The editor of Downcodes will take you to learn about a breakthrough research by Google DeepMind: Mixture of Experts (MoE). This research has made revolutionary progress in the Transformer architecture. Its core lies in a parameter-efficient expert retrieval mechanism that uses product key technology to balance the computational cost and the number of parameters, thus greatly improving the model potential while maintaining efficiency. This research not only explores extreme MoE settings, but also proves for the first time that the learning index structure can be effectively routed to more than one million experts, bringing new possibilities to the field of AI.
The million-expert Mixture model proposed by Google DeepMind is a research that has taken revolutionary steps in the Transformer architecture.
Imagine a model that can perform sparse retrieval from a million micro-experts. Does this sound a bit like the plot of a science fiction novel? But that’s exactly what DeepMind’s latest research shows. The core of this research is a parameter-efficient expert retrieval mechanism that utilizes product key technology to decouple the computational cost from the parameter count, thereby releasing the greater potential of the Transformer architecture while maintaining computational efficiency.
The highlight of this work is that it not only explores extreme MoE settings, but also demonstrates for the first time that a learned index structure can be efficiently routed to over a million experts. This is like quickly finding a few experts who can solve the problem in a huge crowd, and all this is done under the premise of controllable computing costs.
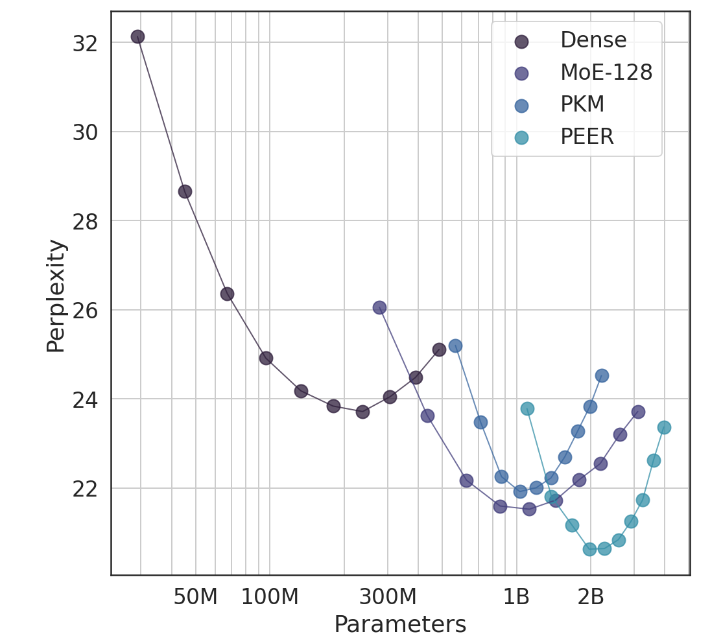
In experiments, the PEER architecture demonstrated superior computing performance and was more efficient than dense FFW, coarse-grained MoE, and product key memory (PKM) layers. This is not only a theoretical victory, but also a huge leap in practical application. Through the empirical results, we can see the superior performance of PEER in language modeling tasks. It not only has lower perplexity, but also in the ablation experiment, by adjusting the number of experts and the number of active experts, the performance of the PEER model has been significantly improved. .
The author of this study, Xu He (Owen), is a research scientist at Google DeepMind. His single-handed exploration has undoubtedly brought new revelations to the field of AI. As he showed, through personalized and intelligent methods, we can significantly improve conversion rates and retain users, which is especially important in the AIGC field.
Paper address: https://arxiv.org/abs/2407.04153
All in all, Google DeepMind's million-expert hybrid model research provides new ideas for the construction of large-scale language models. Its efficient expert retrieval mechanism and excellent experimental results indicate great potential for future AI model development. The editor of Downcodes looks forward to more similar breakthrough research results!