Downcodes editor brings big news! The revolutionary Transformer acceleration technology FlashAttention-3 is officially released! This technology will revolutionize the inference speed and cost of large language models (LLMs), achieving unprecedented efficiency improvements. The speed is increased by 1.5 to 2 times, low-precision (FP8) operation maintains high accuracy, and long text processing capabilities are significantly enhanced, which will bring new possibilities for AI applications! Let’s take a closer look at this breakthrough technology.
The new Transformer acceleration technology FlashAttention-3 has been released! This is not just an upgrade, it heralds a sharp increase in the inference speed and a plummeting cost of our large language models (LLMs)!
Let’s talk about this FlashAttention-3 first. Compared with the previous version, it is simply a shotgun change:
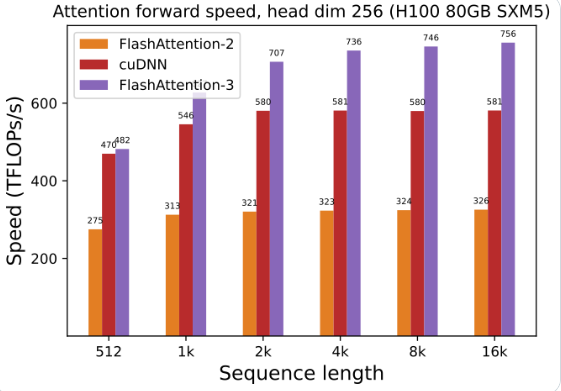
GPU utilization has been greatly improved: using FlashAttention-3 to train and run large language models, the speed is directly doubled, 1.5 to 2 times faster. This efficiency is amazing!
Low precision, high performance: It can also run with low precision numbers (FP8) while maintaining accuracy. What does this mean? Lower cost without compromising performance!
Processing long texts is a piece of cake: FlashAttention-3 greatly enhances the AI model's ability to process long texts, which was unimaginable before.
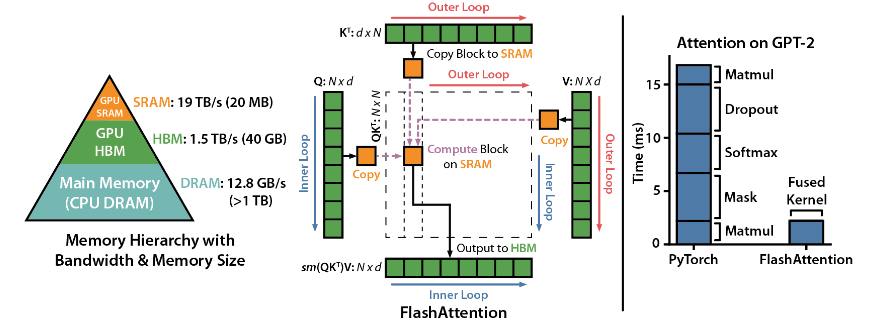
FlashAttention is an open source library developed by Dao-AILab. It is based on two heavyweight papers and provides an optimized implementation of the attention mechanism in deep learning models. This library is particularly suitable for processing large-scale data sets and long sequences. There is a linear relationship between memory consumption and sequence length, which is far more efficient than the traditional quadratic relationship.
Technical Highlights:
Advanced technology support: local attention, deterministic backpropagation, ALiBi, etc. These technologies bring the model's expressive power and flexibility to a higher level.
Hopper GPU optimization: FlashAttention-3 has specially optimized its support for Hopper GPU, and the performance has been improved by more than one and a half points.
Easy to install and use: supports CUDA11.6 and PyTorch1.12 or above, easy to install with pip command under Linux system. Although Windows users may need more testing, it is definitely worth trying.
Core functions:
Efficient performance: The optimized algorithm greatly reduces computing and memory requirements, especially for long sequence data processing, and the performance improvement is visible to the naked eye.
Memory optimization: Compared with traditional methods, FlashAttention consumes less memory, and the linear relationship makes memory usage no longer a problem.
Advanced features: Integrating a variety of advanced technologies greatly improves model performance and application scope.
Ease of use and compatibility: Simple installation and usage guide, coupled with support for multiple GPU architectures, allow FlashAttention-3 to be quickly integrated into a variety of projects.
Project address: https://github.com/Dao-AILab/flash-attention
The emergence of FlashAttention-3 will undoubtedly accelerate the application and development of large-scale language models and bring new breakthroughs to the field of artificial intelligence. Its efficient performance and ease of use make it an ideal choice for developers. Hurry up and experience it!