In recent years, multimodal large models have developed rapidly, and many excellent models have emerged. However, most existing models rely on visual encoders, which suffer from visual induction bias problems caused by training separation, limiting efficiency and performance. The editor of Downcodes brings you a new visual language model EVE launched by Zhiyuan Research Institute in conjunction with universities. It adopts a coder-less architecture and has achieved excellent results in multiple benchmark tests, providing new opportunities for the development of multi-modal models. ideas.
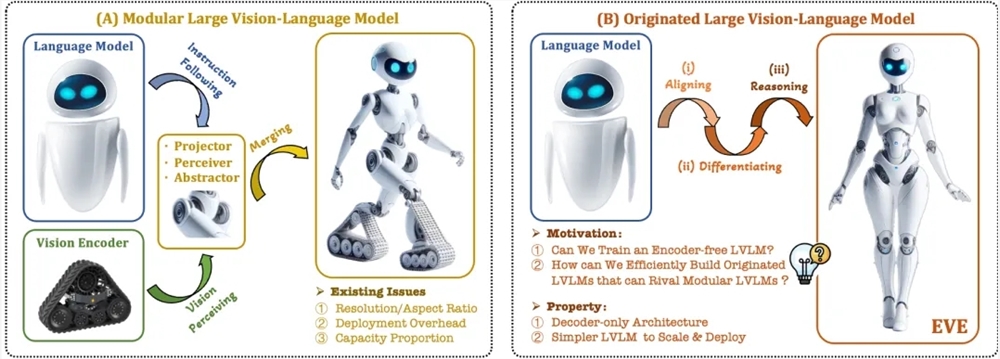
Recently, significant progress has been made in the research and application of multimodal large models. Foreign companies such as OpenAI, Google, Microsoft, etc. have launched a series of advanced models, and domestic institutions such as Zhipu AI and Step Star have made breakthroughs in this field. These models usually rely on visual encoders to extract visual features and combine them with large language models, but there is a visual induction bias problem caused by training separation, which limits the deployment efficiency and performance of multi-modal large models.
In order to solve these problems, Zhiyuan Research Institute, together with Dalian University of Technology, Peking University and other universities, launched a new generation of coder-free visual language model EVE. EVE integrates visual-linguistic representation, alignment and inference into a unified pure decoder architecture through refined training strategies and additional visual supervision. Using public data, EVE performs well on multiple visual-linguistic benchmarks, approaching or even outperforming mainstream encoder-based multi-modal methods.
Key features of EVE include:
Native visual language model: removes the visual encoder and handles any image aspect ratio, which is significantly better than the same type of Fuyu-8B model.
Low data and training costs: Pre-training uses public data such as OpenImages, SAM and LAION, and the training time is short.
Transparent and efficient exploration: Provides an efficient and transparent development path for native multi-modal architectures of pure decoders.
Model structure:
Patch Embedding Layer: Obtain the 2D feature map of the image through a single convolution layer and an average pooling layer to enhance local features and global information.
Patch Aligning Layer: Integrate multi-layer network visual features to achieve fine-grained alignment with the visual encoder output.
Training strategy:
Pre-training stage guided by large language models: establishing the initial connection between vision and language.
Generative pre-training stage: Improve the model’s ability to understand visual-linguistic content.
Supervised fine-tuning phase: regulates the model’s ability to follow language instructions and learn conversational patterns.
Quantitative analysis: EVE performs well in multiple visual language benchmarks and is comparable to a variety of mainstream encoder-based visual language models. Despite challenges in accurately responding to specific instructions, through an efficient training strategy, EVE achieves performance comparable to visual language models with encoder bases.
EVE has demonstrated the potential of encoder-less native visual language models. In the future, it may continue to promote the development of multi-modal models through further performance improvements, optimization of encoder-less architectures, and the construction of native multi-modal models.
Paper address: https://arxiv.org/abs/2406.11832
Project code: https://github.com/baaivision/EVE
Model address: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
All in all, the emergence of the EVE model provides new directions and possibilities for the development of multi-modal large models. Its efficient training strategy and excellent performance deserve attention. We look forward to the future EVE model being able to demonstrate its powerful capabilities in more fields.