Recently, Tencent Artificial Intelligence Laboratory launched a new model called VTA-LDM, which is designed to efficiently convert video content into semantically and temporally consistent audio. The core technology of this model lies in "implicit alignment", which perfectly matches the generated audio and video content, greatly improving the quality and application scenarios of audio generation. The editor of Downcodes will take you to have an in-depth understanding of the innovations and application prospects of the VTA-LDM model.
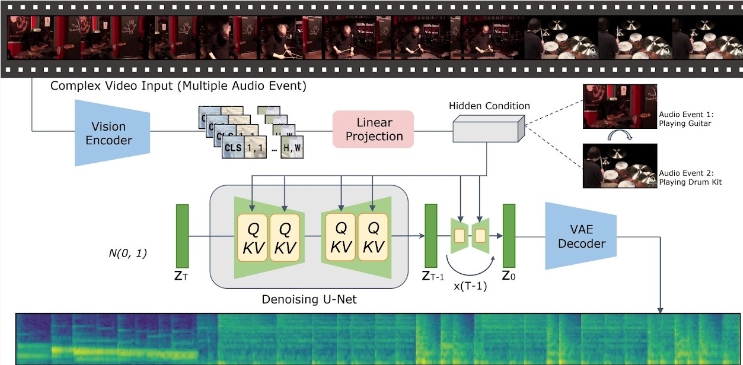
With the significant progress in text-to-video generation technology, how to generate semantically and temporally consistent audio content from video input has become a hot topic among researchers. Recently, the research team of Tencent Artificial Intelligence Laboratory launched a new model called "Implicitly Aligned Video to Audio Generation" - VTA-LDM, which aims to provide efficient audio generation solutions.
Project entrance: https://top.aibase.com/tool/vta-ldm
The core idea of the VTA-LDM model is to match the generated audio and video content semantically and temporally through implicit alignment technology. This method not only improves the quality of audio generation, but also expands the application scenarios of video generation technology. The research team conducted in-depth exploration on model design and combined a variety of technical means to ensure the accuracy and consistency of the generated audio.
The research focuses on three key aspects: visual encoders, auxiliary embeddings and data augmentation techniques. The research team first established a basic model and conducted a large number of ablation experiments on this basis to evaluate the impact of different visual encoders and auxiliary embeddings on the generation effect. The results of these experiments show that the model performs well in terms of generation quality and simultaneous alignment of video and audio, reaching the forefront of current technology.
In terms of inference, users only need to put the video clips into the specified data directory and run the provided inference script to generate the corresponding audio content. The research team also provides a set of tools to help users merge the generated audio with the original video, further improving the convenience of the application.
The VTA-LDM model currently provides multiple different model versions to meet different research needs. These models cover basic models and a variety of enhanced models, aiming to provide users with flexible choices to adapt to various experiments and application scenarios.
The launch of the VTA-LDM model marks an important progress in the field of video to audio generation. Researchers hope to use this model to promote the development of related technologies and create richer application possibilities.
## Highlights:
The emergence of the VTA-LDM model has brought new breakthroughs to the field of video and audio generation. Its efficient and convenient operation methods and powerful functions herald a wider application prospect in the future. It is believed that with the continuous development of technology, the VTA-LDM model will play an important role in more fields.