The editor of Downcodes will take you to learn about an innovative technology that improves the efficiency of large language models (LLMs) - Q-Sparse. The powerful natural language processing capabilities of LLMs have attracted much attention, but their high computational cost and memory footprint have always been bottlenecks in practical applications. Q-Sparse uses a clever sparsification method to significantly improve the inference efficiency while ensuring model performance, paving the way for the widespread application of LLMs. This article will deeply explore the core technology, advantages and experimental verification results of Q-Sparse, showing its huge potential in improving the efficiency of LLMs.
In the world of artificial intelligence, large language models (LLMs) are known for their superior natural language processing capabilities. However, the deployment of these models in practical applications faces huge challenges, mainly due to their high computational cost and memory footprint during the inference stage. To solve this problem, researchers have been exploring how to improve the efficiency of LLMs. Recently, a method called Q-Sparse has attracted widespread attention.
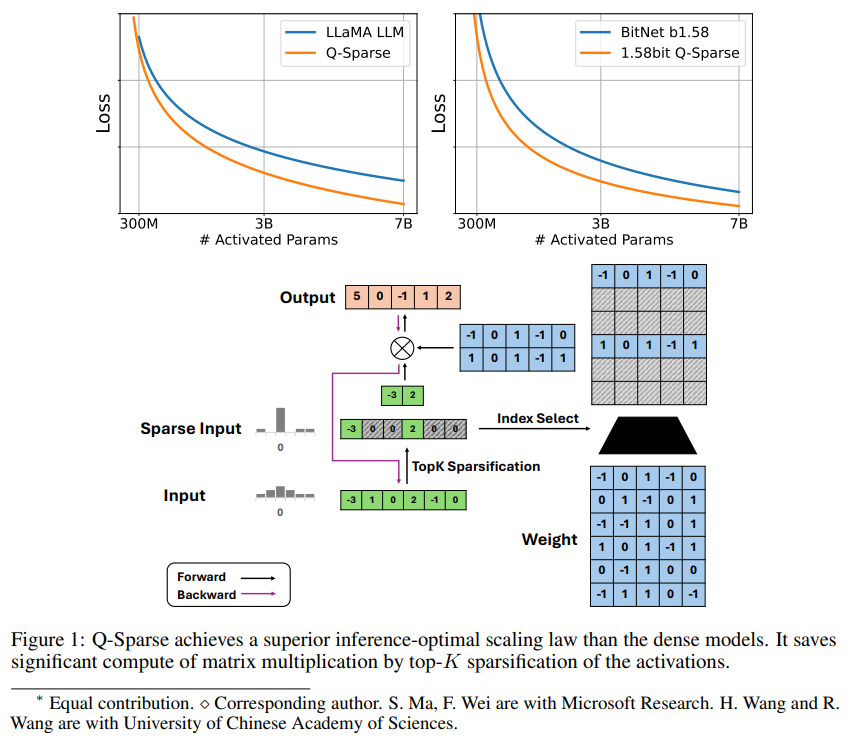
Q-Sparse is a simple but effective method that achieves fully sparse activation of LLMs by applying top-K sparsification in activations and a pass-through estimator in training. This means significant improvements in efficiency when inferring. Key research results include:
Q-Sparse achieves higher inference efficiency while maintaining comparable results to baseline LLMs.
An inferential optimal expansion rule suitable for sparse activation LLMs is proposed.
Q-Sparse works in different settings, including training from scratch, continued training of off-the-shelf LLMs, and fine-tuning.
Q-Sparse works with full precision and 1-bit LLMs (e.g. BitNet b1.58).
Advantages of sparse activation
Sparsity improves the efficiency of LLMs in two ways: first, sparsity can reduce the amount of calculation of matrix multiplication, because zero elements will not be calculated; second, sparsity can reduce the amount of input/output (I/O) transmission, which It is the main bottleneck in the inference phase of LLMs.
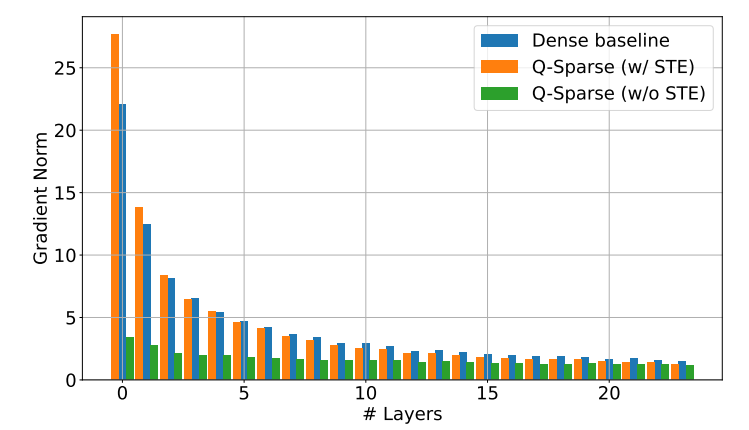
Q-Sparse achieves full sparsity of activations by applying a top-K sparsification function in each linear projection. For backpropagation, the gradient of the activation is calculated using a pass-through estimator. In addition, the squared ReLU function is introduced to further improve the sparsity of activation.
Experimental verification
The researchers studied the expansion law of sparsely activated LLMs through a series of expansion experiments and came to some interesting findings:
The performance of sparse activation models improves with increasing model size and sparsity ratio.
Given a fixed sparsity ratio S, the performance of a sparse activation model scales with the model size N in a power-law manner.
Given a fixed parameter N, the performance of the sparse activation model scales exponentially with the sparsity ratio S.
Q-Sparse can be used not only for training from scratch, but also for continued training and fine-tuning of off-the-shelf LLMs. In the continue training and fine-tuning settings, the researchers used the same architecture and training process as training from scratch, the only difference was to initialize the model with pre-trained weights and enable sparse functions to continue training.
Researchers are exploring using Q-Sparse with 1-bit LLMs (such as BitNet b1.58) and mixed experts (MoE) to further improve the efficiency of LLMs. Additionally, they are working on making Q-Sparse compatible with batch mode, which will provide more flexibility for training and inference of LLMs.
The emergence of Q-Sparse technology provides new ideas for solving the efficiency problem of LLMs. It has great potential in reducing computing costs and memory usage, and is expected to promote the application of LLMs in more fields. It is believed that more research results based on Q-Sparse will emerge in the future to further improve the performance and efficiency of LLMs.