The editor of Downcodes will introduce you to a latest research from the Technical University of Darmstadt in Germany. This study used the Bongard problem as a test tool to evaluate the performance of the current state-of-the-art AI image model in simple visual reasoning tasks. The research results are surprising. Even the accuracy of top multi-modal models like GPT-4o is far lower than expected, which triggers a deep reflection on the existing AI visual ability evaluation standards.
The latest research from the Technical University of Darmstadt in Germany reveals a thought-provoking phenomenon: even the most advanced AI image models can make significant mistakes when faced with simple visual reasoning tasks. The results of this research put forward new thinking on the evaluation standards of AI visual ability.
The research team used the Bongard problem designed by Russian scientist Michail Bongard as a testing tool. This type of visual puzzle consists of 12 simple images divided into two groups and requires identifying the rules that distinguish the two groups. This abstract reasoning task is not difficult for most people, but the AI model's performance was surprising.
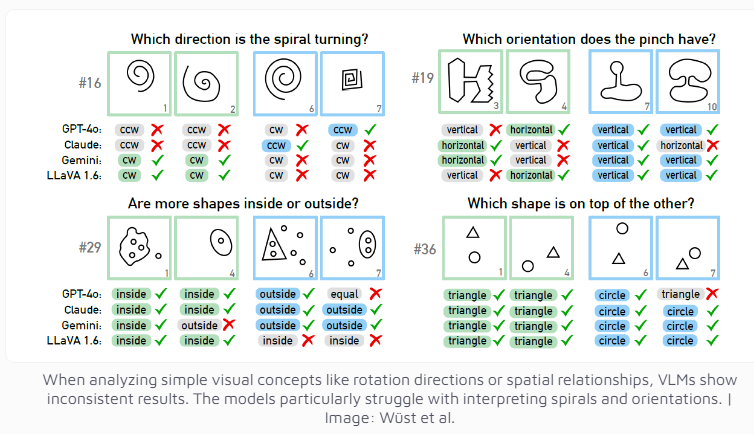
Even the multi-modal model GPT-4o, currently considered the most advanced, successfully solved only 21 out of 100 visual puzzles. The performance of other well-known AI models such as Claude, Gemini and LLaVA is even less satisfactory. These models show significant difficulty in identifying basic visual concepts such as vertical and horizontal lines, or judging the direction of a spiral.
The researchers found that even when multiple choices were provided, the AI model's performance improved only slightly. Only under strict restrictions on the number of possible answers did GPT-4 and Claude improve their success rates to 68 and 69 puzzles respectively. Through in-depth analysis of four specific cases, the research team found that AI systems sometimes have problems at the basic visual perception level before reaching the thinking and reasoning stage, but the specific reasons are still difficult to determine.
This research also triggers reflection on the evaluation criteria of AI systems. The research team pointed out: Why do visual language models perform well on established benchmarks but struggle with the seemingly simple Bongard problem? How meaningful are these benchmarks in assessing real-world reasoning capabilities? These questions are asked , suggesting that the current AI evaluation system may need to be redesigned to more accurately measure AI’s visual reasoning capabilities.
This research not only demonstrates the limitations of current AI technology, but also points the way for the future development of AI visual capabilities. It reminds us that while we cheer for the rapid progress of AI, we must also clearly realize that there is still room for improvement in basic cognitive capabilities of AI.
This research clearly shows that AI models still have a lot of room for improvement in visual reasoning, and more effective evaluation methods and technological breakthroughs are needed in the future to improve AI's cognitive capabilities. The editor of Downcodes will continue to pay attention to the cutting-edge progress in the field of AI and bring you more exciting reports.