Large language models (LLMs) are increasingly widely used, but their huge number of parameters brings huge computing resource requirements. In order to solve this problem and improve the efficiency and accuracy of the model in different resource environments, researchers continue to explore new methods. This article will introduce the Flextron framework jointly developed by researchers from NVIDIA and the University of Texas at Austin. This framework is designed to achieve flexible deployment of AI models without additional fine-tuning and effectively solve the inefficiency problems of traditional methods. The editor of Downcodes will explain in detail the innovations of the Flextron framework and its advantages in resource-constrained environments.
In the field of artificial intelligence, large language models (LLMs) such as GPT-3 and Llama-2 have made significant progress and can accurately understand and generate human language. However, the large number of parameters of these models makes them require a large amount of computing resources during training and deployment, which poses a challenge in resource-limited environments.
Paper entrance: https://arxiv.org/html/2406.10260v1
Traditionally, in order to achieve a balance of efficiency and accuracy under different computing resource constraints, researchers need to train multiple different versions of the model. For example, the Llama-2 model family includes different variants with 7 billion, 1.3 billion and 700 million parameters. However, this method requires a large amount of data and computing resources and is not very efficient.
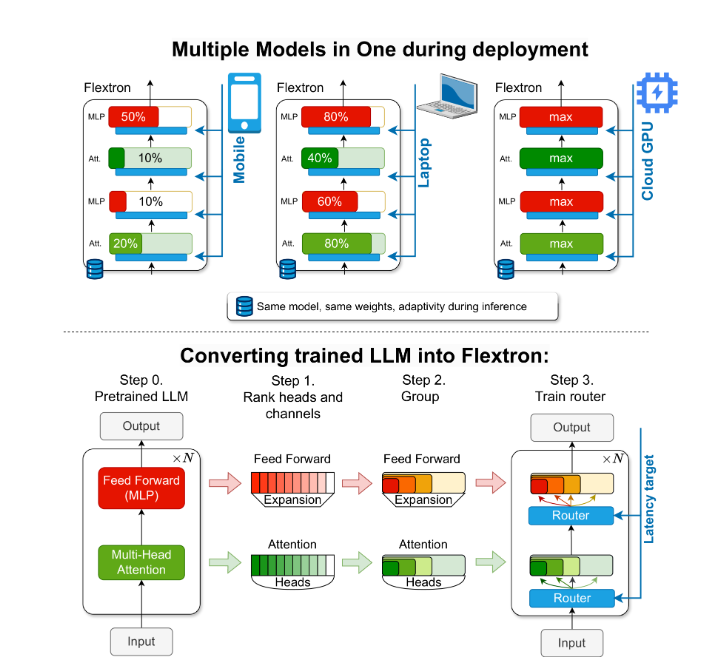
To solve this problem, researchers from NVIDIA and the University of Texas at Austin introduced the Flextron framework. Flextron is a novel flexible model architecture and post-training optimization framework that supports adaptive deployment of models without the need for additional fine-tuning, thus solving the inefficiency issues of traditional methods.
Flextron transforms pre-trained LLM into elastic models through sample-efficient training methods and advanced routing algorithms. This structure features a nested elastic design that allows for dynamic adjustments during inference to meet specific latency and accuracy goals. This adaptability makes it possible to use a single pre-trained model in a variety of deployment scenarios, significantly reducing the need for multiple model variants.
Performance evaluation of Flextron shows that it outperforms in efficiency and accuracy compared to multiple end-to-end trained models and other state-of-the-art elastic networks. For example, Flextron performs well on multiple benchmarks such as ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU, and HellaSwag, using only 7.63% of the training markers in the original pre-training, thus saving a lot of computing resources and time.
The Flextron framework also includes elastic multi-layer perceptron (MLP) and elastic multi-head attention (MHA) layers, further enhancing its adaptability. The elastic MHA layer effectively utilizes available memory and processing power by selecting a subset of attention heads based on input data, and is particularly suitable for scenarios with limited computing resources.
Highlight:
? The Flextron framework supports flexible AI model deployment without additional fine-tuning.
Through efficient sample training and advanced routing algorithms, model efficiency and accuracy are improved.
The elastic multi-head attention layer optimizes resource utilization and is particularly suitable for environments with limited computing resources.
This report hopes to introduce the importance and innovation of the Flextron framework to high school students in an easy-to-understand manner.
All in all, the Flextron framework provides an efficient and innovative solution to the problem of deploying large language models in resource-constrained environments. Its flexible architecture and sample-efficient training method give it significant advantages in practical applications and provide a new direction for the further development of artificial intelligence technology. The editor of Downcodes hopes that this article can help everyone better understand the core ideas and technical contributions of the Flextron framework.