The editor of Downcodes learned that Beijing Zhiyuan Artificial Intelligence Research Institute has joined forces with a number of universities to launch a large model for ultra-long video understanding called Video-XL. The model performs well in processing long videos of more than ten minutes, achieving leading positions in multiple benchmarks, demonstrating strong generalization capabilities and processing efficiency. Video-XL uses language models to compress long visual sequences and achieves nearly 95% accuracy in tasks such as "finding a needle in a haystack". It only needs a graphics card with 80G of video memory to process 2048 frames of input. The open source of this model will promote the cooperation and development of the global multi-modal video understanding research community.
Beijing Zhiyuan Artificial Intelligence Research Institute has joined forces with universities such as Shanghai Jiao Tong University, Renmin University of China, Peking University, and Beijing University of Posts and Telecommunications to launch a large ultra-long video understanding model called Video-XL. This model is an important demonstration of the core capabilities of multi-modal large models and a key step towards general artificial intelligence (AGI). Compared with existing multi-modal large models, Video-XL shows better performance and efficiency when processing long videos of more than 10 minutes.

Video-XL utilizes the native capabilities of language models (LLM) to compress long visual sequences, retains the ability to understand short videos, and shows excellent generalization capabilities in long video understanding. This model ranks first in multiple tasks on multiple mainstream long video understanding benchmarks. Video-XL achieves a good balance between efficiency and performance. It only needs a graphics card with 80G video memory to process 2048 frame input, sample hour-long videos, and achieve nearly 95% in the video "needle in the haystack" task. % accuracy.
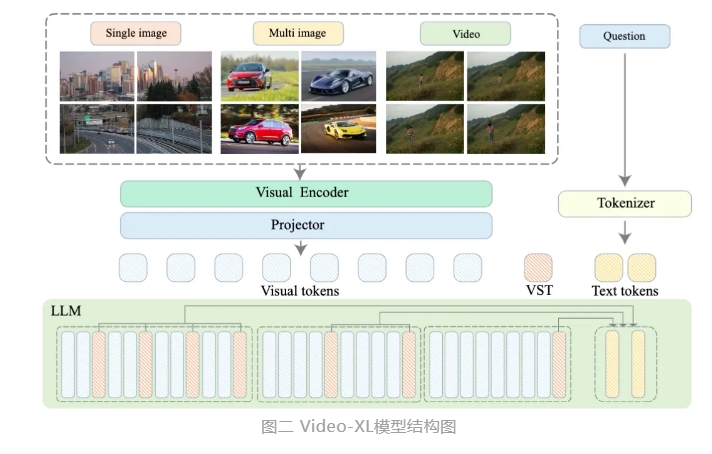
Video-XL is expected to show extensive application value in application scenarios such as movie summarization, video anomaly detection, and ad placement detection, and become a powerful assistant for long video understanding. The launch of this model marks an important step in the efficiency and accuracy of long video understanding technology, and provides strong technical support for the automated processing and analysis of long video content in the future.
Currently, the model code of Video-XL has been open sourced to promote cooperation and technology sharing in the global multi-modal video understanding research community.
Paper title: Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Paper link: https://arxiv.org/abs/2409.14485
Model link: https://huggingface.co/sy1998/Video_XL
Project link: https://github.com/VectorSpaceLab/Video-XL
The open source of Video-XL brings new possibilities to the research and application in the field of long video understanding. Its efficiency and accuracy will promote the further development of related technologies and provide technical support for more application scenarios in the future. We look forward to seeing more innovative applications based on Video-XL in the future.