The editor of Downcodes will reveal the truth about visual language models (VLMs) with you! Do you think VLMs can "understand" images like humans? The truth is not that simple. This article will deeply explore the limitations of VLMs in image understanding, and through a series of experimental results, show the huge gap between them and human visual capabilities. Are you ready to overturn your understanding of VLMs?
Everyone should have heard of visual language models (VLMs). These little experts in the AI field can not only read text, but also "see" pictures. But this is not the case. Today, let’s take a look at their “underpants” to see if they can really “see” and understand images like us humans.
First of all, I have to give you some popular science about what VLMs are. To put it simply, they are large language models, such as GPT-4o and Gemini-1.5Pro, which perform very well in image and text processing, and even achieve high scores in many visual understanding tests. But don’t let these high scores fool you, today we’re going to see if they’re really that awesome.
The researchers designed a set of tests called BlindTest, which contains seven tasks that are extremely simple for humans. For example, determine whether two circles overlap, whether two lines intersect, or count how many circles there are in the Olympic logo. Does it sound like these tasks can be easily handled by kindergarten children? But let me tell you, the performance of these VLMs is not that impressive.
The results are shocking. The average accuracy of these so-called advanced models on BlindTest is only 56.20%, and the best Sonnet-3.5 has an accuracy of 73.77%. This is like a top student who claims to be able to get into Tsinghua University and Peking University, but turns out he can't even do elementary school math questions correctly.

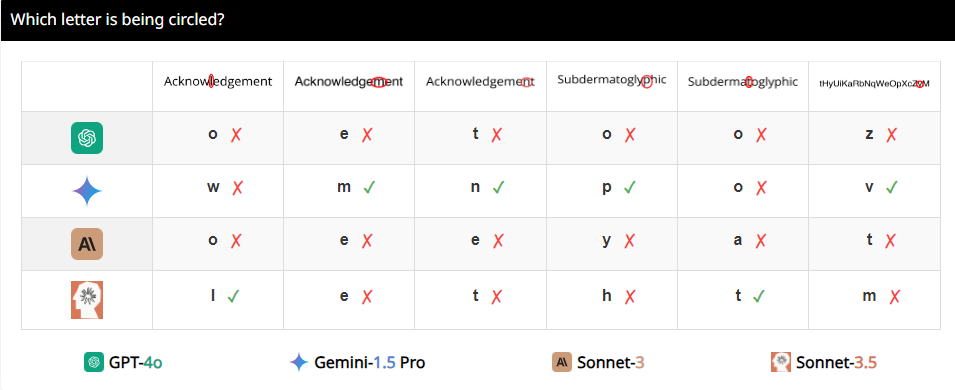
Why is this happening? Researchers analyzed that it may be because VLMs are like myopia when processing images and cannot see details clearly. Although they can roughly see the overall trend of the image, when it comes to precise spatial information, such as whether two graphics intersect or overlap, they are confused.
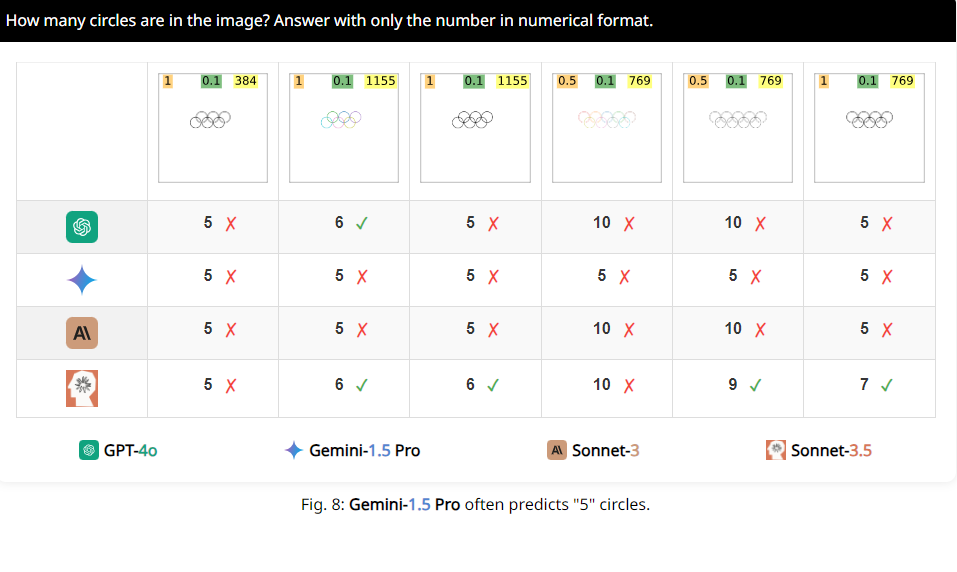
For example, the researchers asked VLMs to determine whether two circles overlapped, and found that even if the two circles were as big as watermelons, these models still could not answer the question 100% accurately. Also, when asked to count the number of circles in the Olympic logo, their performance is hard to describe.
More interestingly, the researchers also found that these VLMs seemed to have a special preference for the number 5 when counting. For example, when the number of circles in the Olympic logo exceeds 5, they tend to answer "5". This may be because there are 5 circles in the Olympic logo and they are particularly familiar with this number.
Okay, having said all that, do you guys have a new understanding of these seemingly tall VLMs? In fact, they still have many limitations in visual understanding, far from reaching our human level. So, next time you hear someone say that AI can completely replace humans, you can laugh.
Paper address: https://arxiv.org/pdf/2407.06581
Project page: https://vlmsareblind.github.io/
In summary, although VLMs have made significant progress in the field of image recognition, their capabilities in precise spatial reasoning still have major shortcomings. This study reminds us that the evaluation of AI technology cannot rely solely on high scores, but also requires a deep understanding of its limitations to avoid blind optimism. We look forward to VLMs making breakthroughs in visual understanding in the future!