In recent years, innovations in large language models (LLM) have emerged one after another, constantly challenging the limits of existing architectures. The editor of Downcodes learned that researchers from Stanford, UCSD, UC Berkeley and Meta jointly proposed a new architecture called TTT (Test-Time-Training layers). With its breakthrough design, it is expected to completely change our understanding of language. How the model is recognized and applied. By cleverly combining the advantages of RNN and Transformer, the TTT architecture significantly improves the expressive ability of the model while ensuring linear complexity. It performs particularly well when processing long texts, bringing new insights to fields such as long video modeling. possibility.
In the world of AI, change always comes unexpectedly. Just recently, a new architecture called TTT emerged. It was jointly proposed by researchers from Stanford, UCSD, UC Berkeley and Meta. It subverted Transformer and Mamba overnight and brought revolutionary changes to language models.
TTT, the full name of Test-Time-Training layers, is a brand-new architecture that compresses context through gradient descent and directly replaces the traditional attention mechanism. This approach not only improves efficiency, but also unlocks a linear complexity architecture with expressive memory, allowing us to train LLMs containing millions or even billions of tokens in context.

The proposal of the TTT layer is based on deep insights into the existing RNN and Transformer architectures. Although RNN is highly efficient, it is limited by its expressive ability; while Transformer has strong expressive ability, but its computational cost increases linearly with the context length. The TTT layer cleverly combines the advantages of both, maintaining linear complexity and enhancing expressive capabilities.
In experiments, both variants, TTT-Linear and TTT-MLP, demonstrated excellent performance, outperforming Transformer and Mamba in both short and long contexts. Especially in long context scenarios, the advantages of the TTT layer are more obvious, which provides huge potential for application scenarios such as long video modeling.
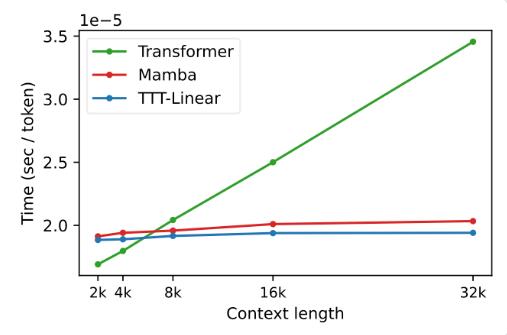
The proposal of the TTT layer is not only innovative in theory, but also shows great potential in practical applications. In the future, the TTT layer is expected to be applied to long video modeling to provide richer information by densely sampling frames. This is a burden for the Transformer, but it is a blessing for the TTT layer.
This research is the result of five years of hard work by the team and has been brewing since Dr. Yu Sun’s postdoctoral period. They persisted in exploring and trying, and finally achieved this breakthrough result. The success of the TTT layer is the result of the team’s unremitting efforts and innovative spirit.
The advent of the TTT layer has brought new vitality and possibilities to the AI field. It not only changes our understanding of language models, but also opens up a new path for future AI applications. Let us look forward to the future application and development of the TTT layer and witness the progress and breakthroughs of AI technology.
Paper address: https://arxiv.org/abs/2407.04620
The emergence of the TTT architecture has undoubtedly injected a boost into the AI field. Its breakthrough progress in long text processing indicates that future AI applications will have more powerful processing capabilities and broader application prospects. Let’s wait and see how the TTT architecture will further change our world.