catalogs, and design documents more quickly and accurately.
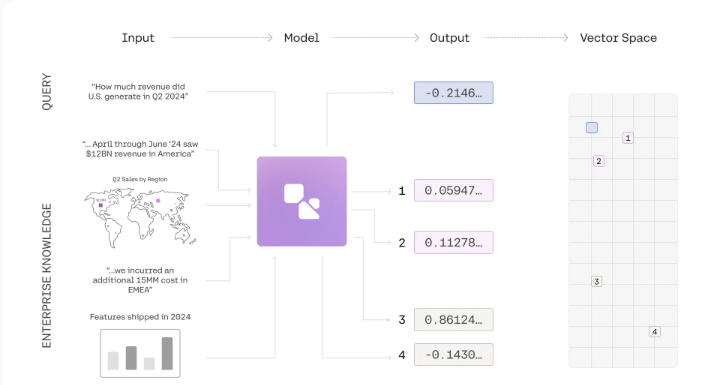
As multi-modal search continues to evolve, Cohere’s Embed3 can generate embeddings of both text and images. This new embedding method enables users to manage images and text in a unified latent space rather than storing them separately. Improvements in this approach will significantly improve the quality of search results, avoid being biased towards text data, and allow for a better understanding of the meaning behind the data.
The following are actual use cases of Embed3:
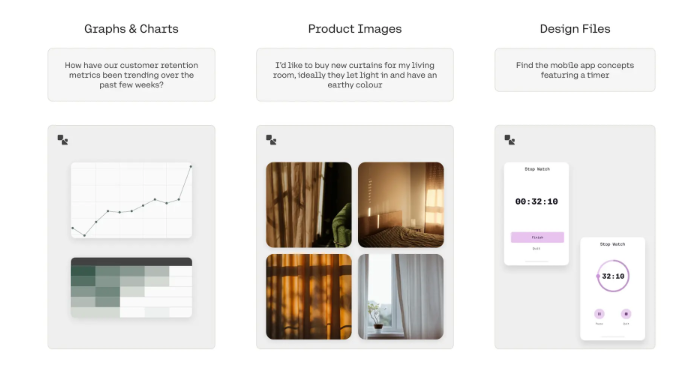
Graphs and charts: Visual representation is key to understanding complex data. Users can now effortlessly find the right charts to inform their business decisions. Simply describe a specific insight and Embed3 will retrieve relevant graphs and charts, allowing employees across teams to make data-driven decisions more efficiently.
E-commerce product catalogs: Traditional search methods often limit customers to finding products through text-based product descriptions. Embed3 changes this search experience. Retailers can build apps that search for product images in addition to text descriptions, creating a differentiated experience for shoppers and increasing conversion rates.
Design files and templates: Designers often work with large asset libraries and rely on memory or strict naming rules to organize visuals. Embed3 makes it easy to find specific UI mockups, visual templates, and presentation slides based on text descriptions. This simplifies the creative process.
Embed3 also supports more than 100 languages , which means it can serve a wider user base. Currently, this multi-modal Embed3 has been launched on Cohere's platform and Amazon SageMaker.
As more and more users become accustomed to image search, and businesses continue to catch up, Cohere's updates give them the opportunity to enjoy a more flexible search experience. Cohere updated its API in September to enable customers to easily switch from competitors' models to Cohere models.
Official blog: https://cohere.com/blog/multimodal-embed-3
Highlight:
Embed3 supports multi-modal search, allowing users to search through images and text.
The updated model significantly improves image search performance and helps enterprises mine the value of data.
? Cohere updated its API in September to simplify the process for customers switching from other models.
All in all, Cohere's Embed3 update brings new possibilities to enterprise-level multi-modal search. Its powerful functions and convenient use experience will help enterprises better utilize data, improve efficiency and make smarter decisions. Interested readers can visit the official blog for more information.