The editor of Downcodes learned that Chinese scholars from Georgia Institute of Technology and NVIDIA have proposed an innovative fine-tuning framework called RankRAG, which significantly simplifies the complex process of retrieval enhancement generation (RAG). RankRAG fine-tunes a single large language model (LLM) to simultaneously undertake the tasks of retrieval, ranking, and generation, thereby greatly improving performance and efficiency and achieving experimental results that are superior to existing open source models. This breakthrough technology brings new possibilities for the application of AI in various fields.
Recently, two Chinese scholars from Georgia Institute of Technology and NVIDIA proposed a new fine-tuning framework called RankRAG. This framework greatly simplifies the original complex RAG pipeline and uses the fine-tuning method to allow the same LLM to complete retrieval, ranking and generation tasks. , which also resulted in a substantial improvement in performance.

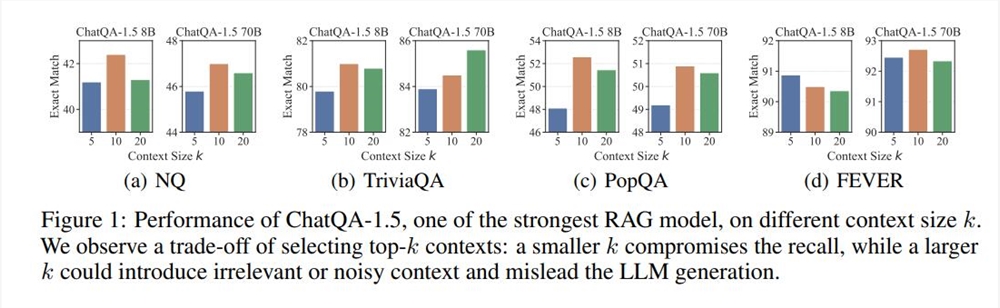
RAG (Retrieval-Augmented Generation) is a commonly used technology in LLM deployment, and is particularly suitable for text generation tasks that require a large amount of factual knowledge. Generally, the process of RAG is: a dense model based on text encoding retrieves top-k text segments from an external database, and then LLM reads and generates them. This process has been widely used, but it also has limitations, such as k value selection. If the k value is too large, even LLM that supports long context will have difficulty processing it quickly; if the k value is too small, a high-recall retrieval mechanism is required, and existing retrievers and ranking models have their own shortcomings.
Based on the above problems, the RankRAG framework puts forward a new idea: expand LLM capabilities through fine-tuning and let LLM complete retrieval and ranking by itself. Experimental results show that this method not only improves data efficiency, but also significantly enhances model performance. Especially on multiple general benchmarks and biomedical knowledge-intensive benchmarks, the Llama38B/70B model fine-tuned by RankRAG surpassed the ChatQA-1.58B and ChatQA-1.570B models respectively.
The key to RankRAG is its high degree of interactivity and editability. Users can not only view AI-generated content in real time, but also edit and iterate directly on the interface. This instant feedback mechanism greatly improves work efficiency and makes AI truly a powerful assistant in the creative process. What’s even more exciting is that this update makes these Artifacts no longer limited to the Claude platform, and users can easily share them anywhere.
This innovation of the RankRAG fine-tuning framework also includes two stages of instruction fine-tuning. The first stage is supervised fine-tuning (SFT), which mixes multiple data sets to improve LLM's instruction following ability. The second-stage fine-tuning data set contains a variety of QA data, retrieval-enhanced QA data, and contextual ranking data to further enhance LLM’s retrieval and ranking capabilities.
In experiments, RankRAG consistently outperforms the current open source SOTA model ChatQA-1.5 on nine general domain datasets. Especially in challenging QA tasks, such as long-tail QA and multi-hop QA, RankRAG improves performance by more than 10% over ChatQA-1.5.
Overall, RankRAG not only performs well in retrieval and generation tasks, but also demonstrates its strong adaptability on the biomedical RAG benchmark Mirage. Even without fine-tuning, RankRAG outperforms many open source models in specialized fields on medical question answering tasks.
With the introduction and continuous improvement of the RankRAG framework, we have reason to believe that the future of collaborative creation between AI and humans will be brighter. Both independent developers and researchers can use this innovative framework to inspire more ideas and possibilities and promote the development of technology and applications.
Paper address: https://arxiv.org/abs/2407.02485
The emergence of the RankRAG framework heralds another leap forward for large-scale language models in the fields of information retrieval and text generation. Its efficient, simple design and excellent performance will undoubtedly provide new directions and motivation for the development of AI technology in the future. We look forward to RankRAG showing its strong potential in more fields!